TensorFlow全新的数据读取方式:Dataset API入门教程
以前的读取数据的方法实在是太复杂了,要建立各种队列,所以想换成这个更为简便的方式
参照以上教程,同时结合自己的实际例子,学习如何简单高效读取数据(tensorflow api 1.4)
Module: tf.data
1 @@Dataset 2 @@Iterator 3 @@TFRecordDataset 4 @@FixedLengthRecordDataset 5 @@TextLineDataset
以上均是tf.data的类,分别讲述,这五个不同的类的定义和使用方式
tf.data.Dataset
Represents a potentially large set of elements
properties(性质): output_shapes, output_types
Method(方法):
1. apply(fun): Apply a transformation function to this dataset. 对数据集中的数据做额外的变换
1 dataset = (dataset.map(lambda x: x ** 2) 2 .apply(group_by_window(key_func, reduce_func, window_size)) 3 .map(lambda x: x ** 3))
2. batch(batch_size): Combines consecutive elements of this dataset into batches.
3. concatenate(dataset): Creates a Dataset by concatenating given datset with this datset, 合并另一个数据集到该数据集中
1 # NOTE: The following examples use `{ ... }` to represent the 2 # contents of a dataset. 3 a = { 1, 2, 3 } 4 b = { 4, 5, 6, 7 } 5 6 # Input dataset and dataset to be concatenated should have same 7 # nested structures and output types. 8 # c = { (8, 9), (10, 11), (12, 13) } 9 # d = { 14.0, 15.0, 16.0 } 10 # a.concatenate(c) and a.concatenate(d) would result in error. 11 12 a.concatenate(b) == { 1, 2, 3, 4, 5, 6, 7 }
4. filter(predicate) : Filters this datset according to predicate 过滤符合条件的数据
5. from_generator(): Creates a Dataset whose elements are generated by generator 自己生成数据
6. from_sparse_tensor_slices(sparse_tensor): 由sparse_tensor指明的tensor组成数据
7. from_tensor_slices(tensors): Creates a Dataset whose elements are slices of the given tensors
8. from_tensors(tensors): Creates a Dataset with a single element, comprising the given tensors
9. list_files(file_pattern): A dataset of all files matching a pattern
10. make_initializable_iterator(): Creates an Iterator for enumerating the elements of this dataset.
Note: The returned iterator will be in an uninitialized state, and you must run the iterator.initializer operation before using it:
1 dataset = ... 2 iterator = dataset.make_initializable_iterator() 3 # ... 4 sess.run(iterator.initializer)
11. make_one_shot_iterator(): Creates an Iterator for enumerating the elements of this dataset.
Note: The returned iterator will be initialized automatically. A "one-shot" iterator does not currently support re-initialization.
12.map(map_func,num_parallel_calls=None): Maps map_func across this dataset
13. range(*args): Creates a Dataset of a step-separated range of values.
1 Dataset.range(5) == [0, 1, 2, 3, 4] 2 Dataset.range(2, 5) == [2, 3, 4] 3 Dataset.range(1, 5, 2) == [1, 3] 4 Dataset.range(1, 5, -2) == [] 5 Dataset.range(5, 1) == [] 6 Dataset.range(5, 1, -2) == [5, 3]
14. repeat(count=None): Repeats this dataset count times.
15. shard(num_shards,index): Creates a Dataset that includes only 1/num_shards of this dataset, is useful when running distributed training.
1 d = tf.data.TFRecordDataset(FLAGS.input_file) #从一个文件中读取 2 d = d.shard(FLAGS.num_workers, FLAGS.worker_index) 3 d = d.repeat(FLAGS.num_epochs) 4 d = d.shuffle(FLAGS.shuffle_buffer_size) 5 d = d.map(parser_fn, num_parallel_calls=FLAGS.num_map_threads)
1 d = Dataset.list_files(FLAGS.pattern) #多个文件 2 d = d.shard(FLAGS.num_workers, FLAGS.worker_index) 3 d = d.repeat(FLAGS.num_epochs) 4 d = d.shuffle(FLAGS.shuffle_buffer_size) 5 d = d.repeat() 6 d = d.interleave(tf.data.TFRecordDataset, 7 cycle_length=FLAGS.num_readers, block_length=1) 8 d = d.map(parser_fn, num_parallel_calls=FLAGS.num_map_threads)
16. shuffle(buffer_size,seed=None,reshuffle_each_iteration=None): Randomly shuffles the elements of this dataset.
17. zip(datasets): Creates a Dataset by zipping together the given datasets.
1 # NOTE: The following examples use `{ ... }` to represent the 2 # contents of a dataset. 3 a = { 1, 2, 3 } 4 b = { 4, 5, 6 } 5 c = { (7, 8), (9, 10), (11, 12) } 6 d = { 13, 14 } 7 8 # The nested structure of the `datasets` argument determines the 9 # structure of elements in the resulting dataset. 10 Dataset.zip((a, b)) == { (1, 4), (2, 5), (3, 6) } 11 Dataset.zip((b, a)) == { (4, 1), (5, 2), (6, 3) } 12 13 # The `datasets` argument may contain an arbitrary number of 14 # datasets. 15 Dataset.zip((a, b, c)) == { (1, 4, (7, 8)), 16 (2, 5, (9, 10)), 17 (3, 6, (11, 12)) } 18 19 # The number of elements in the resulting dataset is the same as 20 # the size of the smallest dataset in `datasets`. 21 Dataset.zip((a, d)) == { (1, 13), (2, 14) }
tf.data.FixedLengthRecordDataset
A Dataset of fixed-length records from one or more binary files
Inherits From: Dataset
Method和Dataset都一样,就是__init__函数不一样
1 __init__( 2 filenames, 3 record_bytes, 4 header_bytes=None, 5 footer_bytes=None, 6 buffer_size=None 7 )

tf.data.Iterator
Represents the state of iterating through a Dataset
Properties: initializer, output_shapes, output_types
Method: Creates a new iterator from the given iterator resource
1 __init__( 2 iterator_resource, 3 initializer, 4 output_types, 5 output_shapes 6 )
Note: Most users will not call this initializer directly, and will instead use Dataset.make_initializable_iterator() orDataset.make_one_shot_iterator().
2. get_next(name=None): Returns a nested structure of tf.Tensor containing the next element
3. make_initializer(dataset,name=None): Returns a tf.Operation that initializes this iterator on dataset.
tf.data.TFRecordDataset
A Dataset comprising records from one or more TFRecord files
Inherits From: Dataset method和Dataset一样
1 __init__( 2 filenames, 3 compression_type=None, 4 buffer_size=None 5 )
这个方法提取出的是tf.train.Example格式的数据
1 # Transforms a scalar string `example_proto` into a pair of a scalar string and 2 # a scalar integer, representing an image and its label, respectively. 3 def _parse_function(example_proto): 4 features = {"image": tf.FixedLenFeature((), tf.string, default_value=""), 5 "label": tf.FixedLenFeature((), tf.int32, default_value=0)} 6 parsed_features = tf.parse_single_example(example_proto, features) 7 return parsed_features["image"], parsed_features["label"] 8 9 # Creates a dataset that reads all of the examples from two files, and extracts 10 # the image and label features. 11 filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] 12 dataset = tf.data.TFRecordDataset(filenames) 13 dataset = dataset.map(_parse_function)
tf.data.TextLineDataset
A Dataset comprising lines from one or more text files
Inherits From: Dataset method 和Dataset一样
1 __init__( 2 filenames, 3 compression_type=None, 4 buffer_size=None 5 )
Datset API导入
tf1.3 tf.contrib.data.Dataset
tf1.4 tf.data.Dataset
Dataset和Iterator
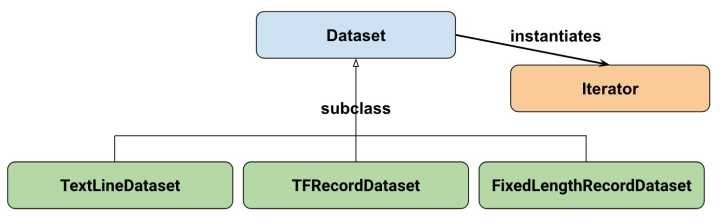
只需要关注两个最重要的基础类: Dataset he Iterator
Dataset可以看作是相同类型“元素”的有序列表,单个“元素”可以使向量,字符串,图片甚至是tuple或者dict
如下为非eager模式的每个元素为数字的Dataset的例子:
1 import tensorflow as tf 2 import numpy as np 3 4 dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0])) 5 6 iterator = dataset.make_one_shot_iterator() 7 one_element = iterator.get_next() 8 with tf.Session() as sess: 9 for i in range(5): 10 print(sess.run(one_element))
输出为1.0到5.0
iterator = dataset.make_one_shot_iterator()从dataset中实例化了一个Iterator,这个Iterator是一个“one shot iterator”,即只能从头到尾读取一次。
one_element = iterator.get_next()表示从iterator里取出一个元素
1 dataset=tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5,2))) 2 3 dataset = tf.data.Dataset.from_tensor_slices( 4 { 5 "a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]), 6 "b": np.random.uniform(size=(5, 2)) 7 })
这时函数会分别切分"a"中的数值以及"b"中的数值,最终dataset中的一个元素就是类似于{"a": 1.0, "b": [0.9, 0.1]}的形式。
对Dataset中的元素做变换: Transformation
一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
(1) map
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值加1:
1 dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0])) 2 dataset = dataset.map(lambda x: x + 1) # 2.0, 3.0, 4.0, 5.0, 6.0
(2) batch
batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为32的batch:
1 dataset=dataset.batch(32)
(3) shuffle
shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小:
1 dataset=dataset.shuffle(buffer_size=10000)
(4) repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:
1 dataset=dataset.repeat(5)
如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常:
1 dataset=dataset.repeat()
例子:
1 #函数的功能时将filename对应的图片文件读进来,并缩放到统一的大小 2 def _parse_function(filename, label): 3 image_string = tf.read_file(filename) 4 image_decoded = tf.image.decode_image(image_string) 5 image_resized = tf.image.resize_images(image_decoded, [28, 28]) 6 return image_resized, label 7 8 # 图片文件的列表 9 filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...]) 10 # label[i]就是图片filenames[i]的label 11 labels = tf.constant([0, 37, ...]) 12 13 # 此时dataset中的一个元素是(filename, label) 14 dataset = tf.data.Dataset.from_tensor_slices((filenames, labels)) 15 16 # 此时dataset中的一个元素是(image_resized, label) 17 dataset = dataset.map(_parse_function) 18 19 # 此时dataset中的一个元素是(image_resized_batch, label_batch) 20 dataset = dataset.shuffle(buffersize=1000).batch(32).repeat(10)
注意,先shuffle,再batch,再repeat
Dataset的其他创建方法
-
tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
-
tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
-
tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
更多类型的Iterator
在非Eager模式下,最简单的创建Iterator的方法就是通过dataset.make_one_shot_iterator()来创建一个one shot iterator。除了这种one shot iterator外,还有三个更复杂的Iterator,即:
-
initializable iterator
-
reinitializable iterator
-
feedable iterator
initializable iterator必须要在使用前通过sess.run()来初始化。使用initializable iterator,可以将placeholder代入Iterator中,这可以方便我们通过参数快速定义新的Iterator。一个简单的initializable iterator使用示例:
1 limit = tf.placeholder(dtype=tf.int32, shape=[]) 2 3 dataset = tf.data.Dataset.from_tensor_slices(tf.range(start=0, limit=limit)) 4 5 iterator = dataset.make_initializable_iterator() 6 next_element = iterator.get_next() 7 8 with tf.Session() as sess: 9 sess.run(iterator.initializer, feed_dict={limit: 10}) 10 for i in range(10): 11 value = sess.run(next_element) 12 assert i == value
此时的limit相当于一个“参数”,它规定了Dataset中数的“上限”。
initializable iterator还有一个功能:读入较大的数组。
在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中。当array很大时,会导致计算图变得很大,给传输、保存带来不便。这时,我们可以用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样就可以避免把大数组保存在图里,示例代码为(来自官方例程):
1 # 从硬盘中读入两个Numpy数组 2 with np.load("/var/data/training_data.npy") as data: 3 features = data["features"] 4 labels = data["labels"] 5 6 features_placeholder = tf.placeholder(features.dtype, features.shape) 7 labels_placeholder = tf.placeholder(labels.dtype, labels.shape) 8 9 dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder)) 10 iterator = dataset.make_initializable_iterator() 11 sess.run(iterator.initializer, feed_dict={features_placeholder: features, 12 labels_placeholder: labels})
在非Eager模式下,Dataset中读出的一个元素一般对应一个batch的Tensor,我们可以使用这个Tensor在计算图中构建模型。
使用例子:
1 filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] 2 dataset = tf.data.TFRecordDataset(filenames) 3 dataset = dataset.map(...)
dataset = datset.shuffle(buffer_size=10000) 4 dataset = dataset.batch(32)
dataset = datset.repeat() 5 iterator = dataset.make_initializable_iterator() 6 next_element = iterator.get_next() 7 8 # Compute for 100 epochs. 9 for _ in range(100): 10 sess.run(iterator.initializer) 11 while True: 12 try: 13 sess.run(next_element) 14 except tf.errors.OutOfRangeError: 15 break 16 17 # [Perform end-of-epoch calculations here.]
Using high-level APIs
1 filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] 2 dataset = tf.data.TFRecordDataset(filenames) 3 dataset = dataset.map(...) 4 dataset = dataset.shuffle(buffer_size=10000) 5 dataset = dataset.batch(32) 6 dataset = dataset.repeat(num_epochs) 7 iterator = dataset.make_one_shot_iterator() 8 9 next_example, next_label = iterator.get_next() 10 loss = model_function(next_example, next_label) 11 12 training_op = tf.train.AdagradOptimizer(...).minimize(loss) 13 14 with tf.train.MonitoredTrainingSession(...) as sess: 15 while not sess.should_stop(): 16 sess.run(training_op)
To use a Dataset in the input_fn of a tf.estimator.Estimator, we also recommend using Dataset.make_one_shot_iterator(). For example:
1 def dataset_input_fn(): 2 filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] 3 dataset = tf.data.TFRecordDataset(filenames) 4 5 # Use `tf.parse_single_example()` to extract data from a `tf.Example` 6 # protocol buffer, and perform any additional per-record preprocessing. 7 def parser(record): 8 keys_to_features = { 9 "image_data": tf.FixedLenFeature((), tf.string, default_value=""), 10 "date_time": tf.FixedLenFeature((), tf.int64, default_value=""), 11 "label": tf.FixedLenFeature((), tf.int64, 12 default_value=tf.zeros([], dtype=tf.int64)), 13 } 14 parsed = tf.parse_single_example(record, keys_to_features) 15 16 # Perform additional preprocessing on the parsed data. 17 image = tf.decode_jpeg(parsed["image_data"]) 18 image = tf.reshape(image, [299, 299, 1]) 19 label = tf.cast(parsed["label"], tf.int32) 20 21 return {"image_data": image, "date_time": parsed["date_time"]}, label 22 23 # Use `Dataset.map()` to build a pair of a feature dictionary and a label 24 # tensor for each example. 25 dataset = dataset.map(parser) 26 dataset = dataset.shuffle(buffer_size=10000) 27 dataset = dataset.batch(32) 28 dataset = dataset.repeat(num_epochs) 29 iterator = dataset.make_one_shot_iterator() 30 31 # `features` is a dictionary in which each value is a batch of values for 32 # that feature; `labels` is a batch of labels. 33 features, labels = iterator.get_next() 34 return features, labels
注意顺序呀:
map -> shuffle -> batch -> repeat
如果不shuffle 就 map -> repeat -> batch