SNC
UMA
处理器一致的共享所有的物理内存
随着CPU的增加,内存访问冲突增加,CPU资源浪费,适合CPU数目为个位数的系统。
NUMA
处理器访问物理内存的时间依赖于内存的物理位置。远程和本地。
尽量减少延时较长的远程访问。
对Skylake,Socket间互相访问是远程。Socket内部Cluster间的互相访问是SNC发挥作用的地方。
现代X86机器很明显是NUMA结构的
SNC开,上面提到了,2 Clusters per Socket;这时,内存访问延时比较大,1-Way Interleave,也就是不交织。
SNC关,1 Cluster per Socket;这时,设置为2-Way Interleave,Socket之间相互访问。
什么是内存交织
CPU存取内存,类比人吃盘子里面的食物。这里一个盘子一个手吃的时候是不交织,两个盘子两个手吃的时候就是2路交织了。
连续内存(食物)总是充分利用所有的盘子。而且,吃饭的速度远比盘子传递饭的速度快很多。
上一代的类似技术叫做COD(Cluster On Die)
COD
- COD时代将LLC按照IMC分成两个不同的Cache Agent,每个都有独立的NID。
- 任何Cache Line都可能在两个Cache Agent中分别存在。两个Cache Agent需要交叉Snoop。
- Cluster0中的Core请求Cluster1中的IMC控制的地址时候,由Cluster1中的LLC服务。相对快。但是与Cluster 1 Snoop,保证一致性。
- Cluster0中的Core请求Cluster0中的IMC控制的地址时候,由Cluster0中的LLC服务。很快,但是可能需要和Cluster 1 Snoop,保持一致性。
SNC
- 假设按照IMC分为Cluster0和Cluster1,Cluster分别包含自己的Core和IMC。
- LLC是一个统一的Cache Agent。
- Cluster0中的Core请求Cluster1中的IMC控制的地址时候,由Cluster1中的LLC服务。相对慢。但是缓存一致。
- Cluster0中的Core请求Cluster0中的IMC控制的地址时候,由Cluster0中的LLC服务。很快,没必要Snoop缓存一致。
LLC Prefetch
开启的时候给Core Prefetch一种直接把预取数据存在LLC的能力,而不必填充MLC。
但是这样并不能算是提高性能,因为LLC慢很多,之所以有这个属性是因为Skylake的MLC个LLC是互相不包含的,能做到这个预取,但是一般我们不使用。
这个属性主要是节省了MLC的空间,但是性能上不见得更好。推荐关。
Dead Line LLC Allocation
当Cache Line的有效位复位,也就是标记为无效的时候。MLC会将数据逐出。这个时候LLC有选择的机会,是接受还是不接受。
关闭时候,不接收,节省LLC的空间,使得LLC不必驱逐自己的数据,去缓存没用的Cache line。明显推荐关闭。
开启时候,适时的将MLC的Deadline移动到LLC中。
Stale/Directory AtoS
In Memory Directory有三种状态
- I:Invalid表示数据是clean的并且不再其他socket中缓存
- A:SnoopAll表示数据存在于另外一个Socket exclusive[独有]或者已更改状态
- S:Shared表示数据Clean,但是可能Shared across一个或者多个socket Cache
当读取内存时,directory line是A状态时,必须snoop所有的sockets,得到modified data。但是也可能返回miss,因为another socket可能读取cache line之后默默的drop掉。
当Disable的时候会发生上面的情况
当Enable的时候,A->S状态,不再Snoop,节省Snoop的带宽。对于很多cross socket 读负载的情况,Enable的话很明显较好。
Local Remote Threshold
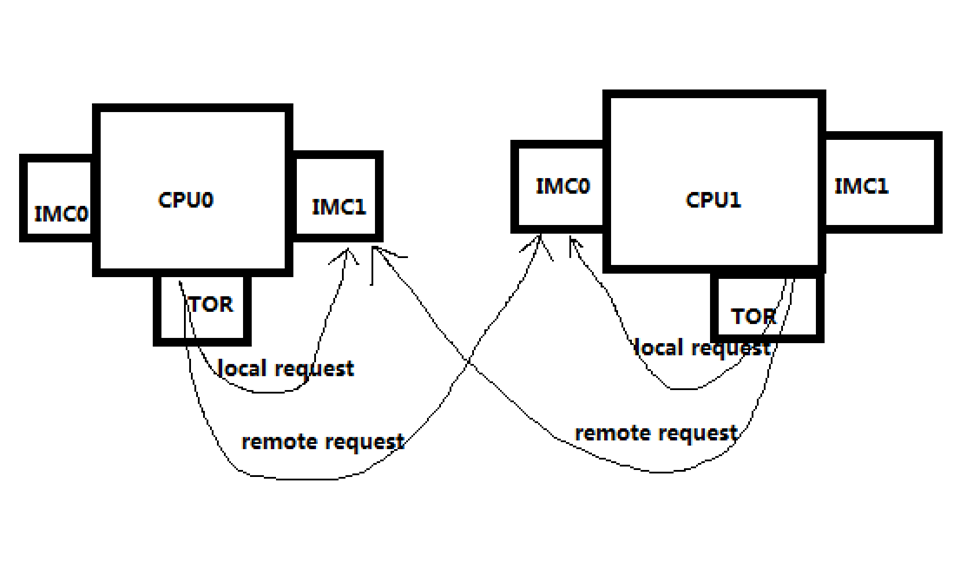
单路环境中会产生Local Traffic
多路环境中会产生Local Traffic/Remote Traffic
Table of Requests(TOR)通过UPI为Remote/Local请求提供服务
Remote Reads指定TOR发送读取请求给IMC,当数据从IMC返回的时候,TOR尝试通过UPI给Request Socket发送一个Data Response
请求和回复的Rate由UPI bandwidth通过Credits进行管理。这个Rate是可以调节的,用来限制Incoming Transactions的数目以避免Remote Socket的Overloading。这个Bandwidth大致上比Local Memory Bandwidth或者TOR Service Bandwidth要低。
当UPI是瓶颈的时候,这些Remote Reads会停在TOR中一段时间
当一个Socket的TOR被Remote Read充满时,不能很好的为Local Request服务了。另一个相对free的Socket持续发送Remote Requests给饱和的Socket会造成Imbalance.
一般的Imbalance可以通过Shift Around恢复平衡,但是如果一个通道是饱和的还持续受到相对free的通道的请求的话,很难自身恢复平衡。
新的BIOS中给定local/remote Threshold可以控制这个Rate,帮助避免imbalance
这个选项控制2个Features
Remote Request Queue,通过声明一个临界值对TOR中的remote读进行调节
Incoming Request Queue,通过声明一个临界值对TOC中的Local-to-remote读进行调节
BIOS会首先检测Socket和UPI,然后根据这个设定默认值。为了简化BIOS的设置,上面的两个临界值通常是组合设定。
这个选项有四个选择
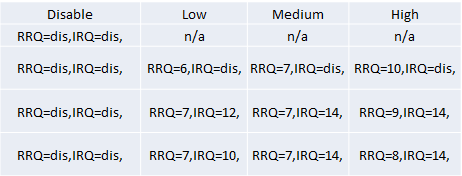
不同的Socket推荐的默认选择也不一样