
unicode和utf-8编码


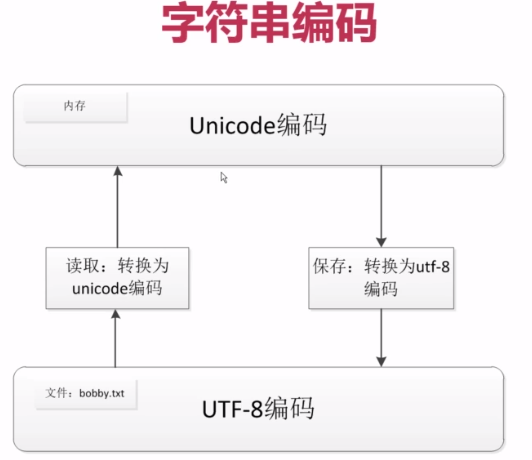
PS:数据在内存里,使用unicode编码会方便很多,因为这样占用的bit是统一的,而utf8对于不同的语言占用的bit不同的,但存储文件使用utf8编码会减少很多空间,所以需要灵活转换。
下面是py2中的例子,python存储在内存里的数据是自动转化成unicode编码的,通过sys库的getdefaultencoding方法可以查看python2解释器的默认编码是:ascii码,
变量s是英文,直接编码成utf8没问题,但变量su是中文,直接编码成utf8会报错,因为执行encode的时候,实际上会先调用decode,而传参是python的默认编码(ascii)。
注意一点:我这里是在unbuntu操作的,linux终端的默认编码是utf8,变量su是经过了linux的一层转换,所以使用decode时传参是utf8,在windows里,默认编码是gb2312
再注意一点:decode方法的作用是把别的编码格式的数据解码成unicode,encode方法是把数据 编码 成指定编码格式的数据。
>>> s = "English" >>> su = "中文" >>> import sys >>> sys.getdefaultencoding() 'ascii' >>> s.encode("utf8") 'English' >>> su.encode("utf8") Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) >>> su1 = su.decode("utf8") >>> su1 u'u4e2du6587' >>> su1.encode("utf8") 'xe4xb8xadxe6x96x87' >>> su 'xe4xb8xadxe6x96x87' >>> suu2 = u"中文" >>> suu2 u'u4e2du6587' >>> suu2.encode("utf8") 'xe4xb8xadxe6x96x87' >>>
在py3,python解释器的默认编码统一成unicode.