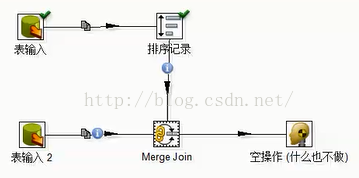
Kettle正常转换速度
|
场景 |
正常 |
不正常 |
|
数据库操作 |
3k-2w条/秒 |
2000条/秒以下 |
|
文件操作 |
2w条/秒以上 |
1w条以下 |
|
http、get、set |
比数据库慢 |
容易产生性能问题的场景
查询类:
数据库查询:数据库查询、数据库连接、插入更新
Web查询 :http/get/set webservice
计算类
格式转换(字节与字符互相转换,日期)、
转换一般用计算器和JavaScript方法。
排序类
排序、合并连接(依赖于排序)、分组(依赖于排序)
调优的关键:Rowset
Rowset是两个步骤之间的缓存(大小可以自己设置)
如何找到性能瓶颈:观察Rowset,运行ktr文件时观察下面的窗口值(100/0表示输入100条记录,输出0条记录。如果输入远大于输出,就说明这个步骤来不及处理,就是瓶颈。)

Rowset值的设置:编辑》设置》杂项》记录集合里的记录数》10000,表示缓存里的最大记录数就是10000
其他观察方法:性能图,和步骤度量效果一样。
如何提高性能
合理增加索引
数据库查询:尽可能多的使用相等=判断来筛选数据;如果是等值查询,表就建hash索引;如果是比较查询,就建B树索引
增加复制数:查询类。多线程,2-8个线程一个步骤。具体自己调整。
加大缓存:排序类,查询类。
集群:查询类、运算类、排序
更换其他的实现方式:JavaScript、Java类
注意日志级别:Rowlevel的性能是Basic级别的1/10
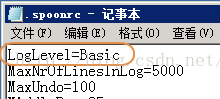
.spoonrc在.kettle目录下
注意死锁问题
数据库表死锁:读写同一个表(表现是ktr在running,卡在那不动)
转换本身死锁:
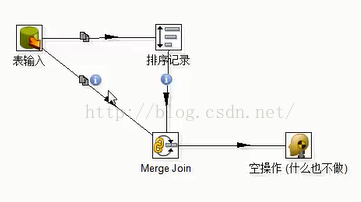
这里死锁的原因:排序记录要求将所有的记录都读取到之后再排序,缓存设置10000,发完要下游处理完才能再次发送。这样以来排序需要更多数据,而表输入是复制记录到两个下游,一个要更多的数据,一个不要更多的数据。所以,死锁。
解决办法: