文字在计算机怎么显示
ASCII
创建于1967年左右
完善于1980年左右
该表将计算机的每一个字符用数字表示

GB2312
诞生于1981年
开始收录了6000+常用汉字和600+常用符号
常用编码为EUC-CN、也有HZ这个编码(主要用于email中)
- EUC-CN中,英文一个字节,中文两个字节
- HZ中英文都为一个字节
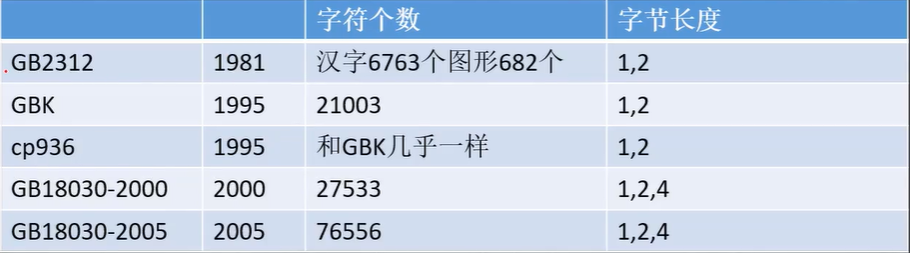
GBK
发布于1995年
有20000+个字
GB2312的升级
cp936
微软(IBM也有,这里主要讲微软)也发布于1995年
借鉴了GBK
微软公司为世界各地的版本而开发的编码,中文正好在936页,cp为code page。取名为cp936
GB18030
发布于2000及2005
00版本20000+字
05版本70000+字
参考了unicode
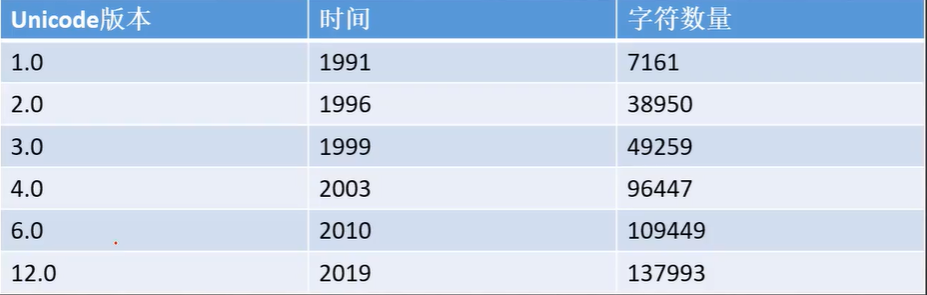
Unicode
包含了世界上所有的字符!
最早发布于1991年,有7000+字符
最近更新版本为2019年版Unicode12.0,共130000+字符
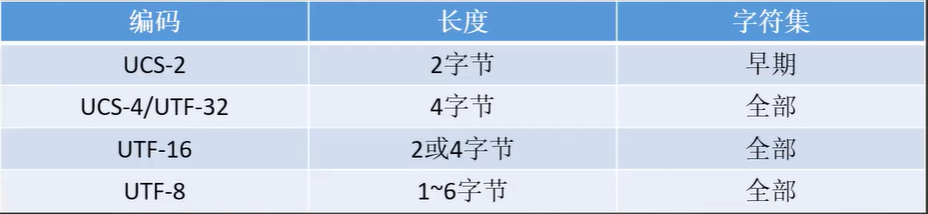
常用编码:
- UCS-2 使用两个字节进行表示,不过上限为65526,当今已用不到了
- UCS-4/UTF-32 使用四个字节表示,不过对于英文太过于浪费
- UTF-16 一般使用16位进行表示,对于一些需要4字节编码的字使用32位表示是一个可变长的编码
- UTF-8 也是属于可变长的编码,英文使用一个字节,中文一般三个字节(有识别位),最多可以表示到6个字节
- UTF-7 用于email,email设计之初只接纳英文,不接受其它字,UTF-7使email可以接收其它字
Base64编码
不是文字编码的一种基本格式,主要是用于文件传输中的隐蔽性,相比于其他用于加密的编码,Base64简短,且在文件传输时,具有不可读性
加密过程:
Man
4D 61 6E # 16进制ASCII
01001101 01100001 01101110 # 2进制ASCII
010011 010110 000101 101110 # Base64加密,高位加两个0
00010011 00010110 00000101 00101110
19 22 5 46 # 10进制形式
T W F u # 根据Base64表

区别字符集和编码
字符集:Charset 字符的集合 只收录所有的字符,不管该字符在计算机中的表示
Code Point:Unicode的概念,字符对应的编号(不是在计算机里的编码)
编码:Encoding ,字符在计算机中的表示
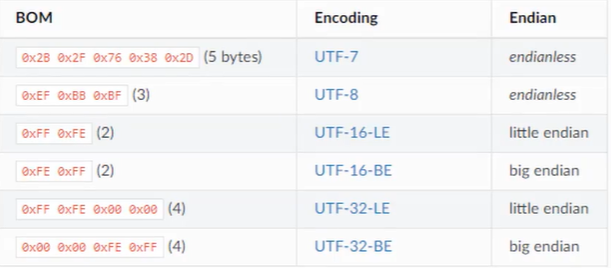
大端和小端之争
计算机底层在对于类似AB这种编码时,会采用AB和BA两种底层处理方式,主要是CPU制造商引起的,
- 低到高位(大端) PowerPC IBM公司
- 高到低位(小端) Intel公司
文字编码也有类似的问题
- 解决方法:在文件头部设定标记(BOM Bity Order Mark)也叫炸弹,来表示编码是大端还是小端
操作系统编码
Windows使用cp936(GBK)
Linux使用UTF-8
在传文件时处理不当可能会在成乱码
代码中的编码
只能识别英文的编程语言
C:没有string,使用二进制或字节流表示
C++:有string,但是没有编码,相当于字节流 (两种都可以使用第三方的库解决)
python2:字节流,中文占三个字节,UTF-8编码
可以识别中文的编程语言
python3:每一个字符占的长度是一字节
小笔记
2个16进制 = 8个2进制
一般显示可以直接显示2个16进制,省空间
GBK转UTF-8
使用了冗余信息,UTF-8字符头
54 1b # 比如一个汉字两个字节(这里使用16进制表示)
101 0100 0001 1011 # 用二进制表示
101 010000 011011 # 转码的过程,根据字节数分类,Unicode中的汉字一般三个字节
c5 90 9b
1100 0101 10 010000 10 011011
jpg文件
jpg文件存的是每一个像素的色号