早期计算机是美国发明的. 普及率不高, 一般只是在美国使用. 所以. 最早的编码结构就是按照美国人的习惯来编码的. 对应数字+字母+特殊字符一共也没多少. 所以就形成了最早的编码ASCII码. 直到今天ASCII依然深深的影响着我们.
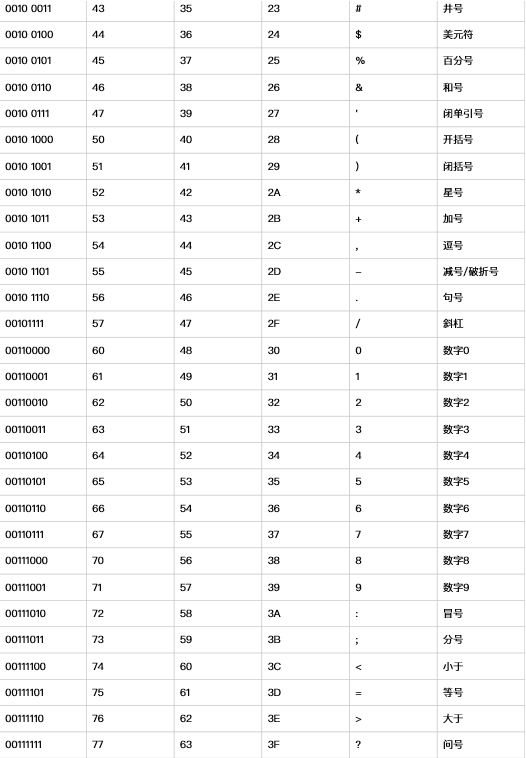
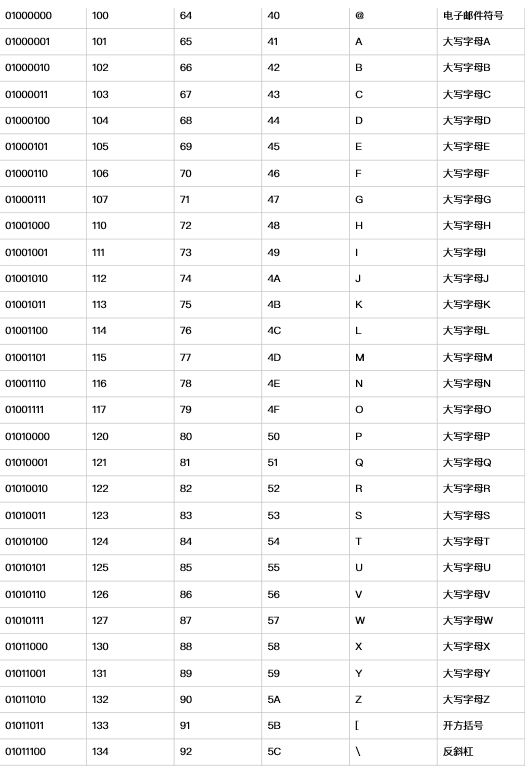
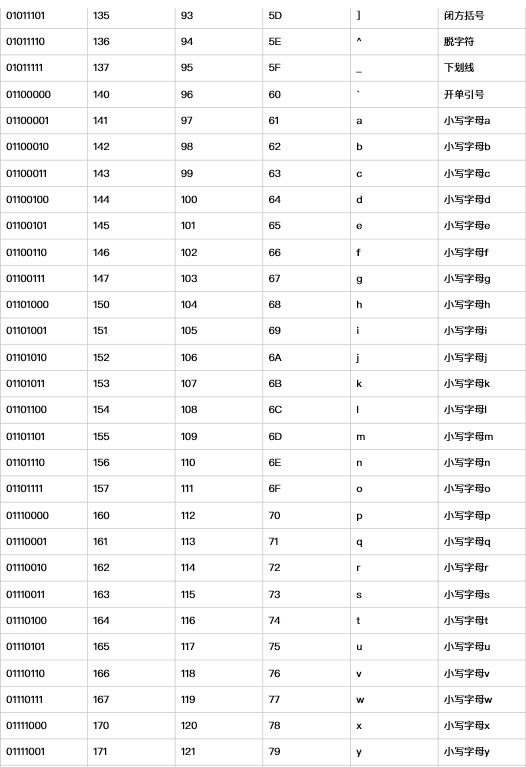
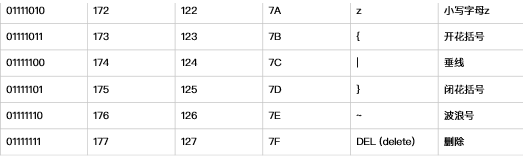
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字⺟母的一套电脑编码系统,主要用于显示现代英语和其他⻄西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
随着计算机的发展. 以及普及率的提高. 流行到欧洲和亚洲. 这时ASCII码就不不合适了. 比如: 中文汉字有几万个. 而ASCII最多也就256个位置. 所以ASCII不行了了. 怎么办 呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境.
比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使⽤用计算机了.
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不支持英文肯定不行. 而英文已经使用了ASCII码. 所以GBK要兼容ASCII.
国标码的弊端:只能中国用.日本就垮了.所以国标码不满足我们的使用.这时提出了一个万国码Unicode.
unicode一开始设计是每个字符两个字节.设计完了.发现我大中国汉字依然无法进行编码.只能进行扩充.扩充成32位也就是4个字节.这回够了.但是.问题来了.中国字9万多.而unicode可以表示40多亿.根本用不了.太浪费了.于是乎,就提出了新的UTF编码.
可变长度编码UTF-8:每个字符最少占8位.每个字符占用的字节数不定.根据文字内容进行具体编码.比如.英文.就一个字节就够了.汉字占3个字节.这时即满⾜足了中文.也满足了节约.也是目前使用频率最高的一种编码。
UTF-16:每个字符最少占16位.GBK:每个字符占2个字节, 16位.
单位转换:
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB
1024YB = 1NB
1024NB = 1DB