我从Intel的微信的公众号了解到这个系列,这上面的有汉化的字幕;
第一部分:https://mp.weixin.qq.com/s/27dwNmoc5GNgiIq1-jNMpQ
第二部分:https://mp.weixin.qq.com/s/RZIUgxLc8EHyyVIorkGY2Q
在Intel的官网上也找到了相关的主页:https://www.intel.com/content/www/us/en/architecture-and-technology/architecture-all-access.html
这个系列可以翻译为架构全解:创新之旅
在主页的下面可以跳转到Intel的六大技术支柱的主页:https://www.intel.com/content/www/us/en/silicon-innovations/silicon-innovations-technology.html
分别是:
- Innovations in Process and Packaging 在处理器和封装中的创新
- Diverse Architectures. Unprecedented Choice. 变化的架构,全新的选择;
- Redefining the Memory and Storage Hierarchy 重定义的内存和存储层次结构;
- Interconnect at Hyperscale 超大型互联;
- Security Built on a Foundation of Trust 基于可信的安全;
- Unified Software. Exponential Innovation. 统一的软件,为创新指数加速;
回归正题,CPU分为上下两个部分,
第一部分是框架,

这是一个移动或者桌面处理器的方块图,内部也是非常模块化的,这里仅仅关注CPU的计算部分的Core;

下面这个Bug Aside,也就是趣闻轶事,在最近阅读的软件调试第二版中也有遇到,Hooper老师最近忽然出现的次数多了起来,Grace是GPU的Codename,Hopper现在也成了ARM CPU的Codename了;

介绍了冯诺依曼架构的分离的设计:
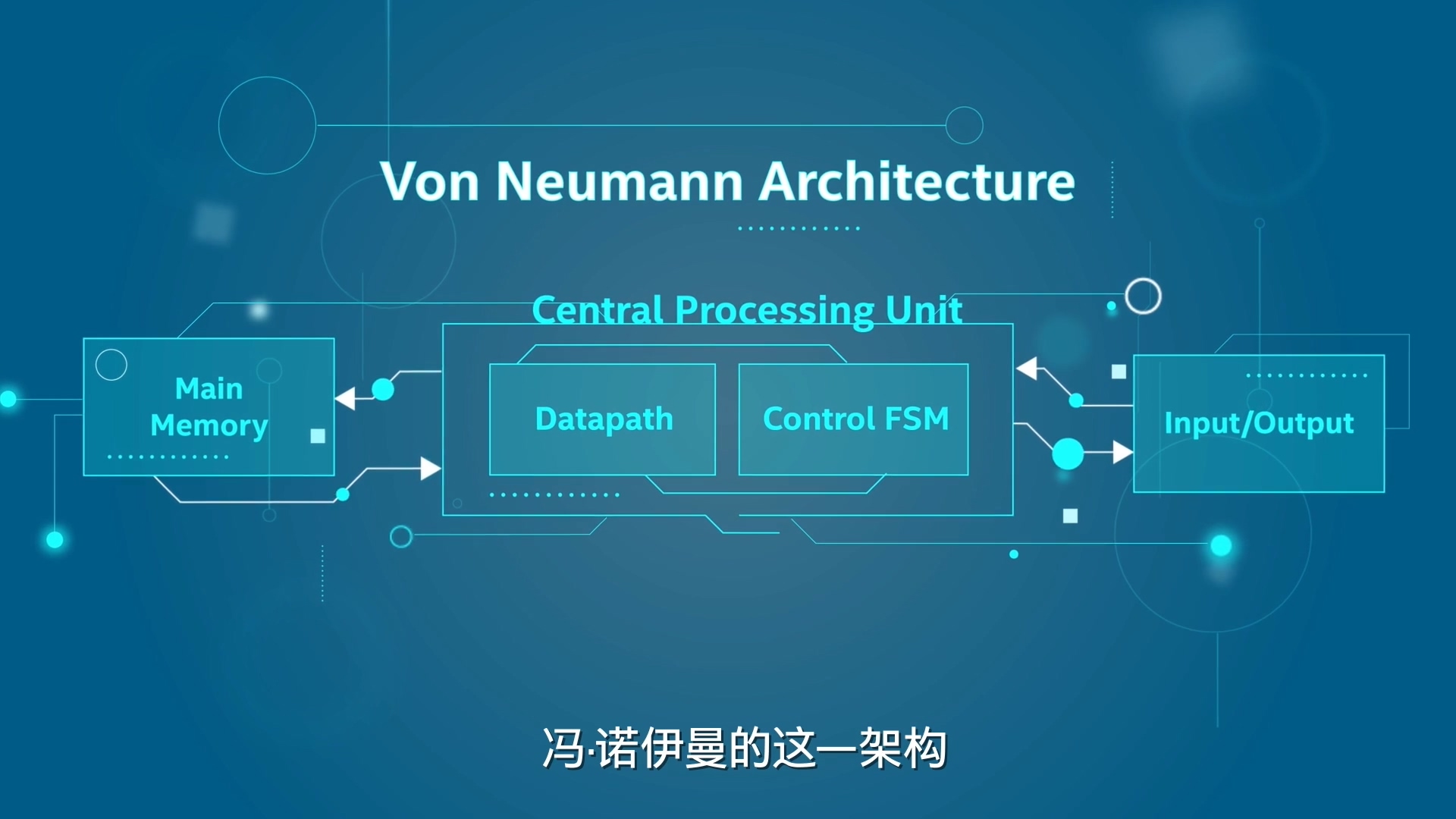
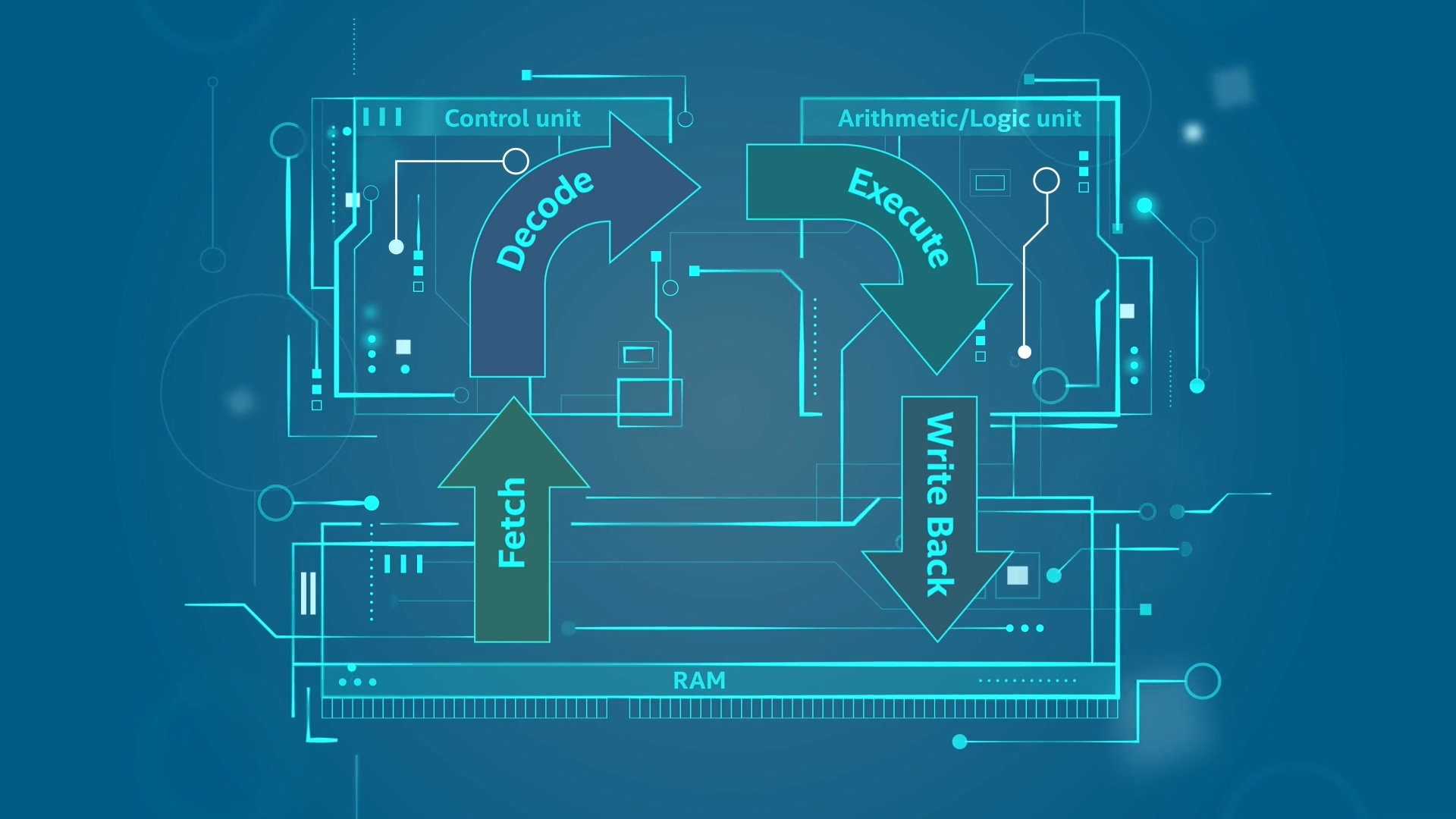
下面是取,译,执,写的图,前面两个分别对应着控制单元,后面两个对应着执行单元;
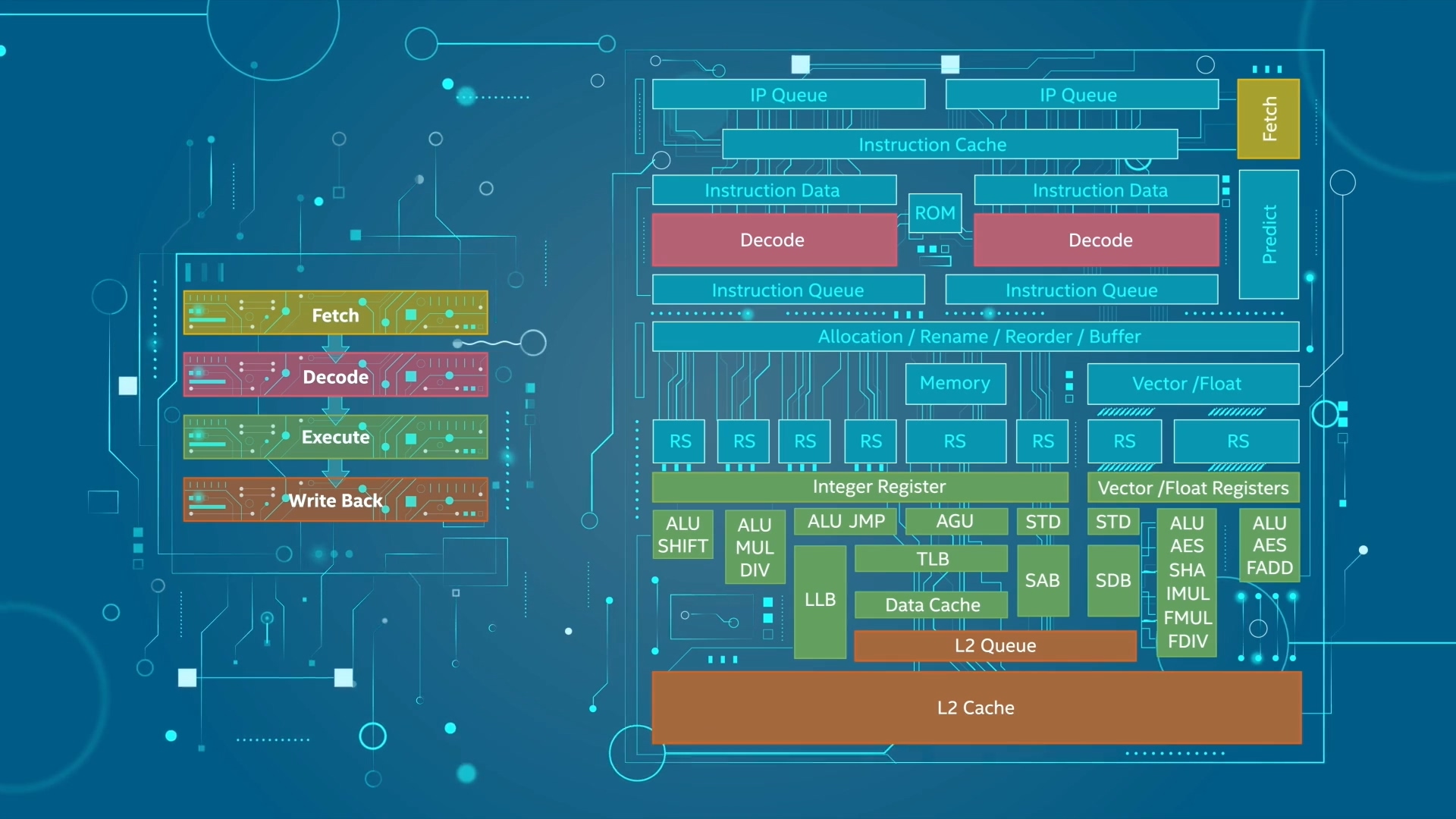
下面是分层架构,是自下而上抽象起来的;

再看一下CPU中的模块,其实每个功能的实例化并不是只有一个,或者是一类,而是很多相关的模块协同工作,为了控制复杂度,分了模块。
下面是软硬件的接口,就是ISA,读做爱涩;

最后看下logo:技术支柱,6个方块。

第二步部分深入微架构
取-译-执-写,构成的就是Pipeline;

Pipeline大概有15-20个Stages,称为阶段,阶段就是分解任务,让任务执行的速度更快,每个Stage对应1个Clock,时钟更快也是Stage分割的驱动力; (重要概念pipeline)
取-译,一般是6-10个阶段,统称为前端;

相应的,执-写,一般也是6-10个阶段,统称为后端;
代码一般包含分支,遇到分支pipeline等待是不合理的,所以要继续跑,然后遇到执行,这个时候就知道选择对不对,进而纠正自己的预测算法,因为不纠正的话,惩罚是比较浪费性能的;(重要概念分支预测)
尤其是译和执越长,惩罚越重;
下面是缓存出现是因为CPU块,内存慢,这里也纠正了我的一个错误的认识,其实指令缓存也是读取Cache Line的,负责整个前端数据交给译码器;
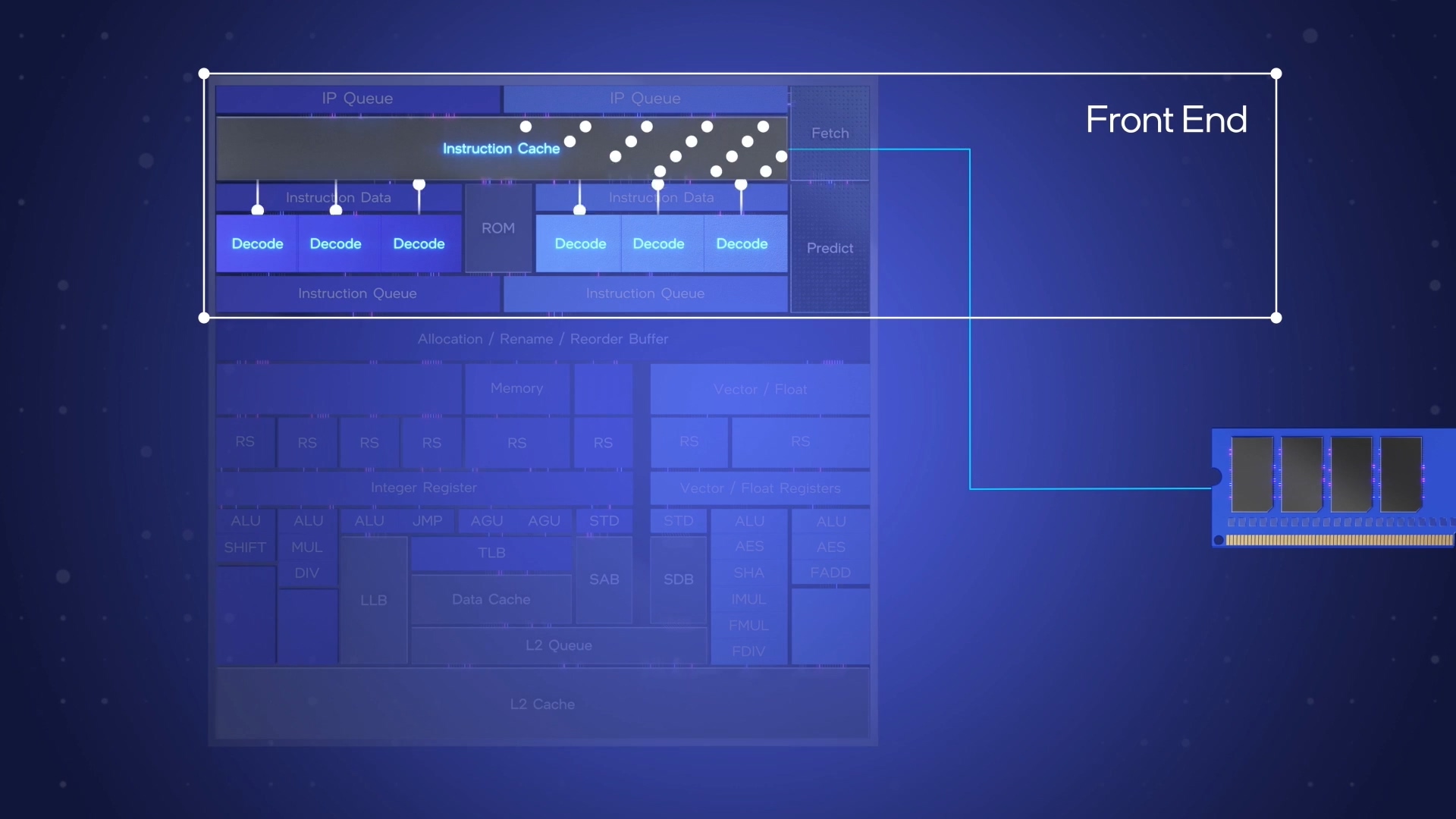
下面的重要概念是超标量,也就是向量执行,就是ALU单元不止一个;没什么特别好说的。
另外的概念是乱序执行,就是我微操作不完全按照顺序执行,是执行的一个优化,减少了等待的时间,提高了性能。
乱序执行需要执行之前分解一下相互关系,分解之后交给调度器,分配给可以执行操作的执行器;
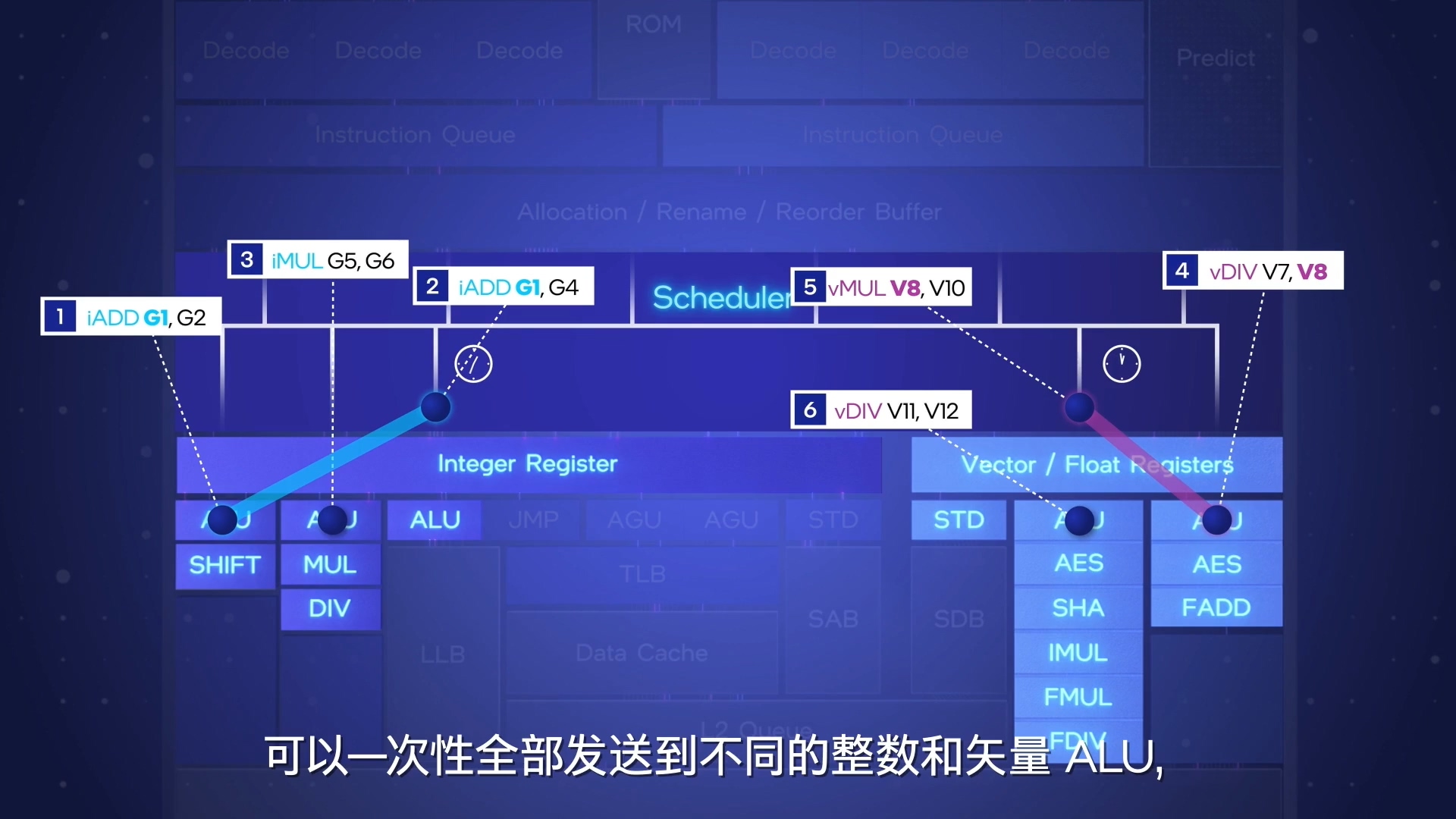
结束之前,再看下目录,发现cache的部分丢失了,估计内容太多,会单独起个存储层次结构的章节吧;

THE END
2021年5月30日