一、前言
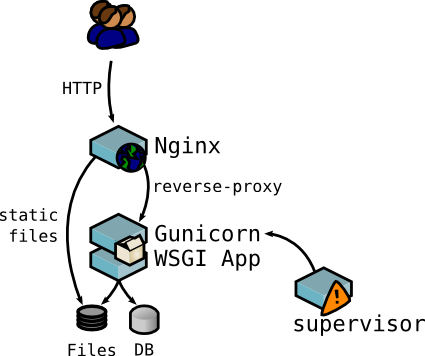
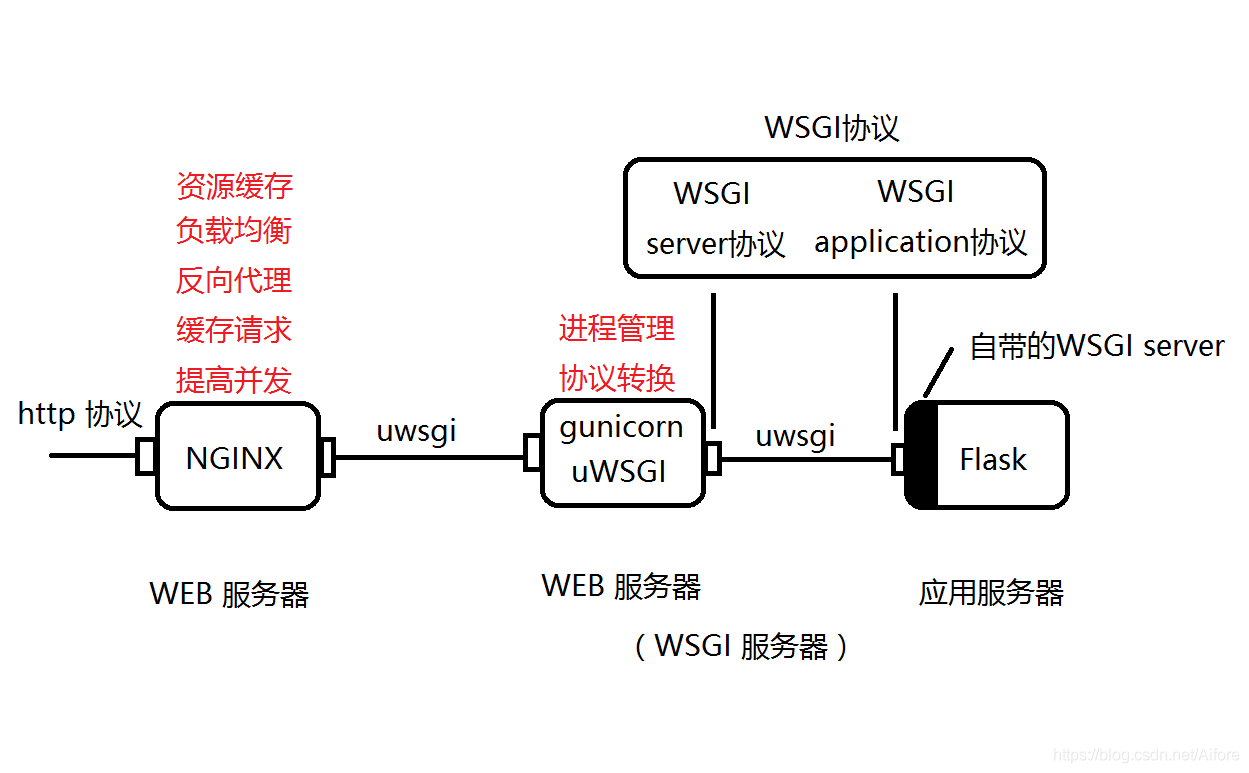
在Python开发中,服务部署有各种各样的方案,同时作为服务端语言也是比较吃力的,没有Java那样有很成熟的方案。在这里介绍一个高并发部署方案:Systemd+Nginx+Gunicorn+Gevent+Supervisor+Flask。
众所周知 Flask 是一个同步的框架,处理请求的时候是以单进程的方式,当同时访问的人数过多时,Flask 服务就会出现阻塞的情况。就像我们买火车票一样,当买火车票的人多的时候,排队的人就会很多,队伍就会很长,相应的等待的时间会变得很长!
二、服务介绍
部署方案:
- Systemd:Linux中为系统的启动和管理提供一套完整的解决方案
- Nginx:高性能 Web 服务器+负载均衡
- Gunicorn:高性能 WSGI 服务器;
- Gevent:把 Python 同步代码变成异步协程的库;
- Supervisor:监控服务进程的工具;
- Flask:一个使用Python编写的轻量级 Web 应用框架
Gunicorn来实现webserver,会启动多个进程,通过Gevent模式来运行,会达到协程的效果,每来一个请求会自动分配给不同的进程来执行。
三、项目部署
1、创建python项目
创建一个项目
mkdir /usr/local/DataAnalysis安装flask
pip install flask
构建简单的服务(注意:路由函数外不可再套函数,否则后续gunicorn不通!):analysis_service.py
from flask import Flask, request
import api
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
@app.route('/server', methods=["POST"])
def predict():
params = request.json if request.method == "POST" else request.args
data = params['data']
result = api.server_api(data)
return result
if __name__ == '__main__':
app.run()
启动 flask
python analysis_service.py
此时,用浏览器访问 http://127.0.0.1:5000(flask默认ip和端口) 就能看到网页显示Hello World!。
2、gunicorn 部署服务
在上面我们使用 flask 自带的服务器,完成了 web 服务的启动。但在生产环境下,flask 自带的 服务器,无法满足性能要求。我们这里采用 gunicorn 做 wsgi容器,用来部署 python。
安装 gunicorn
pip install gunicorn
gunicorn配置文件
在项目根目录创建一个gunicorn.py文件,当然名字和文件位置你可以进行更改。
from gevent import monkey
monkey.patch_all()
import multiprocessing
import os
from orm.config import LOG_DIR
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
debug = True
loglevel = 'debug'
bind = '0.0.0.0:9002'
pidfile = os.path.join(LOG_DIR, 'gunicorn.pid')
logfile = os.path.join(LOG_DIR, 'debug.log')
errorlog = os.path.join(LOG_DIR, 'error.log')
accesslog = os.path.join(LOG_DIR, 'access.log')
max_requests = 50000
max_requests_jitter = 2
timeout = 70
graceful_timeout = 30
limit_request_line = 8190
limit_request_fields = 200
limit_request_fields_size = 8190
capture_output = True
work_class = "sync"
# 启动的进程数
workers = 5
worker_class = 'gunicorn.workers.ggevent.GeventWorker'
x_forwarded_for_header = 'X-FORWARDED-FOR'
这里使用gevent模式来支持并发
创建程序入口
在使用Pycharm创建Flask项目的时候,会生成一个analysis_service.py的入口文件,里面是创建启动App实例,在这里我们创建一个新的程序入口,用来使用Gunicorn服务,在生产环境中使用。
在项目根目录创建一个main.py的文件,内容如下:
from analysis_service import app
import logging
gunicorn_logger = logging.getLogger('gunicorn.error')
app.logger.handlers = gunicorn_logger.handlers
app.logger.setLevel(gunicorn_logger.level)
if __name__ == '__main__':
app.run()
测试配置
上面配置好了,下面进行测试运行服务。
执行命令:
gunicorn -c gunicorn.py main:app
如果没有出现报错,那么服务就可以启动了,访问接口可以有数据了。
3、Systemd配置
为了自动化部署,配合systemd,可以如下设置systemd配置文件(包括服务和定时器):
1)data-analysis.service
[Unit]
Description=Data-Analysis-Service
After=multi-user.target
[Service]
Type=idle
#Restart=always
Restart=on-failure
RestartSec=30
WorkingDirectory=/usr/local/DataAnalysis
EnvironmentFile=/usr/local/DataAnalysis/orm/environment.sh
ExecStart=/usr/local/DataAnalysis/deploy_env/dataAnalysis/bin/gunicorn -c /usr/local/DataAnalysis/gunicorn_conf.py --preload main:app
[Install]
WantedBy=multi-user.target
2)data-analysis.timer
[Unit]
Description=Data-Analysis-Service-Timer
[Timer]
#每日凌晨五点重启
OnCalendar=*-*-* 05:00:00
#每隔一定时间重启
#OnUnitActiveSec=12h
Unit=data-analysis.service
[Install]
WantedBy=multi-user.target
4、Supervisor配置
Supervisor是一个用Python编写的进程管理工具,我们这里通过他来管理我们的项目进程。
安装Supervisor
pip install supervisor
先检查环境中是否存在配置文件,各个系统不一样,可以全局搜一下supervisord.conf
如果配置文件不存在,可以通过命令生成,这里用到echo_supervisord_conf,也可以全局搜一下,然后生成
这里我的环境生成命令是:
/Users/yida/anaconda3/bin/echo_supervisord_conf > /opt/supervisord/supervisord.conf
然后打开supervisord.conf,修改内容,去掉注释
[include]
files = /opt/supervisord/*.conf
通常这两行是注释的,这里我们取消注释,这个配置的作用是导入这个路径下面所有的conf配置文件,后面如果有很多项目,可以每个项目都写一个配置文件。
创建项目的配置文件
这里我们创建一个项目需要的配置文件,用于启动我们上面创建的flask项目。
首先创建一个dataAnalysis.conf,名字可以随意起
内容如下:
[program:dataAnalysis]
command=/usr/local/DataAnalysis/deploy_env/dataAnalysis/bin/gunicorn -c /usr/local/DataAnalysis/gunicorn_conf.py --preload main:app
directory=/usr/local/DataAnalysis/
startsecs=0
stopwaitsecs=0
autostart=true
autorestart=true
dataAnalysis是项目启动的服务标识,可以根据自己需求去修改
command后内容,为使用gunicorn的启动命令
directory是项目根目录
supervisor的基本使用命令
supervisord -c supervisor.conf 通过配置文件启动supervisor
supervisorctl -c supervisor.conf status 查看supervisor的状态
supervisorctl -c supervisor.conf reload 重新载入 配置文件
supervisorctl -c supervisor.conf start [all]|[appname] 启动指定/所有 supervisor管理的程序进程
supervisorctl -c supervisor.conf stop [all]|[appname] 关闭指定/所有 supervisor管理的程序进程
supervisor 还有一个web的管理界面,可以激活。更改supervisord.conf配置文件
[inet_http_server] ; inet (TCP) server disabled by default
port=127.0.0.1:9000 ; (ip_address:port specifier, *:port for all iface)
username=user ; (default is no username (open server))
password=123 ; (default is no password (open server))
[supervisorctl]
serverurl=unix:///tmp/supervisor.sock ; use a unix:// URL for a unix socket
serverurl=http://127.0.0.1:9000 ; use an http:// url to specify an inet socket
username=user ; should be same as http_username if set
password=123 ; should be same as http_password if set
;prompt=mysupervisor ; cmd line prompt (default "supervisor")
;history_file=~/.sc_history ; use readline history if available
启动Supervisord服务
上面配置好了Supervisord所需要的配置,下面开始启动服务
启动命令:
supervisord -c /opt/supervisord/supervisord.conf
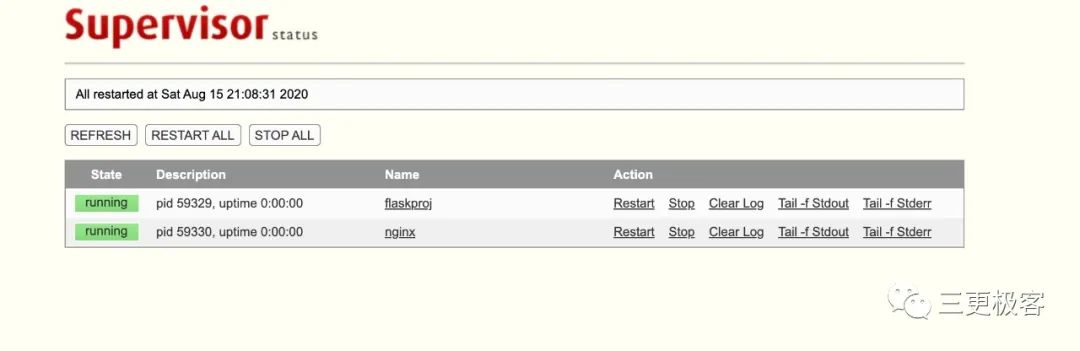
现在已经完成 supervsior 启动 gunicorn。访问http://127.0.0.1:9000 可以得到 supervisor的web管理界面。访问http://127.0.0.1:5000可以看见gunciron 启动的返回的Hello World!
5、Nginx配置
高性能 Web 服务器+负载均衡
安装Nginx
# Mac
brew install nginx
# Linux
yum install nginx
# Windows,官网下载程序包,直接启动
在这里使用 supervisor 来管理 nginx。还需要增加配置文件,用来管理Nginx服务。
这里管理的还是和上面flask项目的配置文件一个目录。
此处创建/opt/supervisord/nginx.conf
[program:nginx]
command=nginx
startsecs=0
stopwaitsecs=0
autostart=false
autorestart=false
stdout_logfile=/OneDrive/USERPRO/Python/flask-proj/log/nginx.log
stderr_logfile=/OneDrive/USERPRO/Python/flask-proj/log/nginx.err
supervisor管理nginx服务的配置文件创建好了,可以通过配置好的信息,使用supervisor命令来启动nginx服务
supervisorctl start nginx
访问http://127.0.0.1:9000 可以看到nginx服务已经启动
我们还需要再配置Nginx的配置文件nginx.conf,用来代理我们的gunicorn启动的flask项目接口。
nginx.conf配置如下:
server {
listen 8080;
server_name localhost;
location / {
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Methods 'GET, POST, OPTIONS' always;
add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization';
if ($request_method = 'OPTIONS') {
return 204;
}
proxy_pass http://127.0.0.1:5000;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_read_timeout 300;
proxy_send_timeout 300;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
重启Nginx服务
# 重启,刷新配置
nginx -s relaod
访问http://127.0.0.1:8080可以看见已经代理gunciron 启动的服务,接口返回的Hello World!
四、总结
至此,使用Systemd+Nginx+Gunicorn+Gevent+Supervisor+Flask完成部署,可以运行在生产环境上了。
关于使用Nginx的问题,如果使用k8s管理容器化应用程序,k8s已为容器之间实现负载均衡等功能,可以根据具体业务来抉择。
这里的方案只是一个参考,大家根据具体场景选择吧。
欢迎探讨指正。
参考:
https://blog.csdn.net/weixin_39843078/article/details/111220592
https://cloud.tencent.com/developer/article/1549550
https://blog.csdn.net/aifore/article/details/86703685
https://www.cnblogs.com/chengkanghua/p/12708584.html