一.交叉表:
作用:
交叉表是一种用于计算分组频率的特殊透视图,对数据进行汇总
考察预测数据和正式数据的对比情况,一个作为行,一个作为列
案例:
医院预测病人病情:
真实病情如下数组(B:有病,M:没病)
true = np.load("./cancer_true.npy") #load()加载数据
true

算法预测病情数据如下:
predict = np.load("./cancer_predict.npy")
predict

现在要知道预测结果有多少预测正确,多少预测失败
使用交叉表:
#使用交叉表,调用crosstab()函数。
参数如下:
['index', 'columns', 'values=None', 'rownames=None', 'colnames=None', 'aggfunc=None', 'margins=False', "margins_name='All'", 'dropna=True', 'normalize=False'],
预测结果:
pd.crosstab(index = true,columns=predict,rownames = ["确诊"],colnames = ["预测"],margins=True)

可以看到预测正确的结果有36+17个,2个漏诊,2个误诊
二.透视表:
它根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中
分组查看数据,和数据库中的group by是相同的功能。
案例:
分析人的使用左右手跟情商(eq)、智商(iq)的关系
添加数据(伪造)
df =DataFrame({"HAND":np.random.randint(0,10,size = 200),"sex":np.random.randint(0,2,size = 200),"iq":np.random.randint(0,100,size =200),"eq":np.random.randint(0,100,size = 200)})
df
 (部分数据)
(部分数据)
对数据进行处理:
使用透视表:
调用pivot_table()函数
参数有:
['data', 'values=None', 'index=None', 'columns=None', "aggfunc='mean'", 'fill_value=None',
'margins=False', 'dropna=True', "margins_name='All'"],
pd.set_option("display.float_format",lambda x:"%0.1f"%(x))
pd.pivot_table(data = df,values = ["iq","eq"],index = ["HAND","sex"],aggfunc= "mean",margins = True)
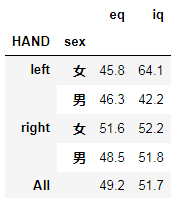
通过表分析字段之间的关系。