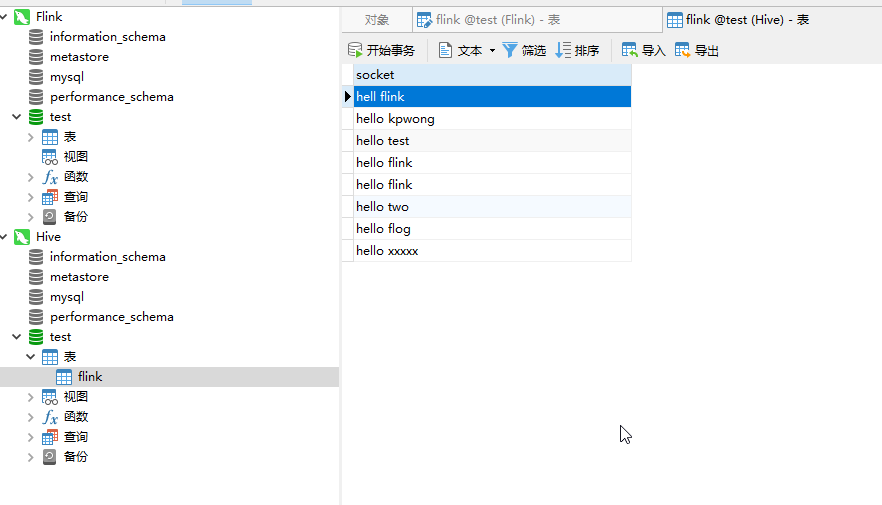
POM 文件
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
代码:
package com.kpwong.sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
object JDBCSinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val socketDS: DataStream[String] = env.socketTextStream("hadoop202",9999)
//sink
socketDS.addSink(new MyJDBCSink())
env.execute()
}
}
//注意 必须继承富函数类,这样才有生命周期管理函数
class MyJDBCSink extends RichSinkFunction[String]{
//定义SQL 链接 预编译器
var conn: Connection =_
var insertSql: PreparedStatement=_
//创建链接和预编译语句
override def open(parameters: Configuration): Unit = {
super.open(parameters)
conn = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/test","root","000000")
insertSql= conn.prepareStatement("insert into flink(socket) values (?)")
}
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
// super.invoke(value, context)
insertSql.setString(1,value)
insertSql.execute()
}
override def close(): Unit = {
// super.close()
insertSql.close()
conn.close()
}
}
测试 :socket输入输入数据
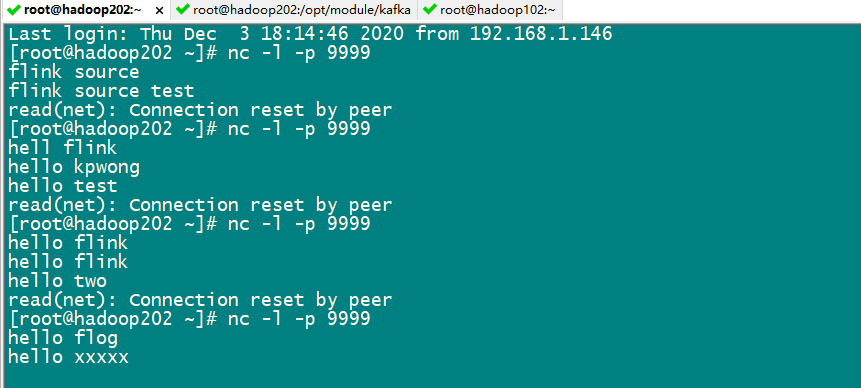
MySql 接受数据: