1 查看网页结构
(1)确定需要抓取的字段
电影名称
电影主演
电影上映时间
电影评分
(2) 分析页面结构
按住f12------->点击右上角(如下图2)---->鼠标点击需要观察的字段
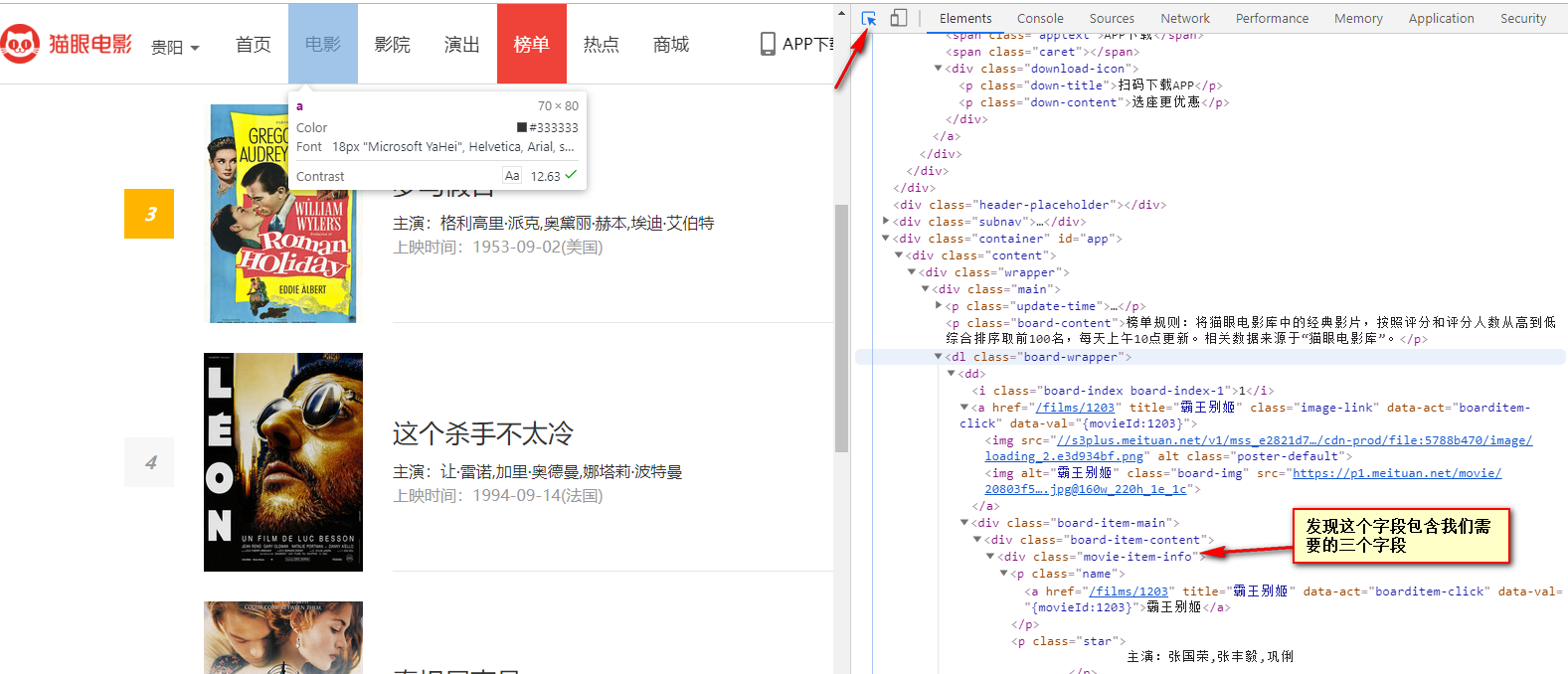
(3)BeautifulSoup解析源代码并设置过滤属性
1 soup = BeautifulSoup(htmll, 'lxml')
2 Movie_name = soup.find_all('div',class_='movie-item-info')
3 Movie_Score1=soup.find_all('p',class_='score')
(4)调试查看过滤属性是否正确

(5)提取对应字段


1 for cate,score in zip(Movie_name,Movie_Score1): 2 data={} 3 movie_name1 = cate.find('a').text.strip(' ') 4 data['title']=movie_name1 5 movie_actor = cate.find_all("p")[1].text.replace(" "," ").strip() 6 data['actors']=movie_actor 7 movie_time=cate.find_all("p")[2].text.strip(' ').strip() 8 data['data']=movie_time 9 movie_score1=score.find_all("i")[0].string 10 movie_score2=score.find_all("i")[1].string 11 movie_score=movie_score1+movie_score2 12 data['score'] = movie_score 13 name = movie_name1 + " "+movie_actor+" " + movie_time+" "+movie_score 14 DATA.append(name) 15 with open('Movie1.txt', 'a+') as f: 16 f.write(" {}".format(name))
(6)翻页爬取
如下图,按照1 2 3步骤,发现页数是有这样子的规律。比如offset=0 offset=10......
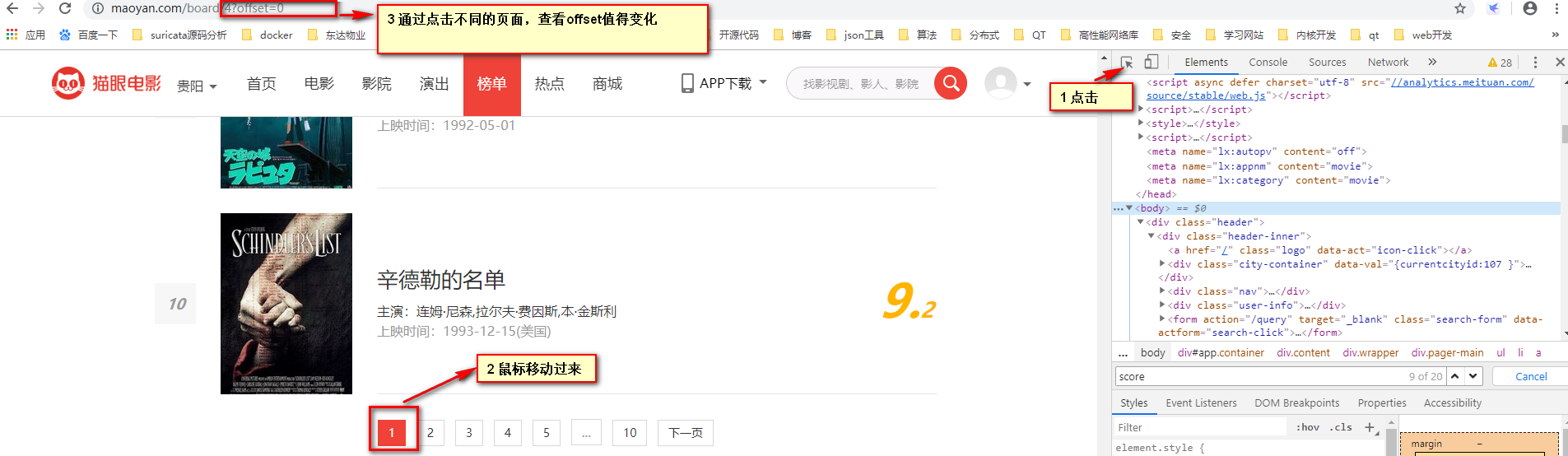

2 存储excel
1 for datas in DATA: 2 datas=datas.split(' ')#因为我之前解析字段拼接的时候就是采用 分割 3 print(len(datas)) 4 print(datas) 5 for j in range(len(datas)):#列表中的每一项都包含按照 分割的字段 6 print(j) 7 sheet1.write(i, j, datas[j]) 8 i = i + 1 9 f.save("d.xls") # 保存文件
3 结果
