GC调优
参考:美团JVM调优文章
参数例子
java -jar -Xmx1024m -Xms1024m -Xmn256m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/jvmlogs/ -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+PrintReferenceGC -Xloggc:/usr/local/gclogs xxx.jar
JVM常见参数
| 参数 | 作用 |
|---|---|
| -Xmx1024m | 配置堆最大内存 |
| -Xms1024m | 配置堆最小内存 |
| -Xmn256m | 配置新生代内存 |
| -Xss256k | 配置栈的大小 |
| -XX:SurvivorRatio=8 | 配置2个Survivor区和Eden区大小比为1:1:8 |
| -XX:NewRatio=2 | 配置新生代和老年代大小比为1:2 |
| -XX:+HeapDumpOnOutOfMemoryError | 发生OOM时输出堆Dump文件 |
| -XX:HeapDumpPath=/opt/jvmlogs/ | Dump文件保存位置 |
| -XX:+UseConcMarkSweepGC | 使用CMS对老年代GC |
| -XX:+UseParNewGC | 使用并发ParNew收集器对年轻代GC |
| -XX:PretenureSizeThreshold=xx | 大于xx字节的对象直接进入老年代,默认0(超过Eden区大小直接进入老年代,否则都先分配在Eden区中) |
| -XX:MaxTenuringThreshold=xx | 新生代年龄超过xx后,进入老年代,默认6 |
调优工具
- 命令行:
JDK提供:jps、jinfo、jstat、jstack、jmap
第三方整合:jcmd、vjtools、arthas、greys - 可视化:
JConsole、JVisualvm、MAT、JProfiler
dashboard #查看jvm整体运行情况 ctrl+c退出
thread -n 3 -i 10000 #10秒内最忙的3个线程
trace com.demo.Test run -n 1 "#cost > 100" #追踪com.demo.Test的run()方法执行超过100ms的情况,追踪1次之后就退出
jad com.demo.Test #反编译Test
调优目的
GC调优的目的是降低GC的停顿时间,增大GC的吞吐量
调优的策略
- 减少FullGC次数,因为FullGC是STW(全局停顿)的
- 通过
-Xmn配置,配置新生代的大小,更多利用MinorGC - 通过
-XX:PretenureSizeThreshold配置大对象进入老年代,避免大对象占用过多的新生代空间,导致过多对象进入了老年代,导致FullGC次数增加 - 通过
-XX:MaxTenuringThreshold=配置进入老年代的代数,合理的配置可以减少FullGC,更多地利用MinorGC - 配置合理的固定大小的堆空间,避免扩容导致的FullGC
调优的指标
- 延迟:一次STW的时间,越短越好,可以适当增加次数
- 吞吐量:系统运行100s,GC时间1s,则吞吐量为99%
- MinorGC 50ms完成,10s一次;
- FullGC 1s完成,10分钟一次即是合理的
查看GC日志
GC日志记录每次GC的详细情况,包括回收的时间,回收的大小,需要配置JVM运行参数
| 参数 | 作用 |
|---|---|
| -XX:+PrintGC | 打印GC日志 |
| -XX:+PrintGCDetails | 打印详细日志 |
| -XX:+PrintGCTimeStamps | 打印GC时间戳 |
| -XX:+PrintGCDateStamps | 打印GC日期时间 |
| -XX:+PrintHeapAtGC | GC前后打印堆信息 |
| -Xloggc:/usr/local/gclogs | GC日志的保存位置 |
分析GC的思路
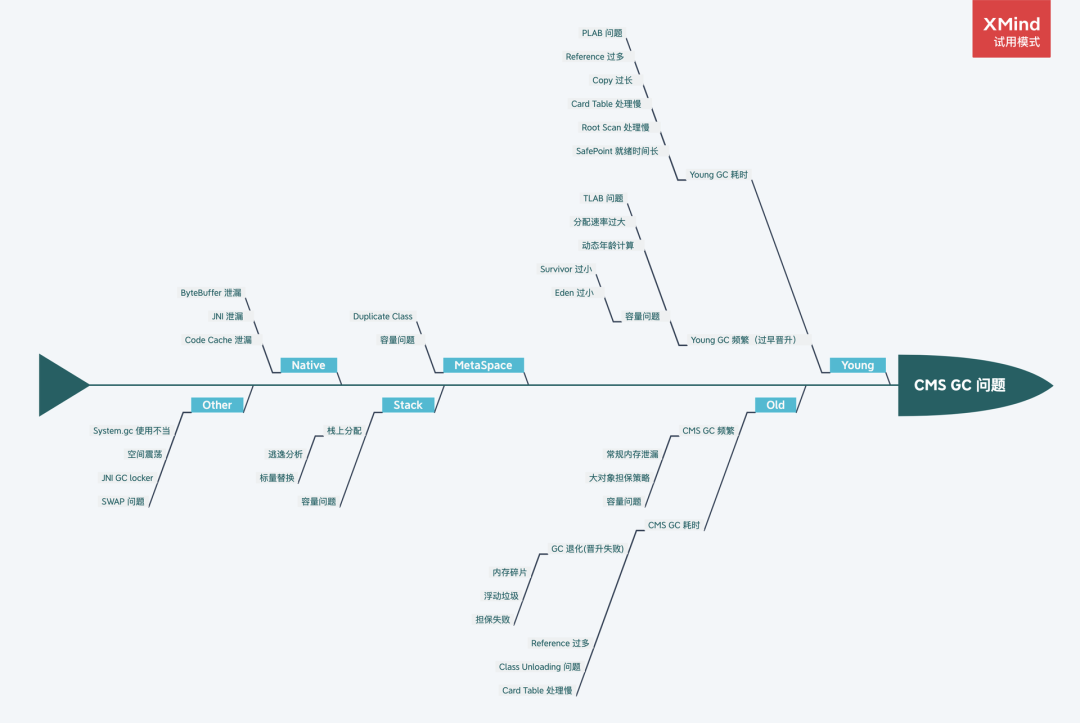
RT(Real Time)上涨相关原因:GC耗时增加、慢查询、锁Block积压、CPU负载升高,最终导致了RE上涨
内存溢出OOM场景
1.内存震荡
现象
在项目启动时,发生了频繁的扩容,从而频繁地GC
原因
由于没有配置固定的-Xmx和-Xms,在项目启动时,每当容量不够需要扩容时,都会进行GC,次数就比较频繁,所以启动时的STW时间会比较长。也可以配置扩容、缩容的内存比值来控制内存多大时进行扩容缩容。
解决
配置固定-Xmx和-Xms,避免频繁扩容和GC
2.显示GC(System.gc())是否要关闭
现象
非常规现象比如空间不足、对象空间担保失败等导致的FullGC,可能是代码中调用了System.gc()导致的
是否要保留System.gc()
保留
CMS中的FullGC分为Background和Foreground,一个是后台执行的,并发收集的。而Foreground是进行的MSC(Mark-Sweep-Compact,标记清理并压缩),这会导致较长的STW。
去除
可以通过配置-XX:+DisableExplicitGC来关闭System.gc()触发的gc。
但是,在使用NIO的时候,NIO在DirectByteBuffer分配内存的时候会主动调用一次System.gc(),而如果关闭了的话,就会导致NIO使用的直接内存区没来得及回收,就会导致OOM。
原因:NIO使用到的DirectByteBuffer直接内存区只有在CMS进行FullGC的时候才回收,YoungGC的时候则不会,如果关闭了System.gc(),就可能发生以下情况:FullGC迟迟不进行,而NIO开辟了过多的DirectByteBuffer,来不及回收,就发生了OOM。
策略
- 不使用
-XX:+DisableExplicitGC - 使用
XX:+ExplicitGCInvokesConcurrent、XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses来将CMS的Foreground改为Background
3.MetaSpace的OOM
现象
项目运行起来之后,MetaSpace持续上涨,直至导致OOM
原因
往往是反射、字节码增强、CGLIB动态代理、OSGi自定义类加载器等技术,需要往MetaSpace中加载class,而没有回收
策略
- 使用
-XX:+TraceClassLoading和-XX:+TraceClassUnLoading在类加载、卸载的时候输出日志,进行排查 - 少用反射,比如Apache的BeanUtils等
- 使用命令
jcmd <PID> GC.class_stats|awk '{print$13}'|sed 's/(.*).(.*)/1/g'|sort |uniq -c|sort -nrk1打印输出类加载的情况,查看哪个包的Class最多 - 配置
-XX:SoftRefLRUPolicyMSPerMB=1000,需要保证反射需要的软引用class有足够的时间存活,以便后续使用,否则每次就会清理掉软引用对象,并在下次生成新的对象
4.过早晋升
现象
- GC日志中,有比如
Desired survivor size xxx bytes, new threshold 1(max 6)等信息,new threshold 1表示经过1次YoungGC就进入了老年代中 - FullGC频繁,且GC之后,老年代的占用比例大幅下降,比如FullGC前是70%,而GC之后变成了10%,这就说明被GC的那60%的部分中,绝大部分应该在YoungGC中被回收掉
原因
Eden区过小。Eden区过小 -> 单位时间内Eden区内存更快到达GC阈值 -> 更频繁发生YoungGC -> 年龄增加直至晋升老年代。YoungGC耗时主要是复制算法copying的耗时。
对象产生的速度太快
并且,还容易触发动态年龄判定:YoungGC当某个年龄X的对象超过一定比例时,当新的对象年龄达到X时则直接晋升Old了,导致更多对象进入Old,MaxTenuringThreshold对它则不起作用了。
MaxTenuringThreshold配置过大:晋升过晚,Survivor区可能被占满,导致溢出并让晋升机制失效,所有对象直接进入老年代
MaxTenuringThreshold配置过小:晋升过早,频繁发生FullGC
策略
适当增加Young区的比例或者虚拟机整体的大小
5.CMS过于频繁
现象
CMS对Old的GC比较频繁,虽然STW的耗时不长,但是总体的吞吐量下降了
原因
每次YoungGC的时候,CMS有一个线程则一直轮训判断是否达到了CMS GC的阈值,达到了则进行GC,未达到则休眠,周期默认为2s。
这与CMS的配置相关:XX:UseCMSInitiatingOccupancyOnly 、-XX:CMSInitiatingOccupancyFraction比例默认92%。也就是说,每次YoungGC伴随一次CMS的判断,如果阈值一直处于较高状态,Old中有对象没有被清理掉,则每次YoungGC之后都会发生一次CMS的GC
策略
常见的导致这种现象原因有:各种数据库、网络链接,带有失效时间的缓存等。要如何判断到底是哪些个对象导致的,就需要通过各种分析途径来分析。
使用MAT:关注Dump Diff、Leak Suspects、Top Component、Unreachable
6.CMS单次时间过长
现象
一次Old GC一般不超过1000ms是合理的,但是如果出现一次Old GC的时间远大于1000ms就需要注意了
原因
CMS的Old GC是Background的,STW主要发生在Initial Mark和Final Remark。
Initial Mark流程:

Final Remark流程:

如何排查:增加配置-XX:+PrintReferenceGC,可以看到类似的日志:
2019-02-27T19:55:37.920+0800: 516952.915: [GC (CMS Final Remark) 516952.915: [ParNew516952.939: [SoftReference, 0 refs, 0.0003857 secs]516952.939: [WeakReference, 1362 refs, 0.0002415 secs]516952.940: [FinalReference, 146 refs, 0.0001233 secs]516952.940: [PhantomReference, 0 refs, 57 refs, 0.0002369 secs]516952.940: [JNI Weak Reference, 0.0000662 secs]
[class unloading, 0.1770490 secs]516953.329: [scrub symbol table, 0.0442567 secs]516953.373: [scrub string table, 0.0036072 secs][1 CMS-remark: 1638504K(2048000K)] 1667558K(4352000K), 0.5269311 secs] [Times: user=1.20 sys=0.03, real=0.53 secs]
可以看到Final Reference、class unloading还有scrub symbol table的耗时是比较长的,所以可以通过以下策略
策略
增加配置-XX:+PrintReferenceGC,根据Dump文件分析
Final Reference:首先,通过优化代码代码的方式;其次,如果没有第一时间定位发生问题的代码,可以添加配置-XX:+ParallelRefProcEnabled,来并发处理;
scrub symbol table:表示清理元数据符号引用耗时,符号引用是 Java 代码被编译成字节码时,方法在 JVM 中的表现形式,生命周期一般与 Class 一致。可以通过避免MetaSpace的处理:-XX:-CMSClassUnloadingEnabled
7.内存碎片&收集器退化
现象
收集器退化之后,一次Full GC的STW会很长
原因
- 晋升失败:YoungGC时,Survivor区放不下,然后晋升Old区,但是Old区也放不下。一是因为Old区被迅速填满导致空间不足,主要原因可能是空间担保分配失败;二是因为内存碎片导致连续空间不足
- 增量空间担保失败:
- 并发模式失败(浮动垃圾):CMS GC时,Young GC也在发生,而CMS GC没有处理浮动垃圾,导致空间不足,就发生了
Concurrent Mode Failure
策略
- 空间碎片:添加此配置让Full GC时对Old区进行压缩
-XX:UseCMSCompactAtFullCollection=true,并且添加配置-XX: CMSFullGCsBeforeCompaction=X,表示X次FullGC后进行压缩 - 增量收集:配置
-XX:CMSInitiatingOccupancyFraction=XX,相当于Old区已占用达到XX%时就进行CMSGC,配置-XX:+UseCMSInitiatingOccupancyOnly保证CMSInitiatingOccupancyFraction一直有效 - 浮动垃圾:可以配置
NewRatio来保证Old区足够大,还可配置-XX:+CMSScavengeBeforeRemark来让每次CMS GC前,触发一次Young GC
8.堆外内存OOM
现象
内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。
原因
- 主动申请的内存未释放,参考场景二system.gc();
- JNI调用Native Code未释放
策略
使用Btrace跟踪问题
9.JNI导致的OOM
鱼骨图
参考:美团JVM调优文章