linux内核用到了很多数据结构,这些数据结构都是为了提高某些方面的效率。
内核分配给进程的虚拟地址空间由以下内存区组成:
- 程序的可执行代码
- 程序的初始化数据
- 程序的未初始化数据
- 初始程序栈(即用户态栈)
- 所需共享库的可执行代码和数据
- 堆(由程序动态申请的内存)
内核和MMU(内存控制单元)协同定位虚拟地址空间在 内存中的实际物理位置
p89
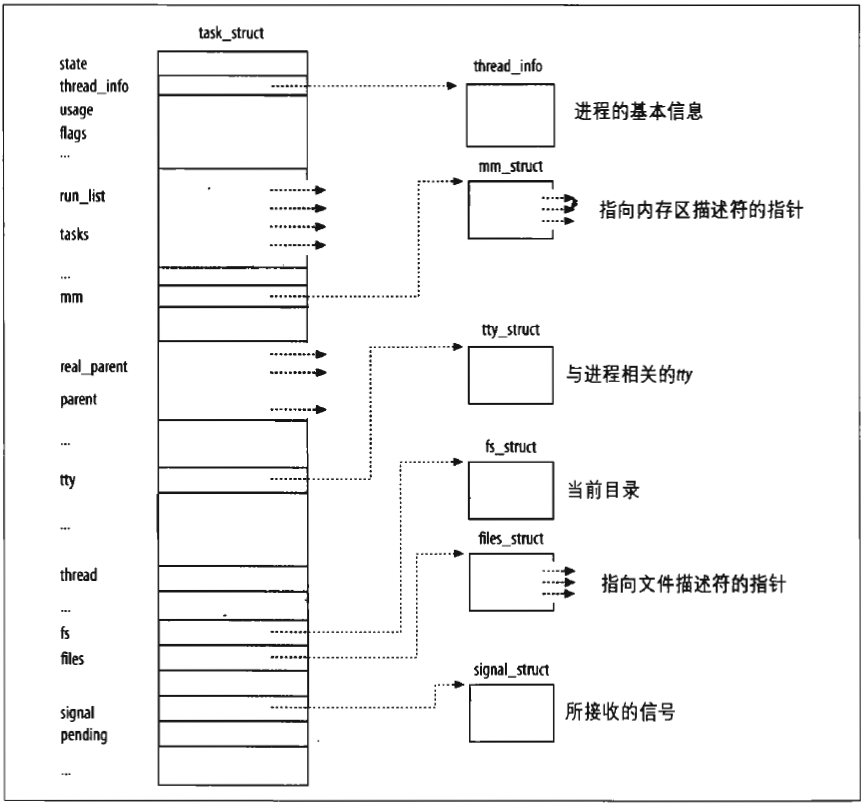
进程描述符(process descriptor)task_struct类型结构,存在动态内存中,而不是在内核的内存区。
对每个进程来说,Linux都把两个不同的数据结构紧凑地存放在一个单独为进程分配的存储区域内:一个是与进程描述符相关的小数据结构thread_info(52个字节长),叫做线程描述符。另一个是内核态的进程堆栈(只需要几千个字节就够了,因为内核控制路径使用很少的栈),这块存储区域的大小通常为8192个字节。
这个两个东西紧密结合的主要好处:内核很容易从wsp寄存器的值获得当前在cpu上正在运行进程的thread_info结构的地址。即屏蔽掉esp的低13或12位有效位。
通过thread_info结构->task可以获得进程描述符的地址。

栈从末端向下增长,线程描述符驻留在这个内存区的开始
esp寄存器是CPU栈指针,用来存放栈顶单元的地址。从用户态刚切换到内核态后,进程的内核栈总是空的,因此,esp寄存器指向这个栈的顶端。
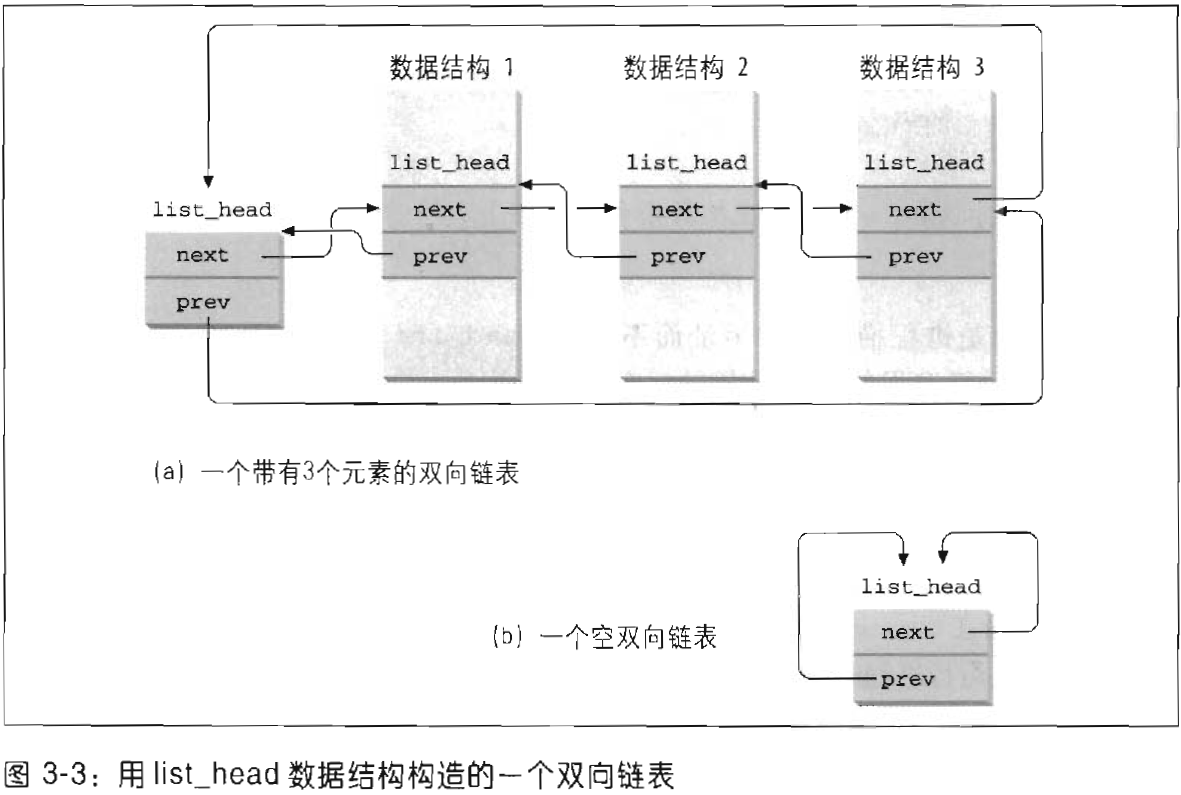
linux内核定义了list_head数据结构(双向链表)
prio_array_t数据结构//为了寻找优先级最高的新进程在cpu上运行(这里所以进程都是可运行进程,即处于 TASK_RUNNING)
//把不同优先级的进程放在不同的优先级链表中。

state 进程当前状态,由一组标志组成
进程标识符PID 顺序编号,越来越大
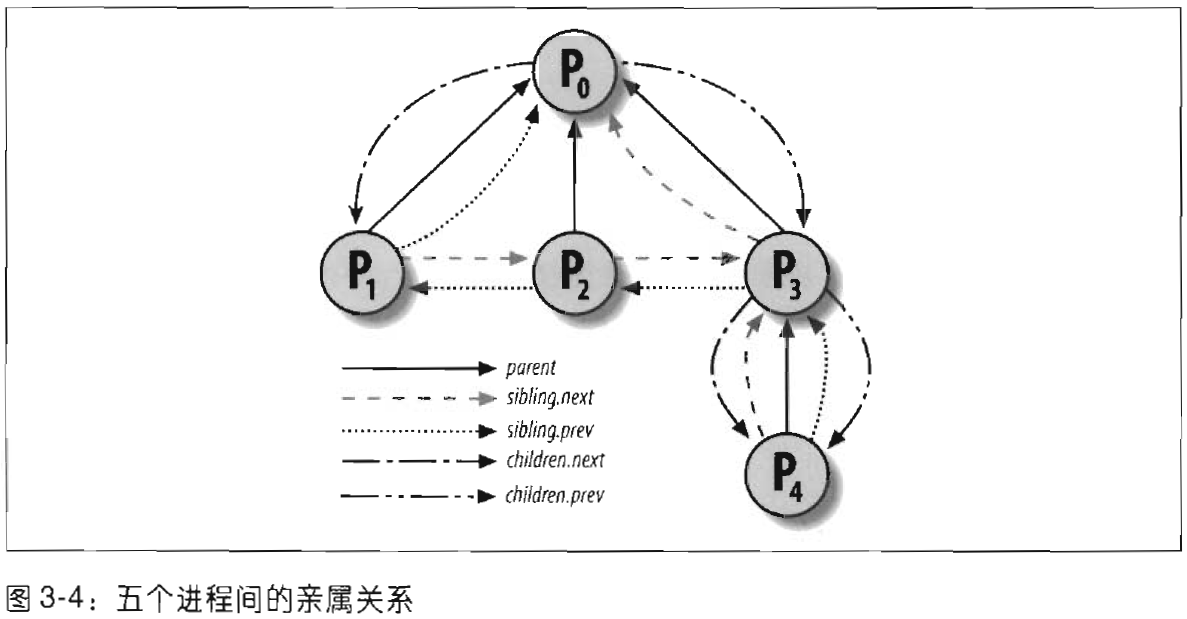
进程链表把所有进程的描述符链接起来。每个task_struct结构都包含一个list_head类型的tasks字段,其prev和next分别指向前面和后面的task_struct元素。
进程链表的头是init_task描述符,它是所谓的0进程或swapper进程的进程描述符。init_task的tasks.prev指向链表中最后插入的进程描述符的tasks字段。
进程0和进程1是由内核创建的,进程1(init)是所有进程的祖先。

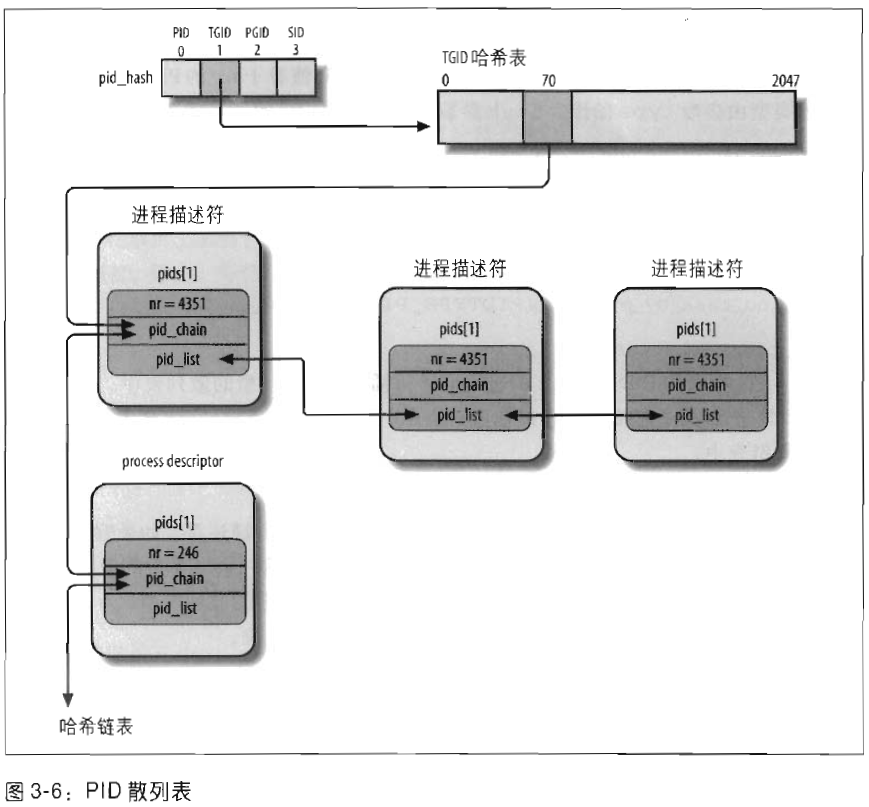
pidhash表与链表
为了从PID找到对应的进程描述符指针。(eg kill())
如果全表扫描会很慢,所以使用散列表,冲突部分(例如同进程组的所有进程组号相同)用链表解决的方法。

4种PID,所以4个散列表。

pid结构

PID散列表