通过scrapy的Request和parse,我们能很容易的爬取所有列表页的文章信息。
PS:parse.urljoin(response.url,post_url)的方法有个好处,如果post_url是完整的域名,则不会拼接response.url的主域名,如果不是完整的,则会进行拼接
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request #这个是python3中的叫法,python2中是直接import urlparse from urllib import parse class JobboleSpider(scrapy.Spider): # 爬虫名字 name = 'jobbole' # 运行爬取的域名 allowed_domains = ['blog.jobbole.com'] # 开始爬取的URL start_urls = ['http://blog.jobbole.com/tag/linux/'] #start_urls = ['https://javbooks.com/content_censored/169018.htm'] def parse(self,response): """ 获取文章列表页url :param response: :return: """ blog_url = response.css(".floated-thumb .post-meta .read-more a::attr(href)").extract() for post_url in blog_url: #scrapy内置了根据url来调用“页面爬取模块”的方法Resquest,入参有访问的url和回调函数 yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail) #由于伯乐在线的文章列表页里的href的域名是全称”http://blog.jobbole.com/112535/“ #但存在href只记录112535的情况,这时候需要拼接出完整的url,可以使用urllib库的parse函数 #Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail) print(post_url) #下一页url next_url = response.css(".next.page-numbers::attr(href)").extract_first() if next_url: yield Request(url=parse.urljoin(response.url,next_url),callback=self.parse) def parse_detail(self, response): """ 获取文章详情页 :param response: :return: """ ret_str = response.xpath('//*[@class="dht_dl_date_content"]') title = response.css("div.entry-header h1::text").extract_first() create_date = response.css("p.entry-meta-hide-on-mobile::text").extract_first().strip().replace("·", "").strip() content = response.xpath("//*[@id='post-112239']/div[3]/div[3]/p[1]")
Items
主要目标是从非结构化来源(通常是网页)提取结构化数据。Scrapy爬虫可以将提取的数据作为Python语句返回。虽然方便和熟悉,Python dicts缺乏结构:很容易在字段名称中输入错误或返回不一致的数据,特别是在与许多爬虫的大项目。
要定义公共输出数据格式,Scrapy提供Item类。 Item对象是用于收集所抓取的数据的简单容器。它们提供了一个类似字典的 API,具有用于声明其可用字段的方便的语法。
各种Scrapy组件使用项目提供的额外信息:导出器查看声明的字段以计算要导出的列,序列化可以使用项字段元数据trackref 定制,跟踪项实例以帮助查找内存泄漏(请参阅使用trackref调试内存泄漏)等。
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ArticlespiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class JoBoleArticleItem(scrapy.Item): #标题 title = scrapy.Field() #创建日期 create_date = scrapy.Field() #文章url url = scrapy.Field() #url是长度不定的,可以转换成固定长度的md5 url_object_id = scrapy.Field() #图片url front_image_url = scrapy.Field() #图片路径url front_image_path = scrapy.Field() #点赞数 praise_num = scrapy.Field() #评论数 comment_num = scrapy.Field() #收藏数 fav_num = scrapy.Field() #标签 tags = scrapy.Field() #内容 content = scrapy.Field()
scrapy内置了文件下载、图片下载等方法,可以通过scrapy源码文件查看有哪些:
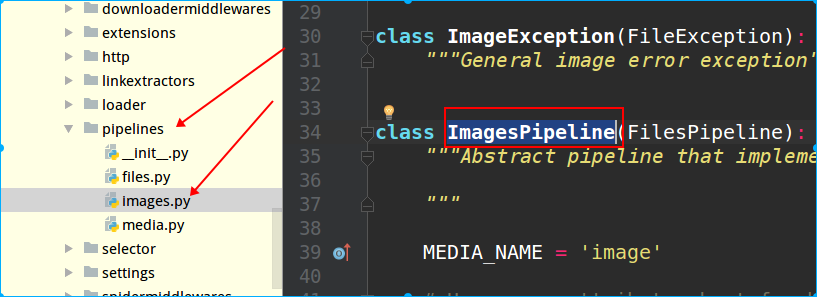
PS:scrapy存储数据的配置文件是在project目录下的pipelines.py中,而查看内置了哪些下载的类,也在源码的pipelines目录里,如下图所示:
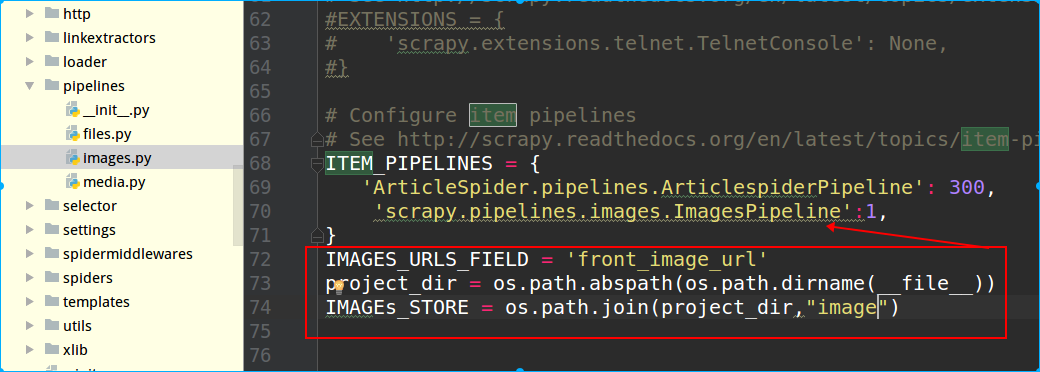
接着在settings.py里配置,在ITEM_PIPELINES字典里配置上这个类,这个字典是scrapy自带的,默认在settings里是注释掉的,后面的数字表示优先级,数值越小,调用时优先级越高。接着配置图片的Item字段
IMAGES_URLS_FIELD = 'front_image_url'
IMAGES_URLS_FIELD是固定写法,front_image_url是item名称
IMAGEs_STORE指定图片存放路径
PS:python保存图片时,需要先安装一个库:pillow
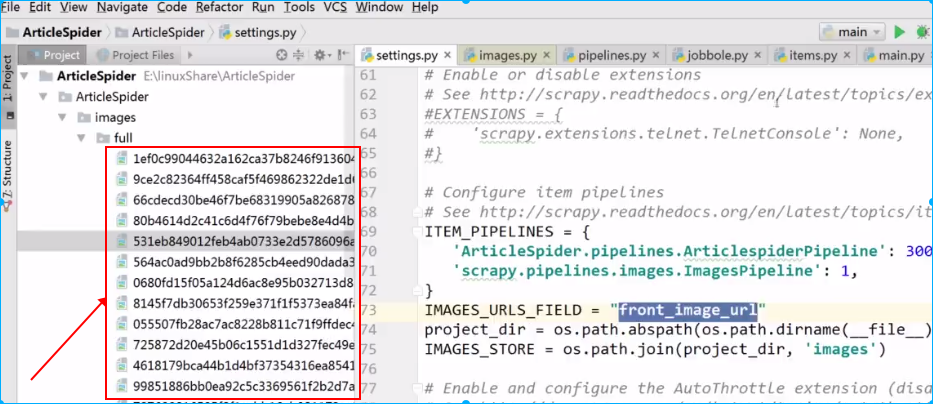
上面的图片保存下来后,发现scrapy会自动给图片命名,如果不想使用这种名称,比如想使用文章的路径名,那可以在pipeline.py文件里进行自定义。
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline class ArticlespiderPipeline(object): def process_item(self, item, spider): return item #进行图片下载定制,可以通过继承scrapy内置的imagespipeline来重载某些功能 class ArticleImagePipeline(ImagesPipeline): #通过查看ImagesPipeline类可以了解是由下面这方法图片命名 def item_completed(self, results, item, info): pass
上面这个item_completed方法是ImagePipeline里的,这里我们需要对它进行重载,但是关于里面的入参,可以通过pycharm的debug调试查看:
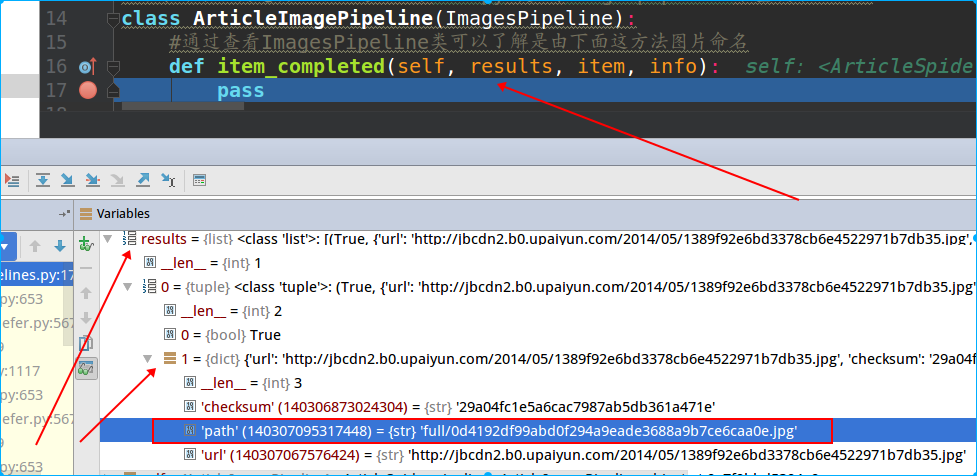
可以看到result是个是个tuple,第一个值是返回状态,第二个是个嵌套dict,其中path是我们想要的。
#进行图片下载定制,可以通过继承scrapy内置的imagespipeline来重载某些功能 class ArticleImagePipeline(ImagesPipeline): #通过查看ImagesPipeline类可以了解是由下面这方法图片命名 def item_completed(self, results, item, info): for ok,value in results: image_file_path = value['path'] item['front_image_url'] = image_file_path return item
再接着,是把url名称进行md5加密,这样可以让url变成一个唯一的且长度固定的值
可以在项目里单独创建个目录,用来存放这些函数:
# -*- conding:utf-8 -*- import hashlib def get_md5(url): if isinstance(url,str): url = url.encode("utf-8") m = hashlib.md5() m.update(url) return m.hexdigest() if __name__ == "__main__": print(get_md5("www.baidu.com"))
结果:
dab19e82e1f9a681ee73346d3e7a575e
然后调用这个函数存到item里就行:
article_item["url_object_id"] =get_md5(response.url)