File类:
访问文件和目录:
File类可以使用文件路径字符串来创建File实例,该文件路径字符串既可以是绝对路径,也可以是相对路径。默认情况下,系统总是依据用户的工作路径来解释相对路径,这
个路径由系统属性“user.dir”指定,通常也就是运行Java虚拟机时所在的路径。
File类提供了很多方法来操作文件和目录:
访问文件名相关的方法:
1.String getName():返回此File对象所表示的文件名或路径名(若是路径,则返回最后一级子路径名)。
2.String getPath():返回次File对象所对应的路径名
3.File getAbsoluteFile():返回此File对象的绝对路径
4.String getAbsolutePath():返回此File对象所对应的绝对路径名。
5.String getParent():返回此File对象所对应目录(最后一级子目录)的父目录名
6.boolean renameTo(File newName):重命名此File对象所对应的文件或目录,若重命名成功,则返回true,否则返回false
文件检测相关的方法:
1.boolean exists():判断File对象所对应的文件或目录是否存在
2.boolean canWrite():判断File对象所对应的文件和目录是否可写
3.boolean canRead():判断File对象所对应的文件和目录是否可读
4.boolean isFile():判断File对象所对应的是否是文件,而不是目录
5.boolean isDirectory():判断File对象所对应的是否是目录,而不是文件
6.boolean isAbsolute():判断File对象所对应的文件或目录是否是绝对路径。该方法消除了不同平台的差异,可直接判断File对象是否为绝对路径。
获取常规文件信息:
1.long lastModified():返回文件的最后修改时间
2.long length():返回文件内容的长度
文件操作相关的方法:
1.boolean createNewFile():当此File对象所对应的文件不存在时,该方法将新建一个该File对象所指定的新文件,若创建成功返回true,否则返回false
2.boolean delete():删除File对象所对应的文件或路径
3.static File createTempFile(String prefix, String suffix):在默认的临时文件目录中创建一个临时的空文件,使用给定前缀、系统生成的随机数和给定后缀作为文件名。
File类可以直接调用该方法,prefix参数必须至少3字节长。建议前缀使用一个短的、有意义的字符串,如:hjb、mail。suffix参数可以为null,使用默认的后缀.tmp
4.static File createTempFIle(String prefix, String suffix, File directory):在directory所指定的目录中创建一个临时的空文件,使用给定前缀、系统生成的随机数和给定
后缀作为文件名。
5.void deleteOnExit():注册一个删除钩子,指定当Java虚拟机退出时,删除File对象所对应的文件和目录
目录操作相关的方法:
1.boolean mkdir():创建一个File对象所对应的目录,若创建成功,则返回true,否则返回false。调用该方法时File对象必须对应一个路径,而不是一个文件。
2.String[] list():列出File对象的所有子文件名和路径,返回String[]数组
3.File[] listFiles():列出File对象的所有子文件和路径,返回Flie数组
4.static File[] listRoots():列出系统所有的根路径
下面程序以几个简单的方法来测试以下File类的功能:


1 import java.io.*; 2 /** 3 * Description: 4 * <br/>网站: <a href="http://www.crazyit.org">疯狂Java联盟</a> 5 * <br/>Copyright (C), 2001-2016, Yeeku.H.Lee 6 * <br/>This program is protected by copyright laws. 7 * <br/>Program Name: 8 * <br/>Date: 9 * @author Yeeku.H.Lee kongyeeku@163.com 10 * @version 1.0 11 */ 12 public class FileTest 13 { 14 public static void main(String[] args) 15 throws IOException 16 { 17 // 以当前路径来创建一个File对象 18 File file = new File("."); 19 // 直接获取文件名,输出一点 20 System.out.println(file.getName()); 21 // 获取相对路径的父路径可能出错,下面代码输出null 22 System.out.println(file.getParent()); 23 // 获取绝对路径 24 System.out.println(file.getAbsoluteFile()); 25 // 获取上一级路径 26 System.out.println(file.getAbsoluteFile().getParent()); 27 // 在当前路径下创建一个临时文件 28 File tmpFile = File.createTempFile("aaa", ".txt", file); 29 // 指定当JVM退出时删除该文件 30 tmpFile.deleteOnExit(); 31 // 以系统当前时间作为新文件名来创建新文件 32 File newFile = new File(System.currentTimeMillis() + ".txt"); 33 System.out.println("newFile对象是否存在:" + newFile.exists()); 34 // 以指定newFile对象来创建一个文件 35 newFile.createNewFile(); 36 // 以newFile对象来创建一个目录,因为newFile已经存在, 37 // 所以下面方法返回false,即无法创建该目录 38 newFile.mkdir(); 39 // 使用list()方法来列出当前路径下的所有文件和路径 40 String[] fileList = file.list(); 41 System.out.println("====当前路径下所有文件和路径如下===="); 42 for (String fileName : fileList) 43 { 44 System.out.println(fileName); 45 } 46 // listRoots()静态方法列出所有的磁盘根路径。 47 File[] roots = File.listRoots(); 48 System.out.println("====系统所有根路径如下===="); 49 for (File root : roots) 50 { 51 System.out.println(root); 52 } 53 } 54 }
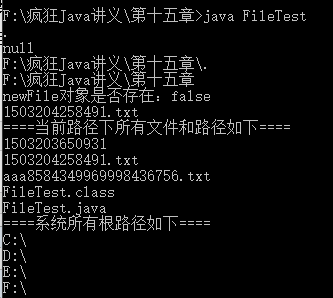
// 以系统当前时间作为新文件名来创建新文件
File newFile = new File(System.currentTimeMillis() + ".txt");
System.out.println("newFile对象是否存在:" + newFile.exists());
上面程序中这两句不懂,为什么明明存在的一个文件,却返回一个false?
文件过滤器:
在File类的list方法中可以接受一个FilenameFilter参数,通过该参数可以只列出符合条件的文件。
FilenameFilter接口里包含了一个accept(File dir, String name)方法,该方法依次对指定File的所有子目录或文件进行迭代,若该方法返回true,则list()方法会列出该子目录
或文件:
1 import java.io.File; 2 3 public class FilenameFilterTest{ 4 public static void main(String[] args){ 5 File file = new File("."); 6 //使用Lambda表达式(目标类型为FilenameFiler)实现文件过滤器 7 //若文件名以.java结尾,或者文件对应一个路径,则返回true 8 String[] nameList = file.list((dir, name) -> name.endsWith(".java") || new File(name).isDirectory()); 9 for(String name : nameList){ 10 System.out.println(name); 11 } 12 } 13 }

字节流和字符流:
1 import java.io.FileInputStream; 2 import java.io.IOException; 3 4 public class FileInputStreamTest { 5 public static void main(String[] args) throws IOException{ 6 //创建字节输入流 7 FileInputStream fis = new FileInputStream("FileInputStreamTest.java"); 8 //创建一个长度为1024的“竹筒” 9 byte[] bbuf = new byte[1024]; 10 //用于保存实际读取的字节数 11 int hasRead = 0; 12 //使用循环来重复“取水”过程 13 while((hasRead = fis.read(bbuf)) > 0){ 14 //取出“竹筒”中的水滴(字节),将字节数组换成字符串输入 15 System.out.print(new String(bbuf, 0, hasRead)); 16 } 17 18 //关闭文件输入流,放在finally块里更安全 19 fis.close(); 20 } 21 }

程序最后关闭文件输入流,程序里打开的文件IO资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显示关闭文件IO资源。也可用try语句自动关闭IO流:
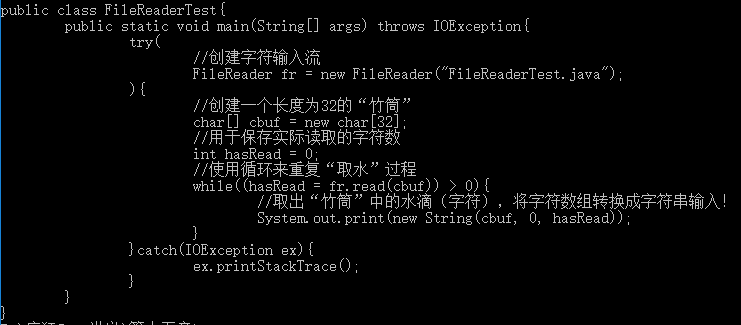
1 import java.io.FileReader; 2 import java.io.IOException; 3 4 public class FileReaderTest{ 5 public static void main(String[] args) throws IOException{ 6 try( 7 //创建字符输入流 8 FileReader fr = new FileReader("FileReaderTest.java"); 9 ){ 10 //创建一个长度为32的“竹筒” 11 char[] cbuf = new char[32]; 12 //用于保存实际读取的字符数 13 int hasRead = 0; 14 //使用循环来重复“取水”过程 15 while((hasRead = fr.read(cbuf)) > 0){ 16 //取出“竹筒”中的水滴(字符),将字符数组转换成字符串输入! 17 System.out.print(new String(cbuf, 0, hasRead)); 18 } 19 }catch(IOException ex){ 20 ex.printStackTrace(); 21 } 22 } 23 }
InputStream和Reader还支持如下几个方法来移动记录指针:
1.void mark(int readAheadLimit):在记录指针当前位置记录一个标记。
2.boolean markSupported():判断此输入流是否支持mark()操作,即是否支持记录标记
3.void reset():将此流的记录指针重新定位到上一次记录标记(mark)的位置
4.long skip(long n):记录指针向前移动n个字节/字符
OutputStream和Writer:
OutputStream和Writer类提供如下方法:
1.void write(int c):将指定的字节/字符输出到输出流中,其中c既可以代表字节,也可以代表字符
2.void write(byte[] / char[] buf):将字节数组/字符数组中的数据输出到指定输出流中
3.void write(byte[] / char[] buf, int off, int len):将字节数组/字符数组中从off位置开始,长度为len的字节/字符书粗到输出流中。
Writer还提供以下两个方法:
1.void write(String str):将str字符串里包含的字符串输出到指定输出流中
2.void write(String str, int off, int len):将str字符串里从off位置开始,长度为len的字符输出到指定输出流中
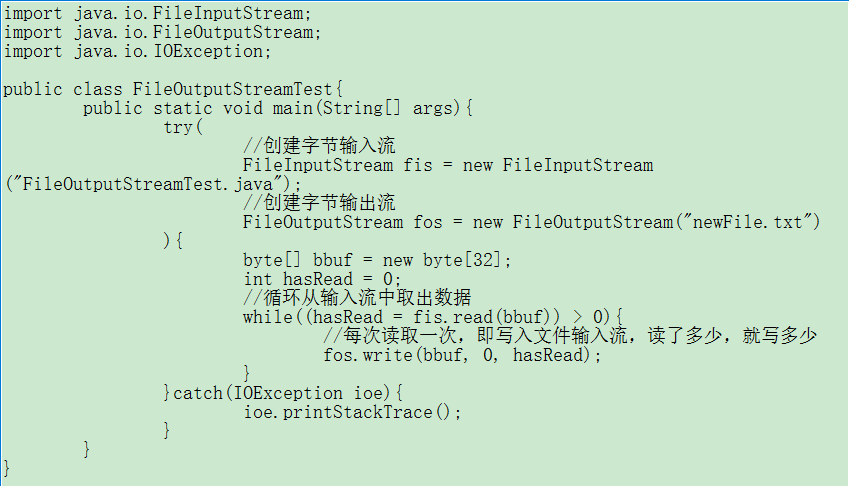
1 import java.io.FileInputStream; 2 import java.io.FileOutputStream; 3 import java.io.IOException; 4 5 public class FileOutputStreamTest{ 6 public static void main(String[] args){ 7 try( 8 //创建字节输入流 9 FileInputStream fis = new FileInputStream("FileOutputStreamTest.java"); 10 //创建字节输出流 11 FileOutputStream fos = new FileOutputStream("newFile.txt") 12 ){ 13 byte[] bbuf = new byte[32]; 14 int hasRead = 0; 15 //循环从输入流中取出数据 16 while((hasRead = fis.read(bbuf)) > 0){ 17 //每次读取一次,即写入文件输入流,读了多少,就写多少 18 fos.write(bbuf, 0, hasRead); 19 } 20 }catch(IOException ioe){ 21 ioe.printStackTrace(); 22 } 23 } 24 }
若希望直接输出字符串内容,则使用Writer会更好:
1 import java.io.FileWriter; 2 import java.io.IOException; 3 4 public class FileWriterTest{ 5 public static void main(String[] args){ 6 try( 7 FileWriter fw = new FileWriter("poem.txt") 8 ){ 9 fw.write("锦瑟 - 李商隐 "); 10 fw.write("锦瑟无端五十弦,一弦一柱思华年。 "); 11 fw.write("庄生晓梦迷蝴蝶,望帝春心托杜鹃。 "); 12 fw.write("沧海月明珠有泪,蓝田日暖玉生烟。 "); 13 fw.write("此情可待成追忆,只是当时已惘然。 "); 14 }catch(IOException ioe){ 15 ioe.printStackTrace(); 16 } 17 } 18 }

处理流的用法:
下面程序使用PrintStream处理刘来包装OutputStream,使用处理流后的输出流在输出时将更加方便:
1 import java.io.FileOutputStream; 2 import java.io.PrintStream; 3 import java.io.IOException; 4 5 public class PrintStreamTest{ 6 public static void main(String[] args){ 7 try( 8 FileOutputStream fos = new FileOutputStream("test.txt"); 9 PrintStream ps = new PrintStream(fos) 10 ){ 11 //使用PrintStream执行输出 12 ps.println("普通字符串"); 13 //直接使用PrintStreamTest输出对象 14 ps.println(new PrintStreamTest()); 15 }catch(IOException ioe){ 16 ioe.printStackTrace(); 17 } 18 } 19 }

1 import java.io.StringReader; 2 import java.io.IOException; 3 import java.io.StringWriter; 4 5 public class StringNodeTest 6 { 7 public static void main(String[] args) 8 { 9 String src = "从明天起,做一个幸福的人 " 10 + "喂马,劈柴,周游世界 " 11 + "从明天起,关心粮食和蔬菜 " 12 + "我有一所房子,面朝大海,春暖花开 " 13 + "从明天起,和每一个亲人通信 " 14 + "告诉他们我的幸福 "; 15 char[] buffer = new char[32]; 16 int hasRead = 0; 17 try( 18 StringReader sr = new StringReader(src)) 19 { 20 // 采用循环读取的访问读取字符串 21 while((hasRead = sr.read(buffer)) > 0) 22 { 23 System.out.print(new String(buffer ,0 , hasRead)); 24 } 25 } 26 catch (IOException ioe) 27 { 28 ioe.printStackTrace(); 29 } 30 try( 31 // 创建StringWriter时,实际上以一个StringBuffer作为输出节点 32 // 下面指定的20就是StringBuffer的初始长度 33 StringWriter sw = new StringWriter()) 34 { 35 // 调用StringWriter的方法执行输出 36 sw.write("有一个美丽的新世界, "); 37 sw.write("她在远方等我, "); 38 sw.write("哪里有天真的孩子, "); 39 sw.write("还有姑娘的酒窝 "); 40 System.out.println("----下面是sw的字符串节点里的内容----"); 41 // 使用toString()方法返回StringWriter的字符串节点的内容 42 System.out.println(sw.toString()); 43 } 44 catch (IOException ex) 45 { 46 ex.printStackTrace(); 47 } 48 } 49 }

转换流:
两个转换流用于实现将字节流转换为字符流,其中InputStreamReader将字节输入流转换为字符输入流,OutputStreamWriter将字节输出流转换为字符输出流。
1 import java.io.InputStreamReader; 2 import java.io.BufferedReader; 3 import java.io.IOException; 4 5 public class KeyinTest 6 { 7 public static void main(String[] args) 8 { 9 try( 10 // 将Sytem.in对象转换成Reader对象 11 InputStreamReader reader = new InputStreamReader(System.in); 12 // 将普通Reader包装成BufferedReader 13 BufferedReader br = new BufferedReader(reader)) 14 { 15 String line = null; 16 // 采用循环方式来一行一行的读取 17 while ((line = br.readLine()) != null) 18 { 19 // 如果读取的字符串为"exit",程序退出 20 if (line.equals("exit")) 21 { 22 System.exit(1); 23 } 24 // 打印读取的内容 25 System.out.println("输入内容为:" + line); 26 } 27 } 28 catch (IOException ioe) 29 { 30 ioe.printStackTrace(); 31 } 32 } 33 }

由于BufferedReader具有一个readLine()方法,可以非常方便依次读入一行内容,所以经常把读取文本内容的输入流包装成BufferedReader,用来方便地读取输入流的文
本内容
推回输入流:
PushbackInputStream和PushbackReader提供了如下三个方法:
1.void unread(byte[] / char[] buf):将一个字节/字符数组内容推回到推回缓冲区里,从而允许重复读取刚刚读取的内容
2.void unread(byte[] / char[] b, int off, int len):将一个字节/字符数组里从off开始,长度为len字节/字符的内容推回到推回缓冲区里,从而重复读取刚刚读取的内容
3.void unread(int b):将一个字节/字符推回到推回缓冲区里,从而允许重复读取刚刚读取的内容。
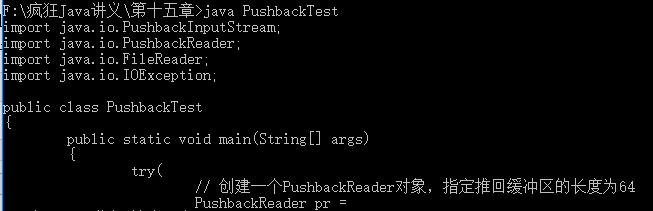
1 import java.io.PushbackInputStream; 2 import java.io.PushbackReader; 3 import java.io.FileReader; 4 import java.io.IOException; 5 6 public class PushbackTest 7 { 8 public static void main(String[] args) 9 { 10 try( 11 // 创建一个PushbackReader对象,指定推回缓冲区的长度为64 12 PushbackReader pr = new PushbackReader(new FileReader( 13 "PushbackTest.java") , 64)) 14 { 15 char[] buf = new char[32]; 16 // 用以保存上次读取的字符串内容 17 String lastContent = ""; 18 int hasRead = 0; 19 // 循环读取文件内容 20 while ((hasRead = pr.read(buf)) > 0) 21 { 22 // 将读取的内容转换成字符串 23 String content = new String(buf , 0 , hasRead); 24 int targetIndex = 0; 25 // 将上次读取的字符串和本次读取的字符串拼起来, 26 // 查看是否包含目标字符串, 如果包含目标字符串 27 if ((targetIndex = (lastContent + content) 28 .indexOf("new PushbackReader")) > 0) 29 { 30 // 将本次内容和上次内容一起推回缓冲区 31 pr.unread((lastContent + content).toCharArray()); 32 // 重新定义一个长度为targetIndex的char数组 33 if(targetIndex > 32) 34 { 35 buf = new char[targetIndex]; 36 } 37 // 再次读取指定长度的内容(就是目标字符串之前的内容) 38 pr.read(buf , 0 , targetIndex); 39 // 打印读取的内容 40 System.out.print(new String(buf , 0 ,targetIndex)); 41 System.exit(0); 42 } 43 else 44 { 45 // 打印上次读取的内容 46 System.out.print(lastContent); 47 // 将本次内容设为上次读取的内容 48 lastContent = content; 49 } 50 } 51 } 52 catch (IOException ioe) 53 { 54 ioe.printStackTrace(); 55 } 56 } 57 }
重定向标准输入/输出:
Java标准输入/输出分别通过System.in和System.out来代表,在默认情况下它们分别代表键盘和显示器,程序通过System.in来获取输入时,实际上是从键盘读取输入;程序
通过System.out执行输出时,程序总是输出到屏幕。
在System类里提供了如下三个重定向标准输入/输出的方法:
1.static void setErr(PrintStream err):重定向“标准”错误输出流
2.static void setIn(InputStream in):重定向“标准”输入流
3.static void setOut(PrintStream out):重定向“标准”输出流
下面程序通过重定向标准输出流,将System.out的输出重定向到文件输出,而不是在屏幕上输出:
1 import java.io.PrintStream; 2 import java.io.FileOutputStream; 3 import java.io.IOException; 4 5 public class RedirectOut 6 { 7 public static void main(String[] args) 8 { 9 try( 10 // 一次性创建PrintStream输出流 11 PrintStream ps = new PrintStream(new FileOutputStream("out.txt"))) 12 { 13 // 将标准输出重定向到ps输出流 14 System.setOut(ps); 15 // 向标准输出输出一个字符串 16 System.out.println("普通字符串"); 17 // 向标准输出输出一个对象 18 System.out.println(new RedirectOut()); 19 } 20 catch (IOException ex) 21 { 22 ex.printStackTrace(); 23 } 24 } 25 }

屏幕上没有任何输出,所有的输出都被重定向到了out.txt文件中。
下面程序通过重定向标准输入流,将System.in的输入重定向到指定文件,而不是键盘输入:
1 import java.util.Scanner; 2 import java.io.FileInputStream; 3 import java.io.IOException; 4 5 public class RedirectIn 6 { 7 public static void main(String[] args) 8 { 9 try( 10 FileInputStream fis = new FileInputStream("RedirectIn.java")) 11 { 12 // 将标准输入重定向到fis输入流 13 System.setIn(fis); 14 // 使用System.in创建Scanner对象,用于获取标准输入 15 Scanner sc = new Scanner(System.in); 16 // 增加下面一行将只把回车作为分隔符 17 sc.useDelimiter(" "); 18 // 判断是否还有下一个输入项 19 while(sc.hasNext()) 20 { 21 // 输出输入项 22 System.out.println("键盘输入的内容是:" + sc.next()); 23 } 24 } 25 catch (IOException ex) 26 { 27 ex.printStackTrace(); 28 } 29 } 30 }
上面程序将标准输入重定向到指定文件,不用从键盘读取输入。
Java虚拟机读写其他进程的数据:
使用Runtime对象的exec()方法可以运行平台上其他程序,该方法产生了一个Process对象,Process对象代表由该Java程序启动的子进程。
Process提供如下三个方法用于让程序和其子进程进行通信:
1.InputStream getErrorStream():获取子进程的错误流
2.InputStream getInputStream():获取子进程的输入流
3.OutputStream getOutputStream():获取子进程的输出流
1 import java.io.IOException; 2 import java.io.BufferedReader; 3 import java.io.InputStreamReader; 4 5 public class ReadFromProcess 6 { 7 public static void main(String[] args) 8 throws IOException 9 { 10 // 运行javac命令,返回运行该命令的子进程 11 Process p = Runtime.getRuntime().exec("javac"); 12 try( 13 // 以p进程的错误流创建BufferedReader对象 14 // 这个错误流对本程序是输入流,对p进程则是输出流 15 BufferedReader br = new BufferedReader(new 16 InputStreamReader(p.getErrorStream()))) 17 { 18 String buff = null; 19 // 采取循环方式来读取p进程的错误输出 20 while((buff = br.readLine()) != null) 21 { 22 System.out.println(buff); 23 } 24 } 25 } 26 }

1 import java.io.IOException; 2 import java.io.PrintStream; 3 import java.io.FileOutputStream; 4 import java.util.Scanner; 5 6 public class WriteToProcess 7 { 8 public static void main(String[] args) 9 throws IOException 10 { 11 // 运行java ReadStandard命令,返回运行该命令的子进程 12 Process p = Runtime.getRuntime().exec("java ReadStandard"); 13 try( 14 // 以p进程的输出流创建PrintStream对象 15 // 这个输出流对本程序是输出流,对p进程则是输入流 16 PrintStream ps = new PrintStream(p.getOutputStream())) 17 { 18 // 向ReadStandard程序写入内容,这些内容将被ReadStandard读取 19 ps.println("普通字符串"); 20 ps.println(new WriteToProcess()); 21 } 22 } 23 } 24 // 定义一个ReadStandard类,该类可以接受标准输入, 25 // 并将标准输入写入out.txt文件。 26 class ReadStandard 27 { 28 public static void main(String[] args) 29 { 30 try( 31 // 使用System.in创建Scanner对象,用于获取标准输入 32 Scanner sc = new Scanner(System.in); 33 PrintStream ps = new PrintStream( 34 new FileOutputStream("out.txt"))) 35 { 36 // 增加下面一行将只把回车作为分隔符 37 sc.useDelimiter(" "); 38 // 判断是否还有下一个输入项 39 while(sc.hasNext()) 40 { 41 // 输出输入项 42 ps.println("键盘输入的内容是:" + sc.next()); 43 } 44 } 45 catch(IOException ioe) 46 { 47 ioe.printStackTrace(); 48 } 49 } 50 }

RandomAccessFile:
“任意访问”,可直接跳转到文件的任意地方来读写数据。
RandomAccessFile可以自由访问文件的任意位置,所以若只需要访问文件的部分内容,而不是把文件从头读到尾,使用RandomAccessFile更好。
若需要在已有的文件后追加内容,应该使用RandomAccessFile。
RandomAccessFile只能读写文件,不能读写其他IO节点。
RandomAccessFile有如下两个方法操作文件记录指针:
1.long getFilePointer():返回文件记录指针的当前位置
2.void seek(long pos):将文件记录指针定位到pos位置
RandomAccessFile的四种访问模式:
1.r:以只读方式打开文件
2.rw:以读写方式打开文件
3.rws:以读写方式打开文件
4.rwd:以读写方式打开文件
下面程序使用了RandomAccessFile来访问指定的中间部分数据:
1 import java.io.RandomAccessFile; 2 import java.io.IOException; 3 4 public class RandomAccessFileTest 5 { 6 public static void main(String[] args) 7 { 8 try( 9 RandomAccessFile raf = new RandomAccessFile( 10 "RandomAccessFileTest.java" , "r")) 11 { 12 // 获取RandomAccessFile对象文件指针的位置,初始位置是0 13 System.out.println("RandomAccessFile的文件指针的初始位置:" 14 + raf.getFilePointer()); 15 // 移动raf的文件记录指针的位置 16 raf.seek(300); 17 byte[] bbuf = new byte[1024]; 18 // 用于保存实际读取的字节数 19 int hasRead = 0; 20 // 使用循环来重复“取水”过程 21 while ((hasRead = raf.read(bbuf)) > 0 ) 22 { 23 // 取出“竹筒”中水滴(字节),将字节数组转换成字符串输入! 24 System.out.print(new String(bbuf , 0 , hasRead )); 25 } 26 } 27 catch (IOException ex) 28 { 29 ex.printStackTrace(); 30 } 31 } 32 }
下面程序示范了如何向指定文件追加内容:
1 import java.io.*; 2 /** 3 * Description: 4 * <br/>网站: <a href="http://www.crazyit.org">疯狂Java联盟</a> 5 * <br/>Copyright (C), 2001-2016, Yeeku.H.Lee 6 * <br/>This program is protected by copyright laws. 7 * <br/>Program Name: 8 * <br/>Date: 9 * @author Yeeku.H.Lee kongyeeku@163.com 10 * @version 1.0 11 */ 12 public class AppendContent 13 { 14 public static void main(String[] args) 15 { 16 try( 17 //以读、写方式打开一个RandomAccessFile对象 18 RandomAccessFile raf = new RandomAccessFile("out.txt" , "rw")) 19 { 20 //将记录指针移动到out.txt文件的最后 21 raf.seek(raf.length()); 22 raf.write("追加的内容! ".getBytes()); 23 } 24 catch (IOException ex) 25 { 26 ex.printStackTrace(); 27 } 28 } 29 }

RandomAccessFile依然不能向文件的指定位置插入内容,若直接将文件记录指针移动到中间位置后开始输入,则新的输出内容会覆盖文件中原有的内容。若需要向指定
位置插入内容,程序需要先把插入点后面的内容读入缓冲区,等把需要插入的数据写入文件后,再将缓冲区的内容追加到文件后面:
1 import java.io.File; 2 import java.io.IOException; 3 import java.io.FileOutputStream; 4 import java.io.FileInputStream; 5 import java.io.RandomAccessFile; 6 7 public class InsertContent 8 { 9 public static void insert(String fileName , long pos 10 , String insertContent) throws IOException 11 { 12 File tmp = File.createTempFile("tmp" , null); 13 tmp.deleteOnExit(); 14 try( 15 RandomAccessFile raf = new RandomAccessFile(fileName , "rw"); 16 // 使用临时文件来保存插入点后的数据 17 FileOutputStream tmpOut = new FileOutputStream(tmp); 18 FileInputStream tmpIn = new FileInputStream(tmp)) 19 { 20 raf.seek(pos); 21 // ------下面代码将插入点后的内容读入临时文件中保存------ 22 byte[] bbuf = new byte[64]; 23 // 用于保存实际读取的字节数 24 int hasRead = 0; 25 // 使用循环方式读取插入点后的数据 26 while ((hasRead = raf.read(bbuf)) > 0 ) 27 { 28 // 将读取的数据写入临时文件 29 tmpOut.write(bbuf , 0 , hasRead); 30 } 31 // ----------下面代码插入内容---------- 32 // 把文件记录指针重新定位到pos位置 33 raf.seek(pos); 34 // 追加需要插入的内容 35 raf.write(insertContent.getBytes()); 36 // 追加临时文件中的内容 37 while ((hasRead = tmpIn.read(bbuf)) > 0 ) 38 { 39 raf.write(bbuf , 0 , hasRead); 40 } 41 } 42 } 43 public static void main(String[] args) 44 throws IOException 45 { 46 insert("InsertContent.java" , 45 , "插入的内容 "); 47 } 48 }

对象序列化:
对象序列化是将对象保存到磁盘中,或允许在网络中直接传输对象。对象序列化机制允许吧内存中的Java对象转换为平台无关的二进制流,从而允许把这种二进制流持久的
保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点。其他程序一旦获得这种二进制流(无论是从磁盘中获取,还是通过网络获取的),都可以将这种二进
制流恢复成原来的Java对象。
若要让某个对象支持序列化机制,则必须让它的类必须是可序列化的(serializable)。即必须实现如下两个接口之一:
1.serializable
2.Externalizable
这两个接口只是一个标记接口,无需实现任何方法,它只是表明该类的实例是可序列化的。
所有可能在网络上传输的对象的类都是可序列化的,否则程序会出现异常。所有需要保存在磁盘里的对象的类都必须是可序列化的。
序列化机制是Java EE平台的基础。通常建议:程序创建的每个JavaBean类都实现Serializable。
程序通过如下两个步骤来序列化对象:
1.创建一个ObjectOutputStream,这个输出流是一个处理流,所以必须建立在其他节点流的基础之上。
//创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.txt"));
2.将一个Person对象输出到输出流中
oos.writeObject(per);
1 public class Person implements java.io.Serializable 2 { 3 private String name; 4 private int age; 5 // 注意此处没有提供无参数的构造器! 6 public Person(String name , int age) 7 { 8 System.out.println("有参数的构造器"); 9 this.name = name; 10 this.age = age; 11 } 12 // 省略name与age的setter和getter方法 13 14 // name的setter和getter方法 15 public void setName(String name) 16 { 17 this.name = name; 18 } 19 public String getName() 20 { 21 return this.name; 22 } 23 24 // age的setter和getter方法 25 public void setAge(int age) 26 { 27 this.age = age; 28 } 29 public int getAge() 30 { 31 return this.age; 32 } 33 }
1 import java.io.ObjectOutputStream; 2 import java.io.FileOutputStream; 3 import java.io.IOException; 4 5 public class WriteObject 6 { 7 public static void main(String[] args) 8 { 9 try( 10 // 创建一个ObjectOutputStream输出流 11 ObjectOutputStream oos = new ObjectOutputStream( 12 new FileOutputStream("object.txt"))) 13 { 14 Person per = new Person("孙悟空", 500); 15 // 将per对象写入输出流 16 oos.writeObject(per); 17 } 18 catch (IOException ex) 19 { 20 ex.printStackTrace(); 21 } 22 } 23 }


若想要从二进制文件中恢复Java对象,则需要使用反序列化,反序列化的步骤如下:
1.创建一个ObjectInputStream输入流,这个输入流是一个处理流,所以必须建立在其他节点流的基础之上
//创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt"));
2.调用ObjectInputStream对象的readObject()方法读取流中的对象,该方法返回一个Object类型的Java对象,若程序知道该Java对象的类型,则可以将该对象强制类型
转换为其真实的类型
//从输入流中读取一个Java对象,并将其强制类型转换为Person类:
Person p = (Person) ois.readObject();
1 import java.io.ObjectInputStream; 2 import java.io.FileInputStream; 3 4 public class ReadObject 5 { 6 public static void main(String[] args) 7 { 8 try( 9 // 创建一个ObjectInputStream输入流 10 ObjectInputStream ois = new ObjectInputStream( 11 new FileInputStream("object.txt"))) 12 { 13 // 从输入流中读取一个Java对象,并将其强制类型转换为Person类 14 Person p = (Person)ois.readObject(); 15 System.out.println("名字为:" + p.getName() 16 + " 年龄为:" + p.getAge()); 17 } 18 catch (Exception ex) 19 { 20 ex.printStackTrace(); 21 } 22 } 23 }

注意:反序列化读取的仅仅是Java对象的数据,而不是Java类,因此采用反序列化恢复Java对象时,必须提供该Java对象所属类的class文件,否则将会引发
ClassNotFoundException异常。
还有一点,Person类只有一个有参数的构造器,没有无参数的构造器,而且该构造器内有一个普通的打印语句。当反序列化读取Java对象时,并没有看到程序调用该构造器
这表明反序列化机制无需通过构造器来初始化Java对象。
若使用序列化机制向文件中写入了很多个Java对象,使用反序列化机制恢复对象时必须按照实际写入的顺序读取。
当一个可序列化类有多个父类时(包括直接父类和间接父类),这些父类要么有无参数构造器,要么也可序列化——否则反序列化时将抛出InvalidClassException异常。若
父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会序列化到二进制流。
对象引用的序列化:
若要序列化的对象中包含引用类型,那么这个引用类型必须是可序列化的,否则拥有该类型成员变量的类也是不可序列化的。
1 public class Teacher implements java.io.Serializable 2 { 3 private String name; 4 private Person student; 5 public Teacher(String name , Person student) 6 { 7 this.name = name; 8 this.student = student; 9 } 10 // 此处省略了name和student的setter和getter方法 11 12 // name的setter和getter方法 13 public void setName(String name) 14 { 15 this.name = name; 16 } 17 public String getName() 18 { 19 return this.name; 20 } 21 22 // student的setter和getter方法 23 public void setStudent(Person student) 24 { 25 this.student = student; 26 } 27 public Person getStudent() 28 { 29 return this.student; 30 } 31 }
当程序序列化一个Teacher对象时,若该Teacher对象持有一个Person对象的引用,为了在反序列化是可以正常恢复该Teacher对象,程序会顺带将该Person对象也进行
序列化,所以Person类也必须是可序列化的,否则Teacher类将不可序列化。
Java序列化机制采用了一种特殊的序列化算法,其算法内容如下:
1.所有保存在磁盘中的对象都有一个序列化编号
2.当程序试图序列化一个对象时,程序将先检查该对象是否已经被序列化过,只有该对象从未(在本次虚拟机中)被序列化过,系统才会将该对象转换成字节序列并
输出
3.若某个对象已被序列化,程序只是直接输出一个序列化编号,而不是再次重新序列化该对象。
1 import java.io.ObjectOutputStream; 2 import java.io.FileOutputStream; 3 import java.io.IOException; 4 5 public class WriteTeacher 6 { 7 public static void main(String[] args) 8 { 9 try( 10 // 创建一个ObjectOutputStream输出流 11 ObjectOutputStream oos = new ObjectOutputStream( 12 new FileOutputStream("teacher.txt"))) 13 { 14 Person per = new Person("孙悟空", 500); 15 Teacher t1 = new Teacher("唐僧" , per); 16 Teacher t2 = new Teacher("菩提祖师" , per); 17 // 依次将四个对象写入输出流 18 oos.writeObject(t1); 19 oos.writeObject(t2); 20 oos.writeObject(per); 21 oos.writeObject(t2); 22 } 23 catch (IOException ex) 24 { 25 ex.printStackTrace(); 26 } 27 } 28 }

上面程序中粗体字代码4次调用了writeObject()方法来输出对象,实际上值序列化了三个对象,且序列的两个Teacher对象的student引用实际是同一个Person对象。
1 import java.io.ObjectInputStream; 2 import java.io.FileInputStream; 3 4 public class ReadTeacher 5 { 6 public static void main(String[] args) 7 { 8 try( 9 // 创建一个ObjectInputStream输出流 10 ObjectInputStream ois = new ObjectInputStream( 11 new FileInputStream("teacher.txt"))) 12 { 13 // 依次读取ObjectInputStream输入流中的四个对象 14 Teacher t1 = (Teacher)ois.readObject(); 15 Teacher t2 = (Teacher)ois.readObject(); 16 Person p = (Person)ois.readObject(); 17 Teacher t3 = (Teacher)ois.readObject(); 18 // 输出true 19 System.out.println("t1的student引用和p是否相同:" 20 + (t1.getStudent() == p)); 21 // 输出true 22 System.out.println("t2的student引用和p是否相同:" 23 + (t2.getStudent() == p)); 24 // 输出true 25 System.out.println("t2和t3是否是同一个对象:" 26 + (t2 == t3)); 27 } 28 catch (Exception ex) 29 { 30 ex.printStackTrace(); 31 } 32 } 33 }

由于Java序列化机制使然:若多次序列化同一个Java对象时,只有第一次序列化才会把该Java对象转换为字节序列并输出,这样可能引起一个潜在的问题——当程序序列化
一个可变对象时,只有第一次使用writeObject()方法输出时才会将该对象转换为字节序列并输出,当程序再次调用writeObject()方法时,程序只是输出前面的序列化编号
即使后面该对象的实例变量值已被改变,改变的实例变量值也不会被输出。
1 import java.io.ObjectOutputStream; 2 import java.io.FileOutputStream; 3 import java.io.ObjectInputStream; 4 import java.io.FileInputStream; 5 6 public class SerializeMutable 7 { 8 public static void main(String[] args) 9 { 10 11 try( 12 // 创建一个ObjectOutputStream输入流 13 ObjectOutputStream oos = new ObjectOutputStream( 14 new FileOutputStream("mutable.txt")); 15 // 创建一个ObjectInputStream输入流 16 ObjectInputStream ois = new ObjectInputStream( 17 new FileInputStream("mutable.txt"))) 18 { 19 Person per = new Person("孙悟空", 500); 20 // 系统会per对象转换字节序列并输出 21 oos.writeObject(per); 22 // 改变per对象的name实例变量 23 per.setName("猪八戒"); 24 // 系统只是输出序列化编号,所以改变后的name不会被序列化 25 oos.writeObject(per); 26 Person p1 = (Person)ois.readObject(); //① 27 Person p2 = (Person)ois.readObject(); //② 28 // 下面输出true,即反序列化后p1等于p2 29 System.out.println(p1 == p2); 30 // 下面依然看到输出"孙悟空",即改变后的实例变量没有被序列化 31 System.out.println(p2.getName()); 32 } 33 catch (Exception ex) 34 { 35 ex.printStackTrace(); 36 } 37 } 38 }

和上述描述一致,改变实例变量值,但序列化对象中的实例变量不会改变。
自定义序列化:
在一些特殊情况下,若一个类中包含的某些引用变量不想被实例化如:银行账户信息等;或者某个实例变量的类型是不可被序列化的,因此不希望对该实例变量进行序列化
当对某个对象进行序列化时,系统会自动把该对象的所有实例变量依次进行序列化。
通过在实例变量前面使用transient关键字修饰,可以指定Java序列化时无需理会该实例变量。
1 public class Person implements java.io.Serializable 2 { 3 private String name; 4 private transient int age; 5 // 注意此处没有提供无参数的构造器! 6 public Person(String name , int age) 7 { 8 System.out.println("有参数的构造器"); 9 this.name = name; 10 this.age = age; 11 } 12 // 省略name与age的setter和getter方法 13 14 // name的setter和getter方法 15 public void setName(String name) 16 { 17 this.name = name; 18 } 19 public String getName() 20 { 21 return this.name; 22 } 23 24 // age的setter和getter方法 25 public void setAge(int age) 26 { 27 this.age = age; 28 } 29 public int getAge() 30 { 31 return this.age; 32 } 33 }
transient关键字只用于修饰实例变量,不能修饰Java程序中的其他成分。
1 import java.io.ObjectOutputStream; 2 import java.io.FileOutputStream; 3 import java.io.ObjectInputStream; 4 import java.io.FileInputStream; 5 6 public class TransientTest 7 { 8 public static void main(String[] args) 9 { 10 try( 11 // 创建一个ObjectOutputStream输出流 12 ObjectOutputStream oos = new ObjectOutputStream( 13 new FileOutputStream("transient.txt")); 14 // 创建一个ObjectInputStream输入流 15 ObjectInputStream ois = new ObjectInputStream( 16 new FileInputStream("transient.txt"))) 17 { 18 Person per = new Person("孙悟空", 500); 19 // 系统会per对象转换字节序列并输出 20 oos.writeObject(per); 21 Person p = (Person)ois.readObject(); 22 System.out.println(p.getAge()); 23 } 24 catch (Exception ex) 25 { 26 ex.printStackTrace(); 27 } 28 } 29 }

使用transient关键字修饰实例变量虽然简单,但被transient修饰的实例变量将被完全隔离在序列化机制外,这样导致在反序列化恢复Java对象时无法取得该实例变量值。
Java提供了自定义序列化机制,通过这种自定义序列化机制可以让程序控制如何序列化各实例变量,甚至完全不序列化某些实例变量(与使用transient关键字的效果相同)
在序列化和反序列化过程中需要特殊处理的类应该提供如下特殊签名方法,这些特殊方法用以实现自定义序列化:
1.private void writeObject(java.io.ObjectOutputStream out) throws IOException
2.private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
3.private void readObjectNoData() throws ObjectStreamException;
1 import java.io.ObjectStreamException; 2 import java.util.ArrayList; 3 import java.io.IOException; 4 5 public class Person implements java.io.Serializable 6 { 7 private String name; 8 private transient int age; 9 // 注意此处没有提供无参数的构造器! 10 public Person(String name , int age) 11 { 12 System.out.println("有参数的构造器"); 13 this.name = name; 14 this.age = age; 15 } 16 // 省略name与age的setter和getter方法 17 18 // name的setter和getter方法 19 public void setName(String name) 20 { 21 this.name = name; 22 } 23 public String getName() 24 { 25 return this.name; 26 } 27 28 // age的setter和getter方法 29 public void setAge(int age) 30 { 31 this.age = age; 32 } 33 public int getAge() 34 { 35 return this.age; 36 } 37 38 private void writeObject(java.io.ObjectOutputStream out) 39 throws IOException 40 { 41 // 将name实例变量的值反转后写入二进制流 42 out.writeObject(new StringBuffer(name).reverse()); 43 out.writeInt(age); 44 } 45 private void readObject(java.io.ObjectInputStream in) 46 throws IOException, ClassNotFoundException 47 { 48 // 将读取的字符串反转后赋给name实例变量 49 this.name = ((StringBuffer)in.readObject()).reverse() 50 .toString(); 51 this.age = in.readInt(); 52 } 53 }
上面程序实现了自定义序列化。
还有更彻底的自定义机制,甚至可以在序列化对象时将该对象替换成其他对象。若需要实现序列化某个对象时替换该对象,则应为序列化类提供如下特殊方法:
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamException;
下面程序可以在写入Person对象时将该对象替换成ArrayList:
1 import java.io.ObjectStreamException; 2 import java.util.ArrayList; 3 import java.io.IOException; 4 5 public class Person implements java.io.Serializable 6 { 7 private String name; 8 private transient int age; 9 // 注意此处没有提供无参数的构造器! 10 public Person(String name , int age) 11 { 12 System.out.println("有参数的构造器"); 13 this.name = name; 14 this.age = age; 15 } 16 // 省略name与age的setter和getter方法 17 18 // name的setter和getter方法 19 public void setName(String name) 20 { 21 this.name = name; 22 } 23 public String getName() 24 { 25 return this.name; 26 } 27 28 // age的setter和getter方法 29 public void setAge(int age) 30 { 31 this.age = age; 32 } 33 public int getAge() 34 { 35 return this.age; 36 } 37 38 // 重写writeReplace方法,程序在序列化该对象之前,先调用该方法 39 private Object writeReplace()throws ObjectStreamException 40 { 41 ArrayList<Object> list = new ArrayList<>(); 42 list.add(name); 43 list.add(age); 44 return list; 45 } 46 }
Java序列化机制保证在序列化某个对象之前,先调用该对象的writeReplace()方法,若该方法返回另一个Java对象,则系统转为序列化另一个对象,如下程序表面上是序列
化Person对象,但实际上序列化的是ArrayList:
1 import java.io.ObjectOutputStream; 2 import java.io.ObjectInputStream; 3 import java.io.FileOutputStream; 4 import java.io.FileInputStream; 5 import java.util.ArrayList; 6 7 public class ReplaceTest 8 { 9 public static void main(String[] args) 10 { 11 try( 12 // 创建一个ObjectOutputStream输出流 13 ObjectOutputStream oos = new ObjectOutputStream( 14 new FileOutputStream("replace.txt")); 15 // 创建一个ObjectInputStream输入流 16 ObjectInputStream ois = new ObjectInputStream( 17 new FileInputStream("replace.txt"))) 18 { 19 Person per = new Person("孙悟空", 500); 20 // 系统将per对象转换字节序列并输出 21 oos.writeObject(per); 22 // 反序列化读取得到的是ArrayList 23 ArrayList list = (ArrayList)ois.readObject(); 24 System.out.println(list); 25 } 26 catch (Exception ex) 27 { 28 ex.printStackTrace(); 29 } 30 } 31 }


与writeReplace()方法相对的是,序列化机制还有一个特殊的方法,它可以实现保护性复制整个对象:
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException;
这个方法会紧接着readObject()之后被调用,该方法的返回值将会代替原来反序列化的对象,而原来readObject()反序列化的对象将会被立即丢弃。
readResolve()方法在序列化枚举类、单例类时尤其有用。
1 import java.io.ObjectStreamException; 2 3 public class Orientation 4 implements java.io.Serializable 5 { 6 public static final Orientation HORIZONTAL = new Orientation(1); 7 public static final Orientation VERTICAL = new Orientation(2); 8 private int value; 9 private Orientation(int value) 10 { 11 this.value = value; 12 } 13 // 为枚举类增加readResolve()方法 14 private Object readResolve()throws ObjectStreamException 15 { 16 if (value == 1) 17 { 18 return HORIZONTAL; 19 } 20 if (value == 2) 21 { 22 return VERTICAL; 23 } 24 return null; 25 } 26 }
1 import java.io.ObjectOutputStream; 2 import java.io.ObjectInputStream; 3 import java.io.FileOutputStream; 4 import java.io.FileInputStream; 5 6 public class ResolveTest 7 { 8 public static void main(String[] args) 9 { 10 try( 11 // 创建一个ObjectOutputStream输入流 12 ObjectOutputStream oos = new ObjectOutputStream( 13 new FileOutputStream("transient.txt")); 14 // 创建一个ObjectInputStream输入流 15 ObjectInputStream ois = new ObjectInputStream( 16 new FileInputStream("transient.txt"))) 17 { 18 oos.writeObject(Orientation.HORIZONTAL); 19 Orientation ori = (Orientation)ois.readObject(); 20 System.out.println(ori == Orientation.HORIZONTAL); 21 } 22 catch (Exception ex) 23 { 24 ex.printStackTrace(); 25 } 26 } 27 }

上面程序的enum类是Java5之前的写法,若将这种enum类序列化,那么将会在比较的时候返回false,但是若将readResolve()方法重写,则会返回true。
通常建议是,对于final类重写readResolve()方法不会有任何问题;否则,重写readResolve()方法时尽量使用private修饰该方法。
另一种自定义序列化机制:
这种序列化方式完全由程序员自己决定存储和恢复对象数据。要实现该目标,Java类必须实现Externalizable接口,该接口下有两个方法:
1.void readExternal(ObjectInput in)
2.void writeExternal(ObjectOutput out)
1 import java.io.IOException; 2 3 public class Person implements java.io.Externalizable 4 { 5 private String name; 6 private int age; 7 // 注意此处没有提供无参数的构造器! 8 public Person(String name , int age) 9 { 10 System.out.println("有参数的构造器"); 11 this.name = name; 12 this.age = age; 13 } 14 // 省略name与age的setter和getter方法 15 16 // name的setter和getter方法 17 public void setName(String name) 18 { 19 this.name = name; 20 } 21 public String getName() 22 { 23 return this.name; 24 } 25 26 // age的setter和getter方法 27 public void setAge(int age) 28 { 29 this.age = age; 30 } 31 public int getAge() 32 { 33 return this.age; 34 } 35 36 public void writeExternal(java.io.ObjectOutput out) 37 throws IOException 38 { 39 // 将name实例变量的值反转后写入二进制流 40 out.writeObject(new StringBuffer(name).reverse()); 41 out.writeInt(age); 42 } 43 public void readExternal(java.io.ObjectInput in) 44 throws IOException, ClassNotFoundException 45 { 46 // 将读取的字符串反转后赋给name实例变量 47 this.name = ((StringBuffer)in.readObject()).reverse().toString(); 48 this.age = in.readInt(); 49 } 50 }
需要指出的是,当使用Externalizable机制反序列化对象时,程序会先使用public的无参数构造器创建实例,然后再执行readExternal()方法进行反序列化,因此实现Externalizable的序列化类必须提供public的无参数构造器。
版本:
Java序列化机制允许为序列化提供一个private static final 的 serialVersionUID值,用于标识该Java类的序列化版本。
为了在反序列化是确保序列化版本的兼容性,最好在每个要序列化的类中加入private static final long serialVersionUID 这个类变量。