我是以HashMap类里面从头到尾的顺序讲解。其中掺杂了自己的个人理解,文字就会比较多,希望大家能耐心看下去,一起探讨探讨.

首先HashMap 继承 AbstractMap类,实现了Map,Cloneable,Sericalizable接口。
- 这里实现Sericalizable接口 就是个标志,标志了该类对象可以序列化。
- 序列化:将对象写入到IO流中
- 反序列化:从IO流中恢复对象
- 意义:序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
- 使用场景:所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。通常建议:程序创建的每个JavaBean类都实现Serializeable接口

因为在计算key的hash值时 return (h = key.hashCode()) ^ (h >>> 16);
在这里是用key的hashcode值的 高16和低16位比较,要2的幂次方 (这样计算出来的hash值更均匀些,在后面计算数组下角标的时候,减少hash冲突)
2进制的运算也更快点(其实计算机只会一个加法运算,所有的运算都是建立在2进制的加1 加1的操作上而形成的一种算法),
这里的 ‘>>> ’是无符号右移,意思就是bit位无符号右移,左面空的就补零。 ' ^ ' 异或 符号,意思就是在比较bit位的时候 1 和 0 这种比较才等于 1 ,其他都为0
至于为什么默认是16 :个人认为jdk设计师做过一个统计,觉得new hashMap的时候 所用到的容量的平均值且为2的幂次方的 就是16(也可能就是java开发的经验),
估计在实际开发中 如果设置8 或者4 的时候就小了 会一直重新扩容影响效率,超过16太大了又会浪费空间。(数据结构和算法的选择往往都要兼顾时间与空间,取其中间做平衡,个人见解)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

这个属性是默认的加载因子(其实应该叫加载系数,加载因子是个什么鬼东西,数学物理老师会哭)
这个是用来计算阈值的 threshold = loadFactor * capacity,当put新的数据的时候 会判断size有没有大于threshold ,如果大于就会执行resize ()
其实还是用来判断树化的概率的。
那为什么是0.75呢, 这是因为取太小的话 有可能会频繁触发扩容,影响效率。
如果取太大的话,那就需要在接近数组容量大小的时候才会扩容,这样就会增加hash碰撞的概率,还有可能会在数据很多的情况下自动扩容,遍历数据加上红黑树调节会影响效率(我看了一个文章说太大会浪费空间,我不认同,你都要扩容两倍,没有浪费一说,我的个人见解)。所以取0.75就是一种折中的方法。
假设长度16,那么当存12 = 16 * 0.75个数据时,一个链表超过8,出现树化的的概率为0.00000006,8是树化的阈值。因为树比链表的遍历快,但是treeNode的结点大小是Node的两倍,,所以jdk开发要平衡树和链表的性能,所以用泊松分布算出树出现的概率,用0.75的时候就平衡了这个空间和时间。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------

treeify_threshold:默认树化的阈值,当链表数据大于8个的时候会执行 treeifyBin() ,把链表树化。
那为什么是8呢,这涉及到红黑树的时间复杂度 logn 8的长度就是3 ,相对于链表,这里红黑树更快,数据少的的时候链表更快,结合树化操作的效率,平均下来还是8更好。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
untreeify_threshold:解树化的阈值(就是树结构转链表,当Node节点被remove的时候),Node小于6的时候会执行unteeify()方法。为什么不是8,还是考虑到了解树的一个操作效率和遍历的效率的平衡。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
最小的树化容量,官方解释说是如果数据过多的时候,扩容时存储箱扩容不能小于 4 * treeify_capacity ,避免冲突。
因为在![]()
这里会根据数组长度是否小于最小存储器容量。小于才会resize();
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里hash(key)就是计算key值得hash值,是用key的hashcode值(Object对象里面的hashcode方法)
异或 hashcode的高16位。保留高16的特性,减少hash冲突。
为什么要右移16位?
其实是为了减少碰撞,进一步降低hash冲突的几率。int类型的数值是4个字节的,右移16位异或可以同时保留高16位于低16位的特征
为什么要异或运算?
首先将高16位无符号右移16位与低十六位做异或运算。如果不这样做,而是直接做&运算那么高十六位所代表的部分特征就可能被丢失
将高十六位无符号右移之后与低十六位做异或运算使得高十六位的特征与低十六位的特征进行了混合得到的新的数值中就高位与低位的信息都被保留了 ,
而在这里采用异或运算而不采用& ,| 运算的原因是
异或运算能更好的保留各部分的特征,
如果采用&运算计算出来的值会向0靠拢, &运算的时候只有 1 & 1 的时候才为 1 ,其他情况都是 0 所以0的概率大
采用|运算计算出来的值会向1靠拢 |运算的时候只有 0 | 0 的时候才为 0 ,其他情况都是 1 所以1的概率大
采用^运算 右移16位之后高位补的都是0 ,原来的高16 和都是0的高16位异或就是原来的高16位,只有 1^0或者0^1的时候是1 其他是0,概率差不多。
-------------------------------------------------------------------
/**
* 如果对象x的类是C,如果C实现了Comparable<C>接口,那么返回C,否则返回null
*/
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // 如果x是个字符串对象
return c; // 返回String.class
/*
* 为什么如果x是个字符串就直接返回c了呢 ? 因为String 实现了 Comparable 接口,可参考如下String类的定义
* public final class String implements java.io.Serializable, Comparable<String>, CharSequence
*/
// 如果 c 不是字符串类,获取c直接实现的接口(如果是泛型接口则附带泛型信息)
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) { // 遍历接口数组
// 如果当前接口t是个泛型接口
// 如果该泛型接口t的原始类型p 是 Comparable 接口
// 如果该Comparable接口p只定义了一个泛型参数
// 如果这一个泛型参数的类型就是c,那么返回c
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) && (as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
// 上面for循环的目的就是为了看看x的class是否 implements Comparable<x的class>
}
}
return null; // 如果c并没有实现 Comparable<c> 那么返回空
}
/**
* 如果x所属的类是kc,返回k.compareTo(x)的比较结果
* 如果x为空,或者其所属的类不是kc,返回0
*/
@SuppressWarnings({"rawtypes","unchecked"}) // for cast to Comparable
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}
如果两者不具有compare的资格,或者compare之后仍然没有比较出大小。那么就要通过一个决胜局再比一次,这个决胜局就是tieBreakOrder方法。
/**
* 用这个方法来比较两个对象,返回值要么大于0,要么小于0,不会为0
* 也就是说这一步一定能确定要插入的节点要么是树的左节点,要么是右节点,不然就无法继续满足二叉树结构了
* 先比较两个对象的类名,类名是字符串对象,就按字符串的比较规则
* 如果两个对象是同一个类型,那么调用本地方法为两个对象生成hashCode值,再进行比较,hashCode相等的话返回-1
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}

tableSizeFor方法是大家new HashMap()的时候是不是没指定容量大小,还有些人new HashMap(23)时设置一个不是2的幂次方的容量的时候用这个方法指定一个容量。
假设这是的cap 是23 所以 int n = cap - 1 == 22;
这里 n | = n >>> 1; 不会有人看不懂把,不会吧,不会吧。 就是 n = n | n >>> 1;
所以这里是,
n = n | n >>> 1;
n = n | n >>> 2;
n = n | n >>> 4;
n = n | n >>> 8;
n = n | n >>> 16;
这里我一开始就是会忘了 n是原来的n和n无符号右移的 n做完 ‘或’运算之后的n,每次n都被重新赋值了。
开始n是22,22的二进制就是 1 0 1 1 0
当无符号右移一位就是 0 1 0 1 1
这两个 ‘|’ 判断,n就变成了 1 1 1 1 1 。要知道 ‘ | ’运算的时候二进制中只要有 1 ,最后就是 1。
所以这里右移一位 和原来做' | ' 运算 ,高位第一位和第二位就一定是1,
最开始第一个肯定是1是,你右移了一位,在和原来‘|‘ 运算,第二位肯定也是1了,现在是不是保证了 第一位和第二位 是1 。
这时候的 n 的高 1 位和 2位 肯定是 1 ,这时候的n在无符号右移两位 和 n 比较, 同理是不是 就能保证 前 第 1 ,2,3,4都是1了
同理这么一直 右移 4 位 算完之后 右移 8位, 右移16位 算完之后肯定 把原来的n的二进制 都变成了 1 1 1 1 1,最后加一 ,就一定是2的n次幂了。
这里可以看到右移了32位(因为int型数据 4byte,1byte有8 bit,所以int数据有32bit)
能力有限 讲不了更详细了(------------------------------------------)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
table的长度 = capacity;
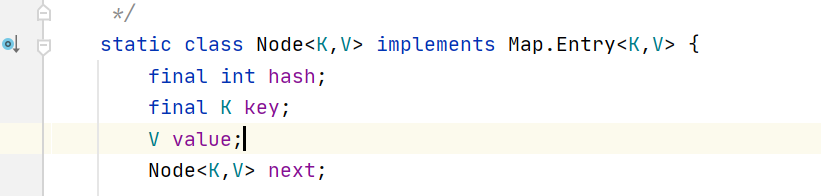
大家应该都知道 hashmap是用数组存储链表头结点 或 红黑树的root结点的吧。(就是很多文章中说到的桶,而这里就是用Node数组实现的这个概念)
不会不知道吧,不会吧,不会吧,不会吧。
因为链表用Node对象串起来实现的,而红黑树结构靠TreeNode对象实现的,treeNode 继承了LinkedHashMap.Entry 而 Entry extend Hashmap.Node,所以TreeNode也能放到Node数组中。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
size在添加数据成功之后就会 size++;所以seiz存的是节点的数量值。
size:存储了Node对象加TreeNode个数。当你hashMap新增了一个Node对象时候,就是put.(K,V)的时候,会看当前size是不是等于thershould (就是阈值,临界值)= loadFractor * capcity
如果你添加一个Node后会超过这个阈值,那就要自动扩容了,执行resize();
这里再讲下 transient 关键字,用途就是当对象序列化存储的时候 被这个关键字修饰的属性值不会存储进去,比如密码之类的敏感属性。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
modeCount的作用?
modCount 属性值是存储hashMap操作数的值,在源码中put方法 remove方法等一些方法执行的时候 modCount都会加1
因为hashMap和ArrayList一样都实现了迭代器,
这时候这个线程在这里走迭代流程,但另一个线程在走hashMap的put后remove操作,增删了Node,这时候两个线程针对同一个hashMap对象操作了,、不能保证数据一致性。
![]()
但是走迭代器的时候迭代器中有一个expectedModCount属性,当用迭代器的时候, expectedModCount 会赋值等于 modCount
![]()
所以迭代的时候会判断expectedModCount 是否等于 modCount,
比如当有线程在迭代这个hashmap对象,另一个线程走了一个hashmap的put操作,modCount加了一个1,但是expectedModCount还是等于原来的modeCount
是不是两个不相等了,所以迭代的时候 迭代的线程走到这个判断的时候 如果不相等就知道hashmap对象有另一个线程操作且改变了数据,所以抛出异常 。
迭代的hashmap对象的数据都可能改变了,迭代的次数就有可能已经改变了。终止迭代。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
threshold (阈值)= loadFactor * capcity
当size 大于 threshold的时候会执行 resize()
注意:这里是用size判断是否大于threshold的,也就是说是用节点的个数来判断的,不是用capacity的值,而Node<k,v>[] table 数组容量=capacity;
所以这里判断是否自动扩容,根据的不是数组被占用的个数来判断的,而是根据size(也就是Node加TreeNode节点的个数)
为什么这么设计,为什么不用数组的长度呢:因为很多地方都要判断是否需要自动扩容,如果用table的容量判断就要遍历数组
看有几个被占用了在判断是否需要扩容。用size就省掉了遍历。但是我可以再设置一个属性来记录当数组table[i]第一次被占用的时候记录加一次.
到这我又感觉jdk开发 估计并不是只为了省去遍历的效率。有可能是怕有一种情况出现,就是新增加的数据一直hash值冲突,一直往同一个链表上新增,
这样就会数据越来越多 又不会触发自动扩容,就会导致一些树结构上面有很多数据(因为链表达到8之后会自动树化),而且每次新增一个数据的时候树都有可能要自动调节(自旋 维持左右分支平衡),这样效率就会非常慢,所以jdk开发 就是用空间换时间的想法,不用table长度而用size来判断什么时候自动扩容。(个人看法,也没有说明)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
![]()
loadFactor 就是加载因子(加载系数),用来计算阈值。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
java8及以上版本的HashMap中有段注释的解释:
- 这一段注释的内容和目的都是为了解释在java8 HashMap中引入Tree Bin(也就是放入数据的每个数组bin从链表node转换为red-black tree node)的原因
- 原注释如上图划线部分:Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use(see TREEIFY_THRESHOLD).
- TreeNode虽然改善了链表增删改查的性能,但是其节点大小是链表节点的两倍
- 虽然引入TreeNode但是不会轻易转变为TreeNode(如果存在大量转换那么资源代价比较大),根据泊松分布来看转变是小概率事件,性价比是值得的
- 泊松分布是二项分布的极限形式,两个重点:事件独立、有且只有两个相互对立的结果
- 泊松分布是指一段时间或空间中发生成功事件的数量的概率
- 对HashMap table[]中任意一个bin来说,存入一个数据,要么放入要么不放入,这个动作满足二项分布的两个重点概念
- 对于HashMap.table[].length的空间来说,放入0.75*length个数据,某一个bin中放入节点数量的概率情况如上图注释中给出的数据(表示数组某一个下标存放数据数量为0~8时的概率情况)
- 举个例子说明,HashMap默认的table[].length=16,在长度为16的HashMap中放入12(0.75*length)个数据,某一个bin中存放了8个节点的概率是0.00000006
- 扩容一次,16*2=32,在长度为32的HashMap中放入24个数据,某一个bin中存放了8个节点的概率是0.00000006
- 再扩容一次,32*2=64,在长度为64的HashMap中放入48个数据,某一个bin中存放了8个节点的概率是0.00000006
所以,当某一个bin的节点大于等于8个的时候,就可以从链表node转换为treenode,其性价比是值得的。
这里就是HashMap所有的属性值。后面一篇在讲其中的方法。急急急,如果觉得这篇博客帮助到你了,给个推荐让更多人看到呗。