1.简单说明爬虫原理
爬虫就是通过互联网各个沾点组成的节点网,通过代码返回给浏览器,然后解析这部分的代内容,将网页内的内容简洁地呈现在我们的面前。爬虫的流程可以分为:发送请求、获取响应内容、解析内容、保存数据。
2.使用 requests 库抓取网站数据;
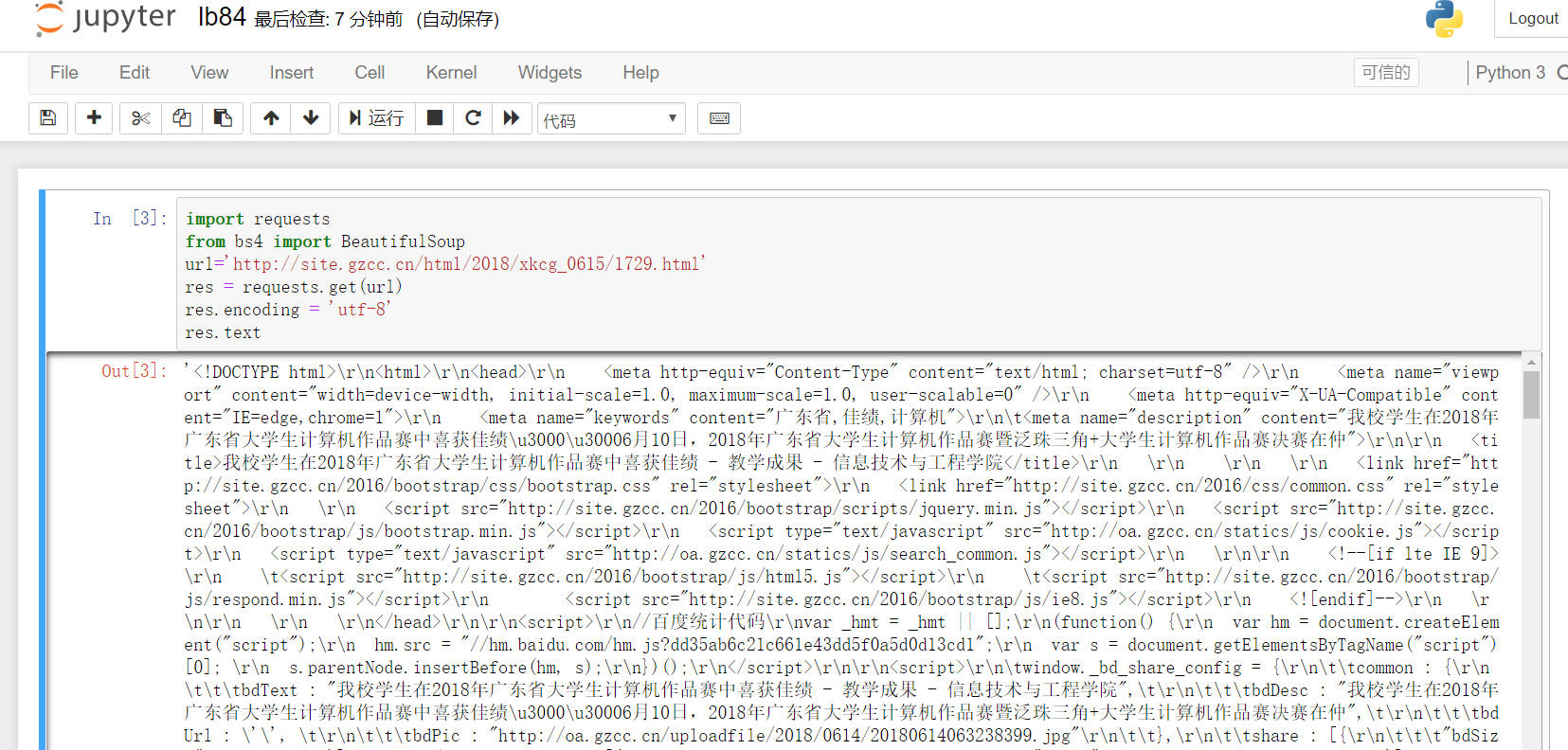
import requests from bs4 import BeautifulSoup url='http://site.gzcc.cn/html/2018/xkcg_0615/1729.html' res = requests.get(url) res.encoding = 'utf-8' res.text
3.了解网页
写一个简单的html文件,包含多个标签,类,id
<html>
<head>
<h1 id="title">简单视频网页</h1>
</head>
<body>
<div>
<p1>腾讯视频网页<p1><br>
<a href="https://v.qq.com/?ptag=qqbsc" >腾讯视频</a>
</div>
</body>
</html>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
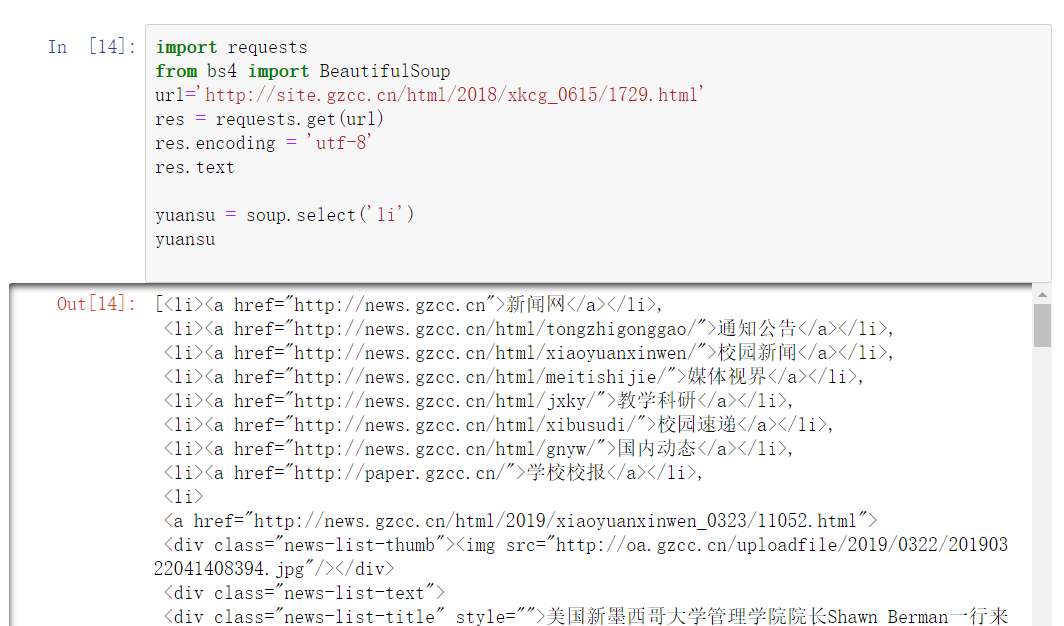
import requests from bs4 import BeautifulSoup url='http://site.gzcc.cn/html/2018/xkcg_0615/1729.html' res = requests.get(url) res.encoding = 'utf-8' res.text yuansu = soup.select('li') yuansu
找出含有特定类名的html元素
tedinglei = soup.select('.news-list-title') tedinglei

找出具有特定id名的html元素
id = soup.select('#q') id

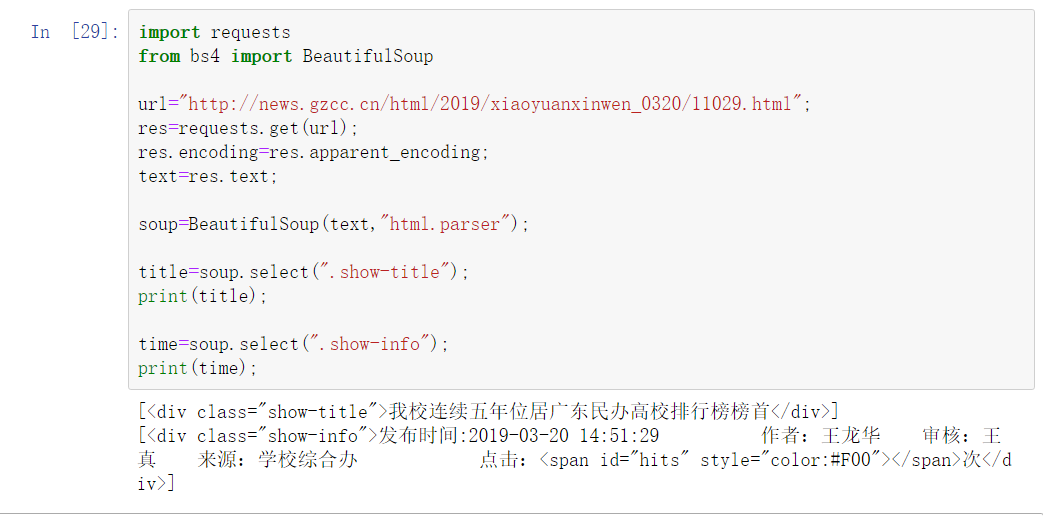
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
import requests from bs4 import BeautifulSoup url="http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html"; res=requests.get(url); res.encoding=res.apparent_encoding; text=res.text; soup=BeautifulSoup(text,"html.parser"); title=soup.select(".show-title"); print(title); time=soup.select(".show-info"); print(time);