Savepoint
本文翻译自文档Streaming Guide / Savepoints
-------------------------------------------------------------
使用DataStream API编写的程序可以从一个savepoint处恢复执行。savepoint可以同时更新你的程序和Flink集群而不丢失任何状态。该文档包括了从触发、存储以及销毁(dispose)savepoint的所有内容。有关Flink如何处理状态和失效的详细内容,请见文档State in Streaming Program和Fault Tolerance。
一、概述
savepoint是人工触发的检查点,它将对程序做一次快照并将结果写出到statebackend。这些过程都依赖于检查点机制。在程序执行期间,程序在worker节点处将进行周期性地快照并且生成检查点。由于恢复时仅仅需要最近的一个已完成的检查点,故旧的检查点在新的检查点完成后就可以安全地丢弃了。
savepoint类似于这些周期性的检查点,不同之处在于它们是由用户触发,并且不会在更新的检查点完成后自动过期。
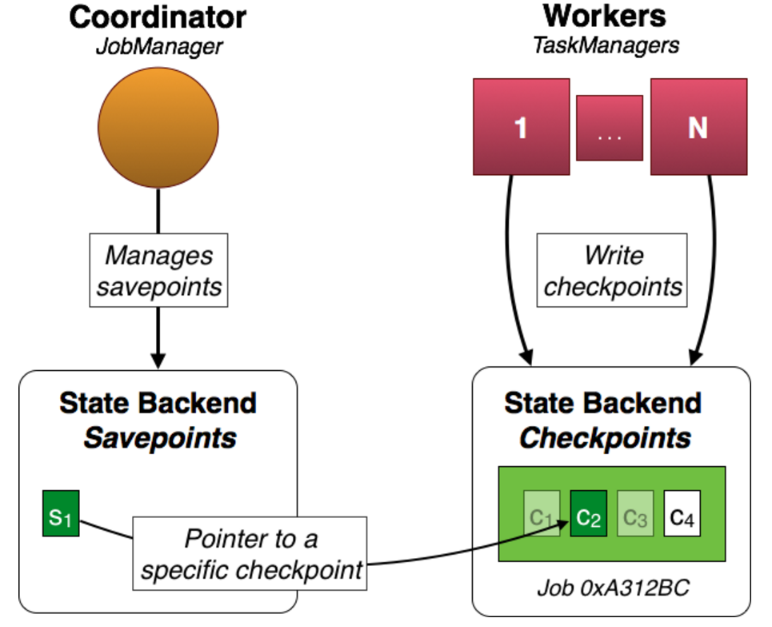
在上图中的例子里,worker为job 0xA312BC生成了检查点c1,c2,c3。c4是最近的检查点,而c1和c3已经被抛弃。但c2是特殊的,它是与savepoint s1相关的状态并且已经被用户触发,且不会像c1和c3一样在更新的检查点完成后自动过期。
注意,s1仅仅是一个指向检查点数据c2的指针,这意味着实际上的savepoint的状态不是复制的并且周期性检查点是就近维护的(kept around)
二、配置
savepoint指向一个正常的检查点并且将它们的状态存储在配置好的StateBackend中。当前版本下,支持的state backend包括jobmanager和filesystem。有关周期性检查点的State backend的配置与savepoint的state backend是相互独立的。savepoint不是检查点数据的复制,但它会指向配置后的检查点state backend。
2.1 JobManager
这是savepoint的默认backend
savepoint存储在jobmanager的堆中,它们将在jobManager关闭时丢失。该模式仅仅在你想要在相同的集群持续运行的情况下将程序停止和恢复时才有用。不建议在产品级项目中使用该配置方式。savepoint不是"job manager的高度可用性状态"的一部分
savepoints.state.backend: jobmanager
注意,如果你不为savepoint配置一个state backend,则会使用JobManager的backend。
2.2 File system
在此配置中,savepoint将存储在配置的文件系统目录下。它在集群实例之间都是可用的并且允许你将程序移动到另一个集群上去。
savepoints.state.backend: filesystem
Savepoints.state.backend.fs.dir: hdfs:///flink/savepoints
注意:如果你不配置一个指定的目录,则会使用JobManager的backend
重要注意事项:一个savepoint是一个完整检查点的指针,这意味着savepoint的状态不仅仅会在savepoint文件本身中找到,还需要检查点的数据(例如在另一堆文件中)。因此,为savepoint使用filesystem backend而为检查点使用jobmanager backend并不能发挥作用,这是因为在JobManager重启之后就无法请求道检查点数据了。
三、用户程序的修改
savepoint是开箱即用的,但我们强烈建议你轻度地调整你的程序以使其可以在程序未来的版本中仍可以使用savepoint。
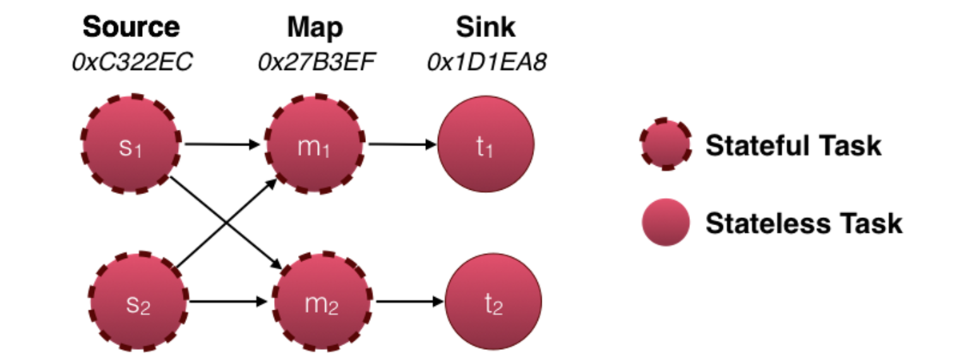
对于savepoint来说,只有有状态的Task才重要。在上面的例子中,source和map的task是有状态的,而sink是无状态的,因此,只有source和map的task才会属于savepoint范围之内。
每个Task都使用生成的Task ID和subtask index来进行标识。在上面的例子中source(s1,s2)的状态以及map(m1.m2)的状态是由对应task ID(source Task是0xC322EC,而map task是0x27B3EF)和subtask index标识的。而sink(t1,t2)没有状态,因此他们的ID并没有用。
重要注意事项:ID是从你的程序结构中确切(deterministically)生成的,这意味着只要你的程序不发生改变,这些ID也不会改变。只有用户方法内才允许改变,例如你可以在不改变topology的前提下修改MapFunction的实现。在这种情况下,在从savepoint恢复程序时,我们可以直接将状态映射到相同的task ID和subtask index处便是一个。该方法使得你可以开箱即用savepoint,但是这回在你改变topology时产生问题,因为这将导致ID的变化,从而使你无法再将savepoint状态映射到你的程序。
建议:为了修改你的程序并且拥有固定的ID,DataStream API提供了方法来人工指定task ID。每个Operator都提供了uid(String)的方法来覆盖生成的ID。ID是一个字符串,它将决定性地hash到一个16byte的哈希值。对每个transformation和job都拥有唯一的ID是非常重要的,如果不唯一,则job的提交将会失败。
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id")
.shuffle()
// The stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id")
//
Stateless sink (no specific ID required)
stream.print()
四、命令行客户端
你可以通过command line client控制savepoint
五、目前版本的局限性
· 并行度:在恢复一个savepoint时,程序的并行度需要与生成savepoint的原程序的并行度匹配,目前还没有机制来为savepoint的状态进行重新分区(re-partition)。
· 链接(chaining):链接Operator通过第一个task的ID标识,为一个链接的task的中间task人工赋值一个ID是不可能的。例如链接[ a -> b -> c]中只有a可以拥有人工赋值的ID,而b和c不行。若要绕开这个问题,你可以人工定义任务链接。如果你依靠的是自动ID赋值,对链接行为的改变同样会引起ID的改变。
· 销毁自定义状态handle:销毁旧的savepoint无法用于自定义state handles(如果你增在使用自定义state backend的话),这是因为用户代码的class loader在disposal时是不可用的。