问题:我用 sqoop 把 Mysql 中的数据导入到 hive,使用了--delete-target-dir --hive-import --hive-overwrite 等参数,执行了两次。 mysql 中只有 20 条记录。在 hive shell 中,查询导入到的表的记录,得到结果 20 条,是对的。

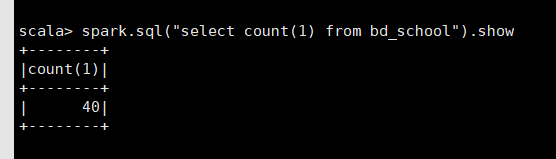
然而在 spark-shell 中,使用 spark sql 得到的结果却是 40 条。
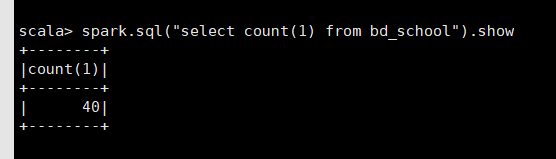
又执行了一次 sqoop 的导入,hive 中仍然查询到 20 条,而 spark shell 中却得到了 60 条!!
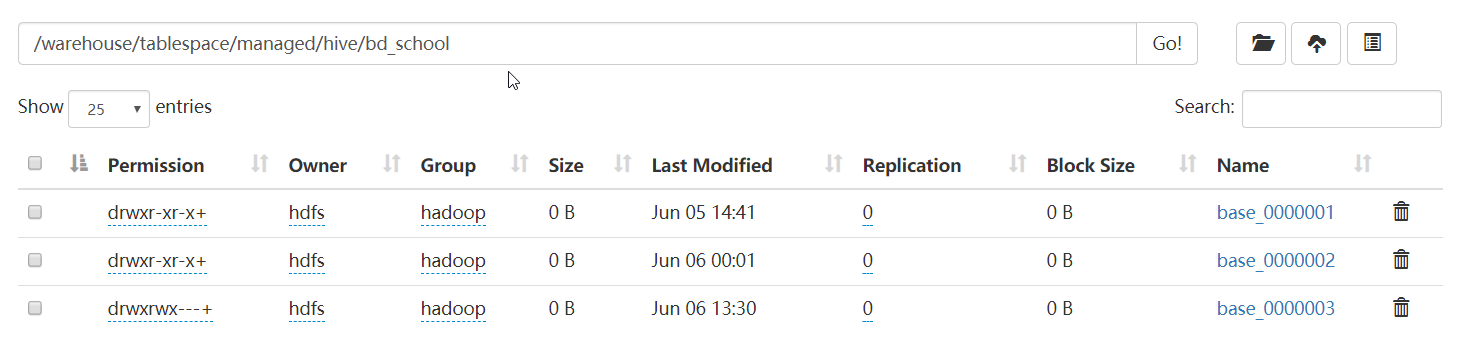
查了一下 HDFS 上,结果发现有 3 个文件
后来在网上看到有说 Hortonworks 中,用 Ambari 部署的 hive(V3.0),默认是开启 ACID 的,Spark 不支持 hive 的 ACID。更改 hive 的如下参数,关闭 ACID 功能。
hive.strict.managed.tables=false hive.create.as.insert.only=false metastore.create.as.acid=false
删除 hive 中的表,重新导入。
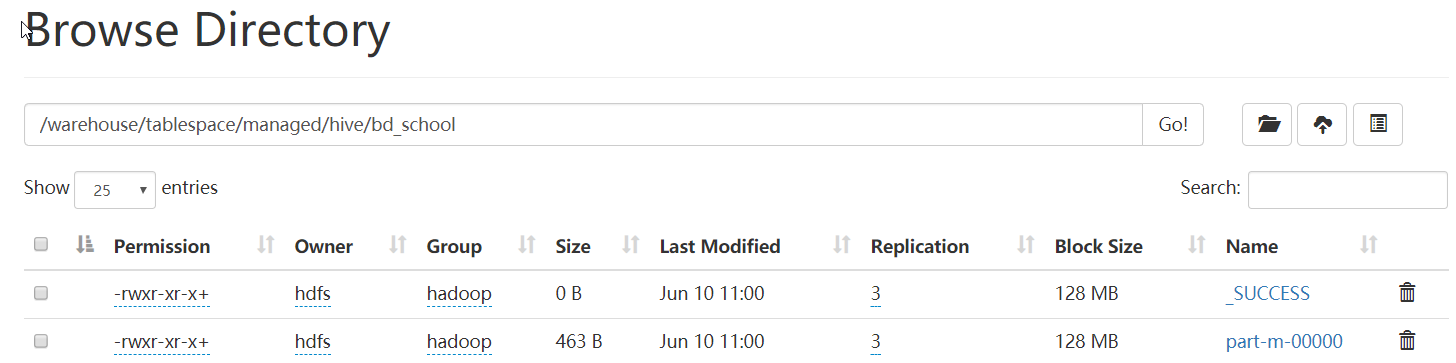
可以看到,表目录下的文件名变了,不是原来的 base_ 开头的了。
用 overwrite 的方式导入多次,也还是只有这两个文件,spark sql 读取的数据也没有出现翻倍的现象。
至此,问题算是解决了。但是不明白为什么 hive 开启 ACID 时,尽管表目录下有多个文件,但是 hive shell 能知道到底哪个是正确的,而 spark 则不知道。估计只有研究源码才能解决问题了。