一、grep简介:
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。Unix的grep家族包括grep、egrep和fgrep
表达符集
^
锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$
锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
.
匹配一个非换行符('
')的字符如:'gr.p'匹配gr后接一个任意字符,然后是p。
*
匹配零个或多个先前字符 如:' *grep' (注意*前有空格)匹配所有零个或多个空格后紧跟grep的行,需要用egrep 或者grep带上 -E 选项。 .*一起用代表任意字符。
[]
匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^]
匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-F和H-Z的一个字母开头,紧跟rep的行。
(..)
标记匹配字符,如'(love)',love被标记为1。
<
锚定单词的开始,如:'<grep'匹配包含以grep开头的单词的行。
>
锚定单词的结束,如'grep>'匹配包含以grep结尾的单词的行。
x{m}
重复字符x,m次,如:'o{5}'匹配包含5个o的行。
x{m,}
重复字符x,至少m次,如:'o{5,}'匹配至少有5个o的行。
x{m,n}
重复字符x,至少m次,不多于n次,如:'o{5,10}'匹配5--10个o的行。
w
匹配文字和数字字符,也就是[A-Za-z0-9],如:'Gw*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
W
w的反置形式,匹配一个或多个非单词字符,如点号句号等。
用于egrep和 grep -E的元字符扩展集
+
匹配一个或多个先前的字符。如:'[a-z]+able',匹配一个或多个小写字母后跟able的串,如loveable,enable,disable等。
?
匹配零个或一个先前的字符。如:'gr?p'匹配gr后跟一个或没有字符,然后是p的行。
a|b|c
匹配a或b或c。如:grep|sed匹配grep或sed
()
分组符号,如:love(able|rs)ov+匹配loveable或lovers,匹配一个或多个ov。
参数选项:
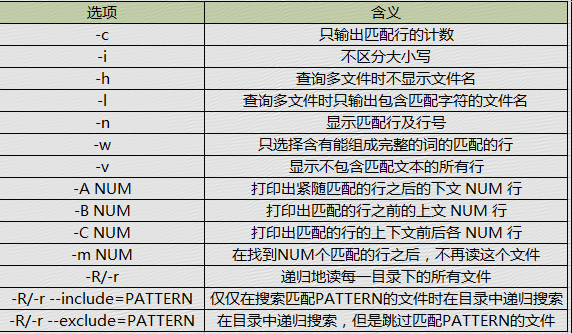
列出个别使用频发的选项
1、-v 显示不包含匹配文本的所有行
过滤掉文件中aaa的行数

2、-l 输出匹配的文件名
-l 查询多文件时只输出包含匹配字符的文件名,而不输出文本行。
$grep -l "lcj" * datafile
3、-i 忽略大小写
-i 关闭大小写敏感性。
示例,查找含有“lcj”这三个字符的行,并且不区分大小写:
[root@lcj lcj]# cat aa.txt aaaa BBBB cccc DDDD eeee EEEE [root@lcj lcj]# grep bb aa.txt [root@lcj lcj]# grep -i bb aa.txt BBBB [root@lcj lcj]#
4、-n 显示匹配的行及行号
示例:查找aa.txt文件中含有“CAD”的所有行,并显示行号:
[root@lcj lcj]# grep -n c aa.txt 3:cccc [root@lcj lcj]#
二、awk简介
实例:
截取文件中指定字段;

需要截取GET后面的html数据,前提是要过滤出http 状态码为200
grep “” 200 :过滤出http状态码为200
awk -F “GET”:指定从那列开始截取
‘{print $2}’:去除字段之间的空格进行截取【如: _"GET_ /11260464.html 】
上面截图虽然前面的字段是我们所需要的字段,可后面还有多余的数据,如下过滤后面多余的数据:

awk '{print $1}':去除第一个空格之后的所有数据
head:显示前面10条数据,方便查看数据截取结果,最后可以通过>进行重定向指定文件中
案例
增加“grep”和“awk“命令结合使用案列:
案例:需要获取GET请求 ,状态码为200,并过滤掉json和area字段的所有行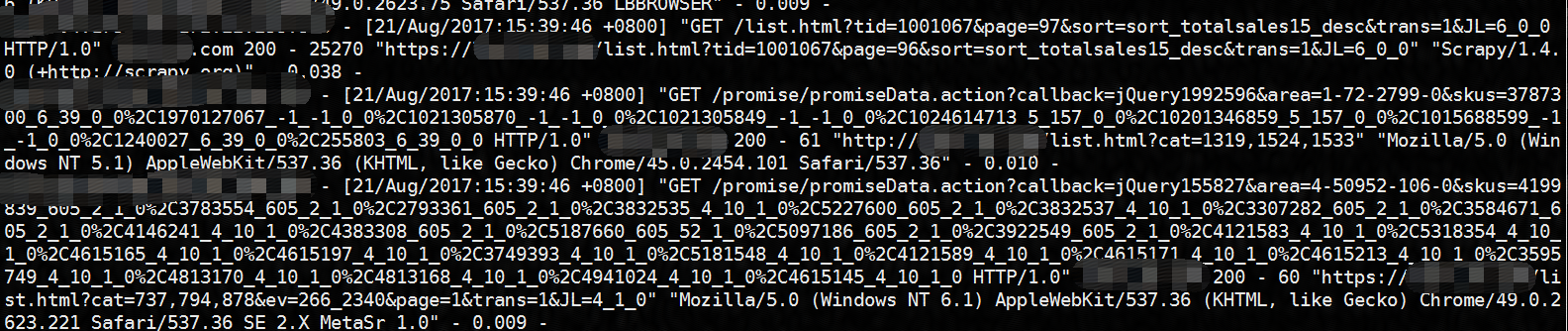
[root@lcj lcj]# cat 200.txt |grep " 200 " | awk -F"GET" '{print $2}'| awk '{print $1}' | grep -v "/js/" |grep -v area >test001.csv
grep -v过滤字段所在行
继续完善中、、、、、