作业要求的博客链接:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139
git仓库地址:https://git.coding.net/isak_even/wfAnalysis.git
第一次作业—词频统计v1.0:https://www.cnblogs.com/kongwy/p/9662364.html
一、项目概要:
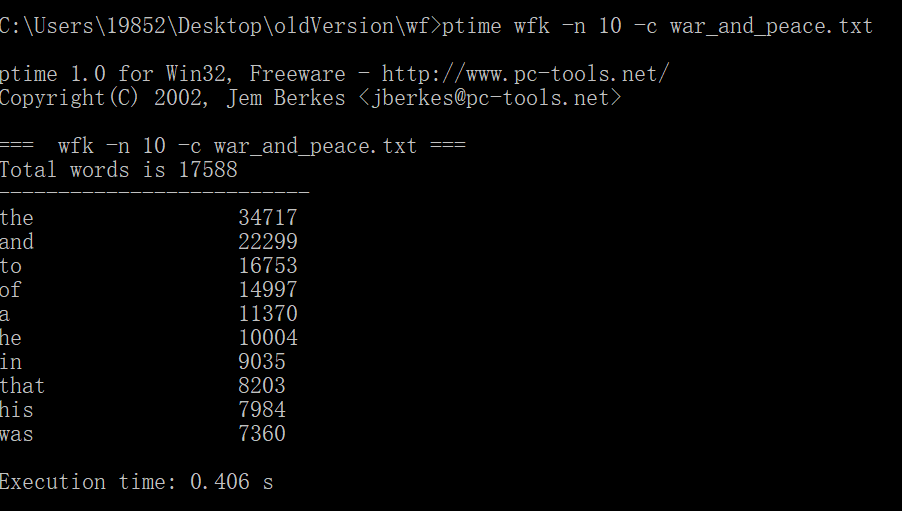
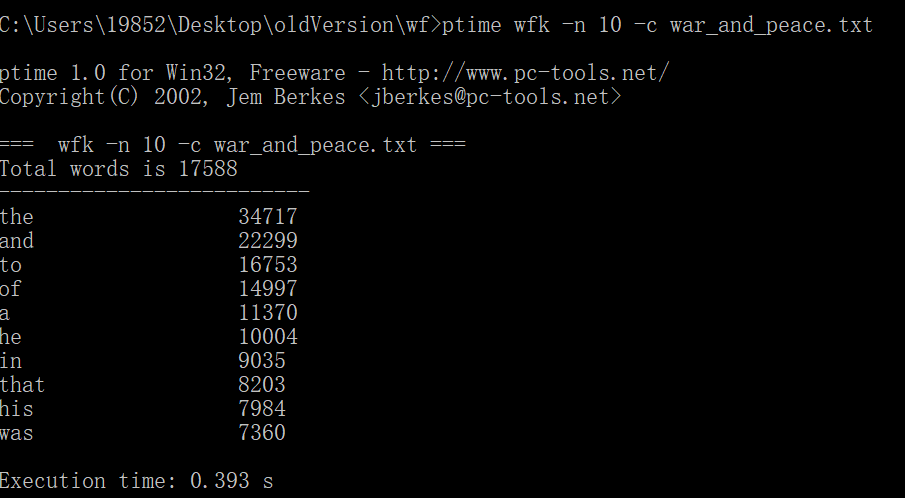
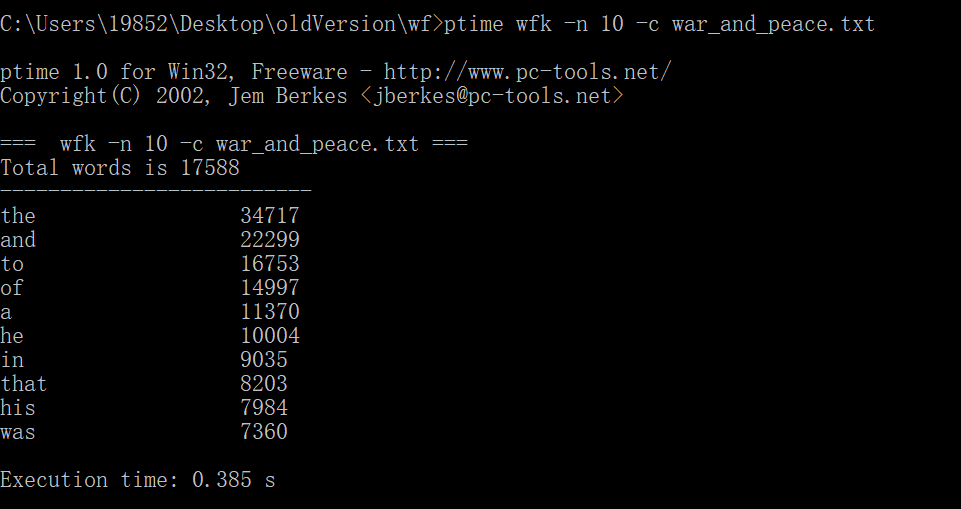
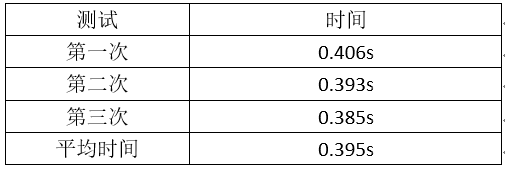
本次项目实现的是词频统计的效能优化,v1.1主要改进功能三,目前测试《战争与和平》结果的最优时间为0.385。
二、效能分析
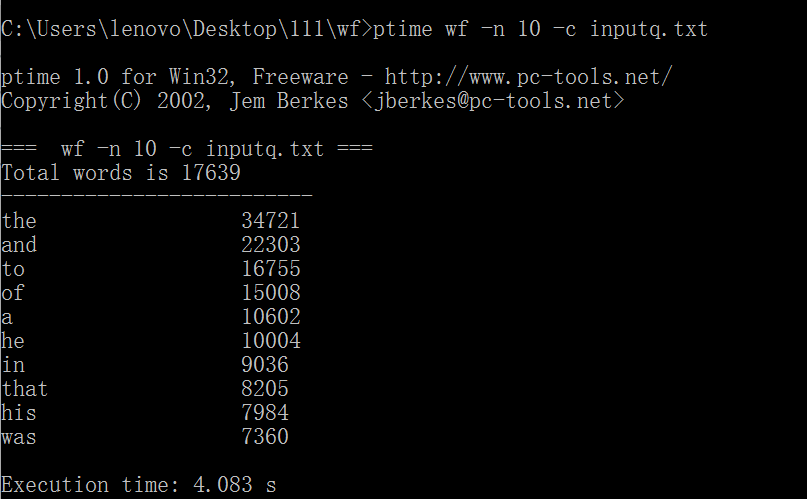
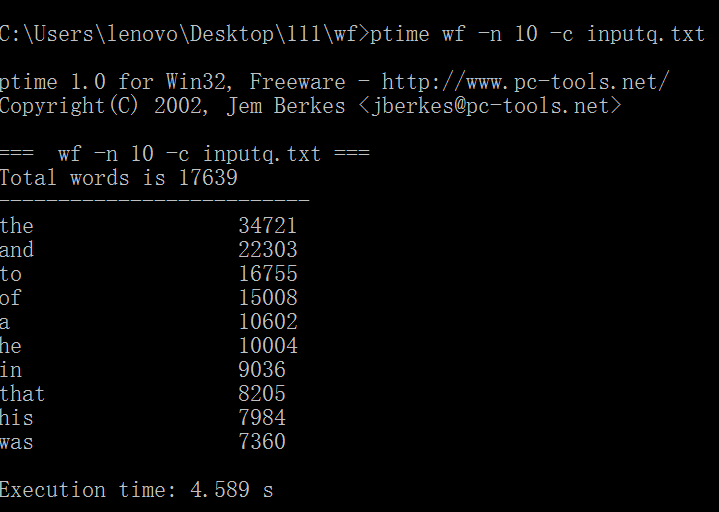
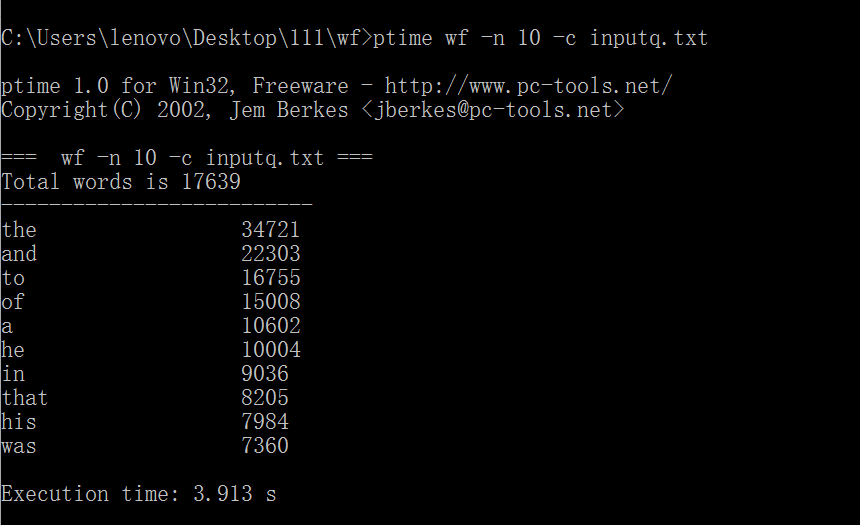
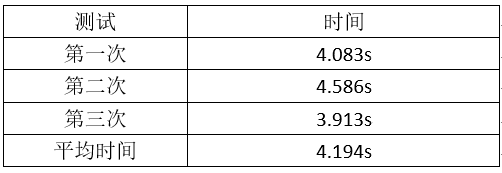
1.以war_and_peace.txt作为测试文件,连续三次运行,给出每次消耗时间。
原始代码没有使用命令行参数,经过改进后测试截图如下:
2.猜测瓶颈
(1)第一个瓶颈应该就是读文件,将文本处理成字符串。这次处理的是3.14MB的文本文件,读文件一定是耗时最长的单元,这个地方应该优化一下。估计优化后时间会缩短一半。
/* ----实现读取指定文件的功能-----*/ void readtxt(string filename) { ifstream file; file.open(filename.c_str());//注意一定要转化为 char * string s; //每次读取一行txt文件返回的字符串 while(getline(file, s))//按行读取 { str=s+' '+str;//加空格确保分割开行尾和行首的两个单词 } transform(str.begin(), str.end(), str.begin(), ::tolower);//将大写转化为小写 file.close(); //关闭文件 }
(2)第二个是分割字符串,并且统计合法单词的词频。理由同上,测试数据过大所以耗时长,优化后时间会缩短。
for (long i=0;i<str.length();i++) { while(str[i]>='0'&&str[i]<='9'||str[i]>='a'&&str[i]<='z') { temp=true; b+=str[i]; i++; } if(temp) { word=b; if(word[0]>'9'||word[0]<'0') //判断第一个字符是不是数字 { ++word_count[word]; vec.push_back(word); } b=""; word=""; temp=false; } }
3.利用profile找出瓶颈并优化
第一次profile的截图如下:

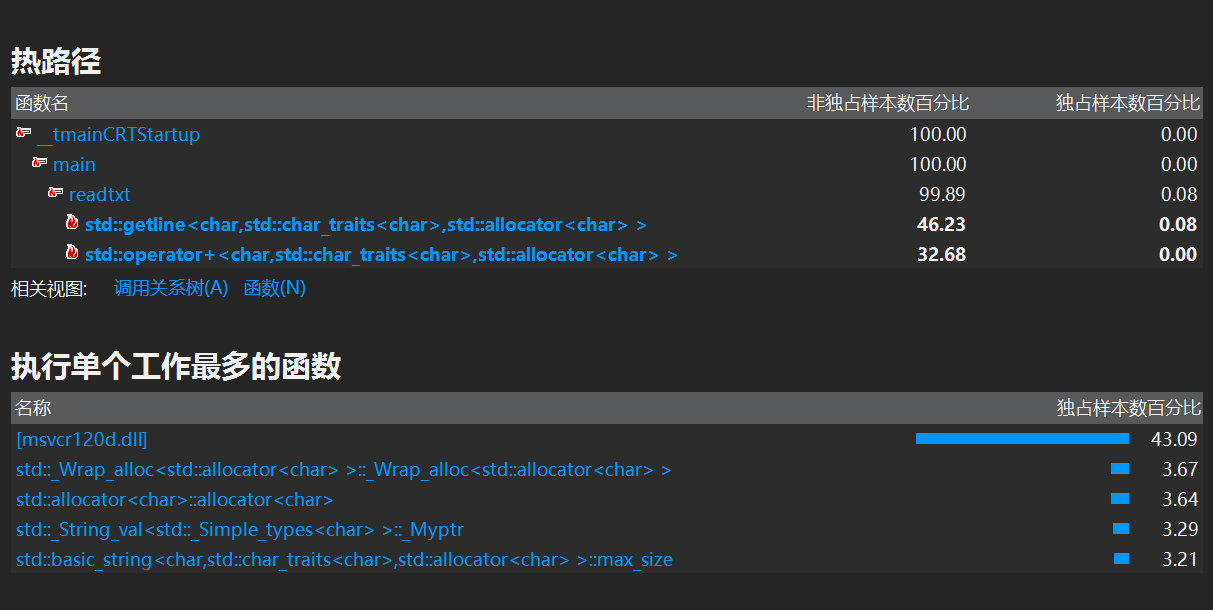
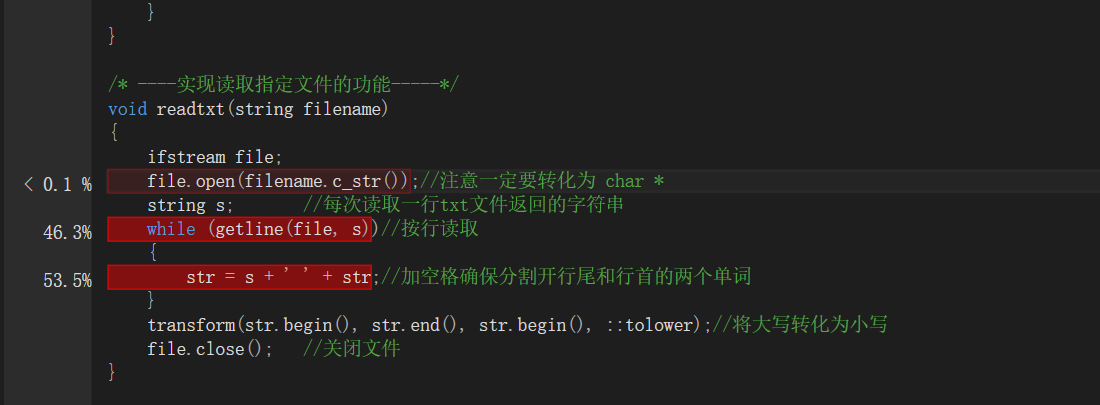
(1)可以看出getline(file,s)和字符串的合并是耗时最长的。分析后决定把读文件和分割出合法字符串合在一起,读完一行就进行处理,就可以省略str = s+' '+str。
(2)调试后发现transform函数也比较耗时,便将处理大小写转变为判断字符,确定是大写字母再转化为小写字母。
(3) 将for (long i = 0; i<str.length(); i++) 转变为 long a = str.length(); for (long i = 0; i<a; i++),这样不需要每次循环都调用length()函数。
优化后第二次profile截图如下
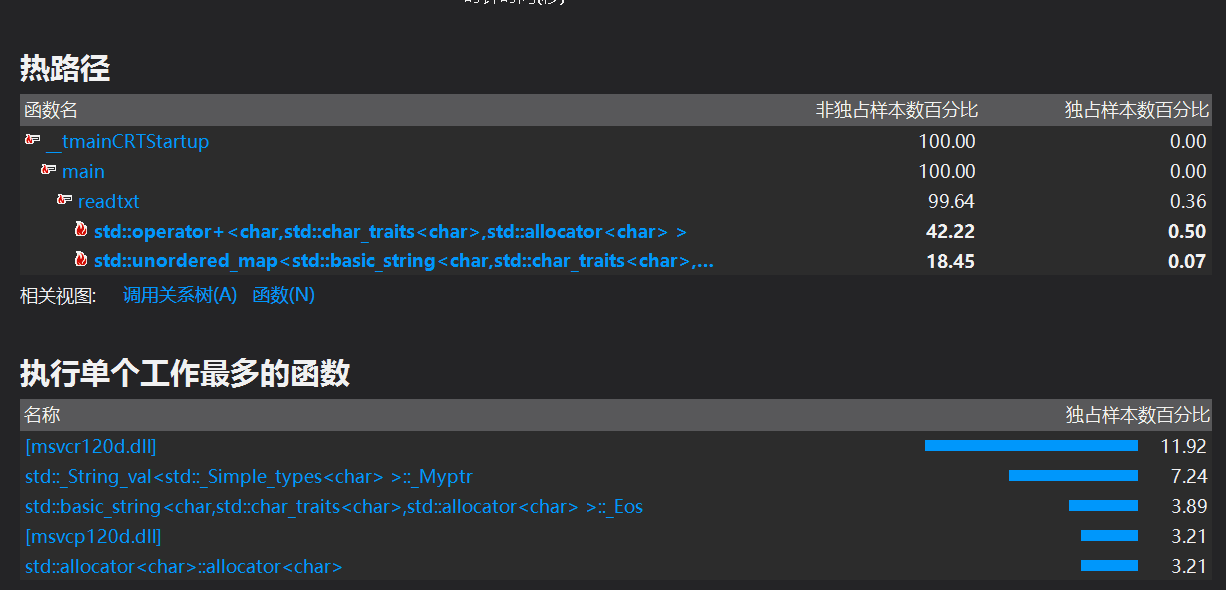
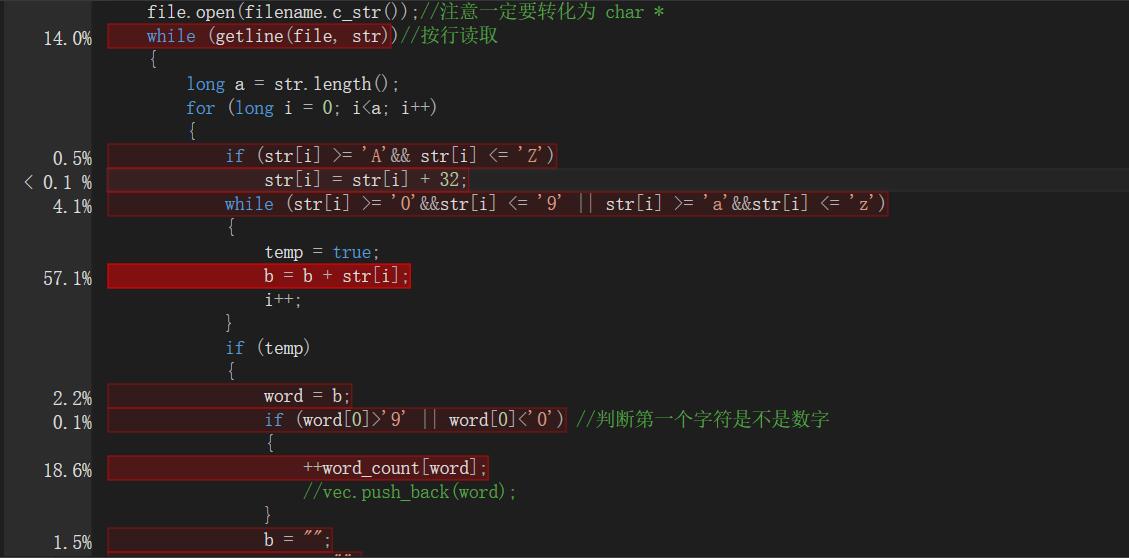
(1)再次测试后此时耗时最长的是b=b+str[i]。参考博客:http://www.cnblogs.com/chuncn/archive/2009/02/13/1390176.html 我改为:b.append(1,str[i]);
(2)++word_count[word]耗时也长。map函数是自动排序的,这样效率会低一点,所以我换成unordered_map<string, long> word_count;
参考博客:http://www.cnblogs.com/me115/archive/2013/06/05/3117967.html
(3)最后将功能一和二共同改进一下。
4.优化后的profile截图
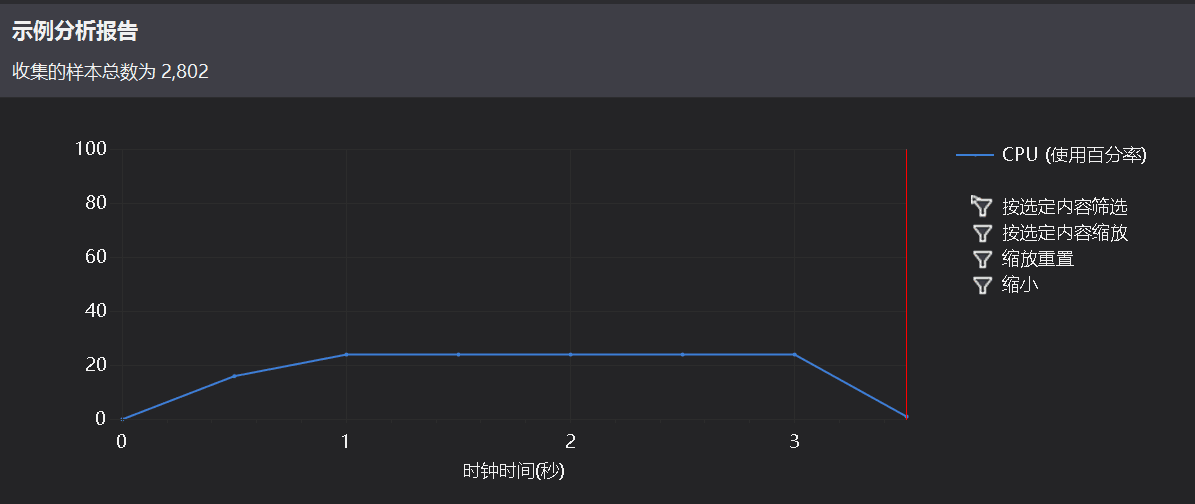
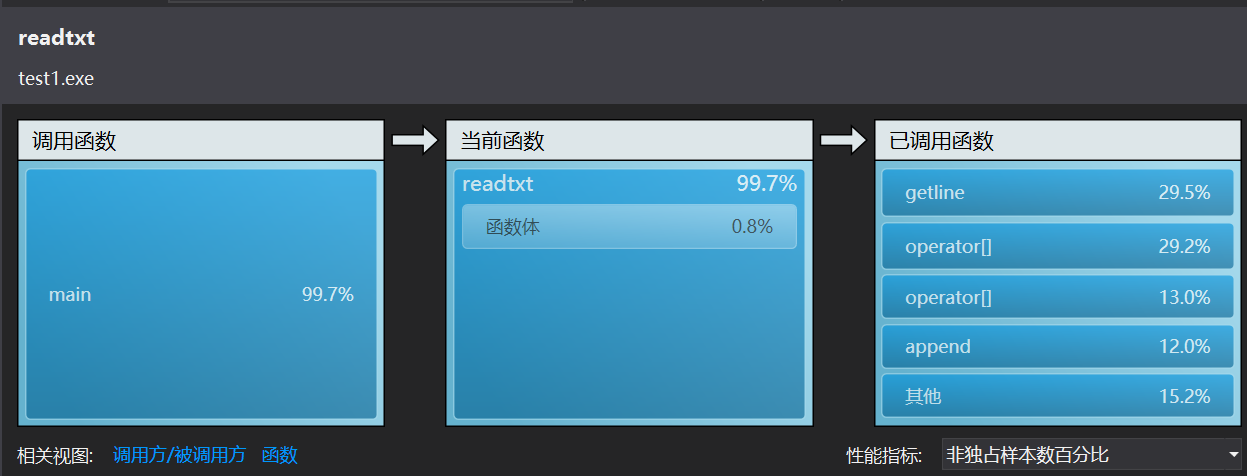
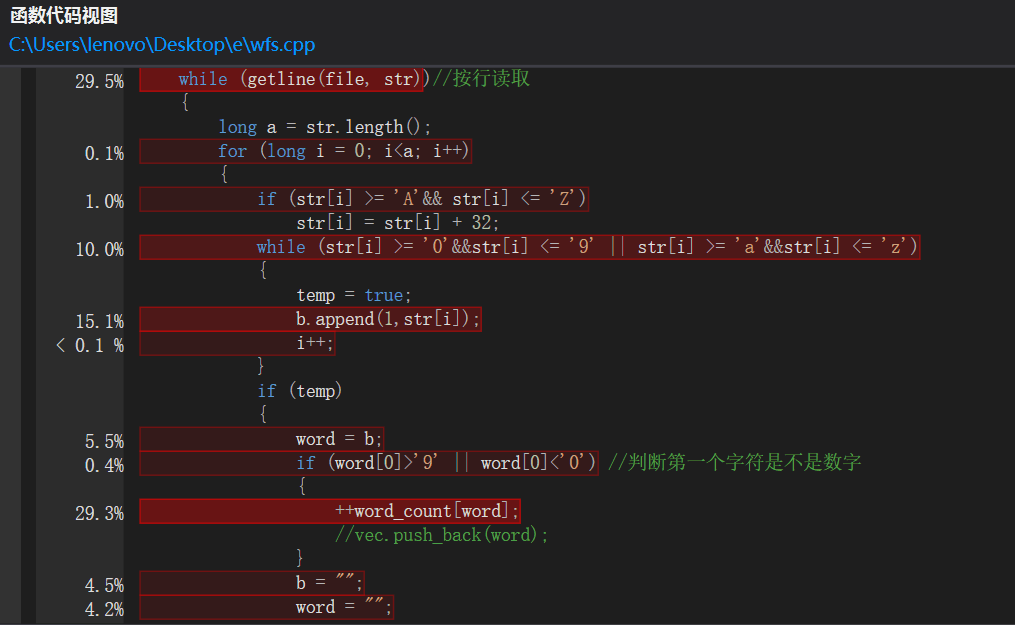
5.优化后时间
三、自我评估
个人基本情况见第零次作业 博客地址:https://www.cnblogs.com/kongwy/p/9611339.html
这次作业主要是优化代码,提高效率,也是解决自己上次遗留的问题。
(1)在初步测试的时候其实不太好用,通过参考其他人的博客,发现没有使用命令行参数,就是int main(int argc, char* argv[]),更改之后代码也简单了不少。
(2)用ptime测试时发现电脑配置对代码的运行效率影响较大,所以在室友的笔记本和学院的机房都进行了多次测试。
(3)安装VS,并且启用性能分析,通过阅读《构建之法》第二章基本了解到抽样和代码注入的区别。这次采用的主要还是抽样。
(4)发现VS要求比较严格,代码不能用头文件#include<bits/stdc++.h>以及需要将 sscanf改为sscanf_s。
(5)优化代码之后大概减少了四十行,速度提高了十倍左右。