北京时间2020年5月14日,GTC 2020 Keynote上nVIDIA公司发布了一系列的硬件产品和软件平台或者解决方案;
NVIDIA Tesla Ampere SXM A100 GPU
- Peak FP 64 9.7TFLOPS
- 108个SM,每个SM包含32个FP64的计算单元,因此一个A100有108*32=3456个FP64;
- boost频率是1410MHz;
- 那么双精度浮点运算性能=1410MHz*3456个*2/1000=9754.92GFLOPs=9.7TFLPs;
- https://devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
- GPU Memory 40GB,Memory Bandwidth 1555GB/s
- Data Rate 是1215MHz DDR
- 一共是5颗8GB的HBM2,位宽是1024bit
- 那么带宽就是:1215MHz*2DDR*1024bit*5HBM2/8/1000=1555.2GB/s;
- https://devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
- NVLink 600GB/s
- NVLink 3.0,有12个link,相对于NVLink2.0只有6个Link;
- 1个Link有8in+8out的25GT/s的lans
- 那么1个Link的速度是(8+8)*25GT/s/8=50GB/s;
- NVLink3的双向的带宽就是12*50GB/s=600GB/s;
- https://www.nvidia.com/en-us/data-center/nvlink/
- 每个NVSwitch连接了进入8个lans,出去8个lans,那么N个nvswitch的贷款是,N*600GB/s;
- PCIe Gen 4 64GB/s
- SXM TDP 400W
- MIG也是新引入的功能,可以将A100 GPU最多切分成7个计算实例,SM相互独立,L2 Cache和Mem都是切分的;
TF32可以实现和FP32相同的范围,和FP16相同的精度;
- TF32实现了和FP32相同的取值范围,但是保留和FP16相同的精度范围。整体需要19bit表示一个数。
- BF16实现了和FP32相同的取值范围,但是精度相对FP16还要低,但是AI中一般都没问题。整体需要16bit表示一个数。
- 这两个都是加速神经网络计算产生的非标准的数字表示方法。
- BF16 Brain Floating Point Format 是Google发起的,在Google的TPU上和Intel的CPU或者FPGA上都有实现;
- TF32 Tensor Floating Point Format 是NVIDIA2020年发布并在Ampere上实现的;
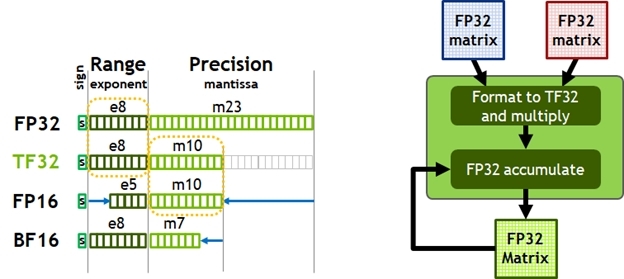
- 这样的话其实A*B这两个矩阵都可以是FP32的矩阵了,相对于FP16范围更大了一些,精度降低是可以接受的,并且A*B+C中的C是FP32的,最后得到的矩阵还是FP32的;
- https://devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
有意思的事情是这一代好像不提Tesla了;之前一直是注册的R的状态,是转变不了Trade Mark的意思么。现在使用Data Center代替了。这样的话连续性丢失了。
Keynote的地址:https://www.nvidia.com/en-us/gtc/keynote/
Ampere Arch的白皮书:https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf