MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
select city,name,age from t where city='杭州' order by name limit 1000 ;
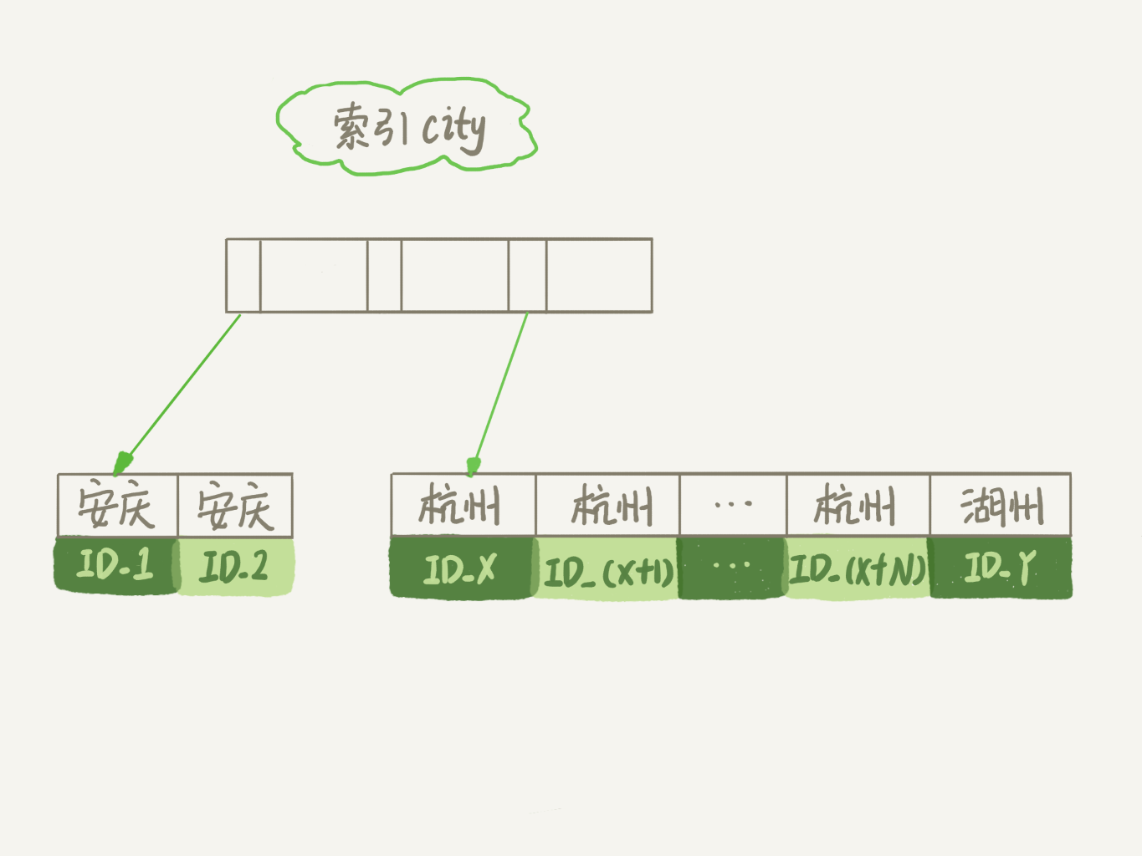
通常情况下,这个语句执行流程如下所示 :
初始化 sort_buffer,确定放入 name、city、age 这三个字段;
从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
从索引 city 取下一个记录的主键 id;
重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
对 sort_buffer 中的数据按照字段 name 做快速排序;
按照排序结果取前 1000 行返回给客户端。
确定一个排序语句是否使用了临时文件。
/* 打开optimizer_trace,只对本线程有效 */ SET optimizer_trace='enabled=on'; /* @a保存Innodb_rows_read的初始值 */ select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 执行语句 */ select city, name,age from t where city='杭州' order by name limit 1000; /* 查看 OPTIMIZER_TRACE 输出 */ SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`G /* @b保存Innodb_rows_read的当前值 */ select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 计算Innodb_rows_read差值 */ select @b-@a;
如果 MySQL 认为排序的单行长度太大会怎么做呢?
