前言
深度学习中的Attention,源自于人脑的注意力机制,当人的大脑接受到外部信息,如视觉信息、听觉信息时,往往不会对全部信息进行处理和理解,而只会将注意力集中在部分显著或者感兴趣的信息上,这样有助于滤除不重要的信息,而提升信息处理的效率。
最早将Attention利用在图像处理上的出发点是,希望通过一个类似于人脑注意力的机制,只利用一个很小的感受野去处理图像中Attention的部分,降低了计算的维度。而后来慢慢的,有人发现其实卷积神经网络自带Attention的功能,比方说在分类任务中,高层的feature map所激活的pixel也恰好集中在与分类任务相关的区域,也就是saliency map(图像显著性),常被用在图像检测和分割上。那么如何利用Attention来提升模型在分类任务上的性能呢?本文提供了一种新的思路。
Residual Attention Network
人们看到论文题目时一定会觉得很熟悉,哇靠,这不是模仿大名鼎鼎的ResNet吗,确实,从字面上、结构上、包括使用方法上,本文所提出的模型都和ResNet很相似,可以说是借鉴了ResNet的构造,但是从思路、目的上来看,又和ResNet大有不同,那么不同之处在于何,接下来将会娓娓道来。
首先看作者所说本文的三大贡献:
1.提出了一种可堆叠的网络结构。与ResNet中的Residual Block类似,本文所提出的网络结构也是通过一个Residual
Attention Module的结构进行堆叠,可使网络模型能够很容易的达到很深的层次。
2.提出了一种基于Attention的残差学习方式。与ResNet也一样,本文做提出的模型也是通过一种残差的方式,使得非常深的模型能够容易的优化和学习,并且具有非常好的性能。
3.Bottom-up Top-down的前向Attention机制。其他利用Attention的网络,往往需要在原有网络的基础上新增一个分支来提取Attention,并进行单独的训练,而本文提出的模型能够就在一个前向过程中就提取模型的Attention,使得模型训练更加简单。
从上面前两点依然发现本文所提出的方法和ResNet没多大的区别,但是把1、2、3点融合起来,就成了本文的一个亮点,请看:
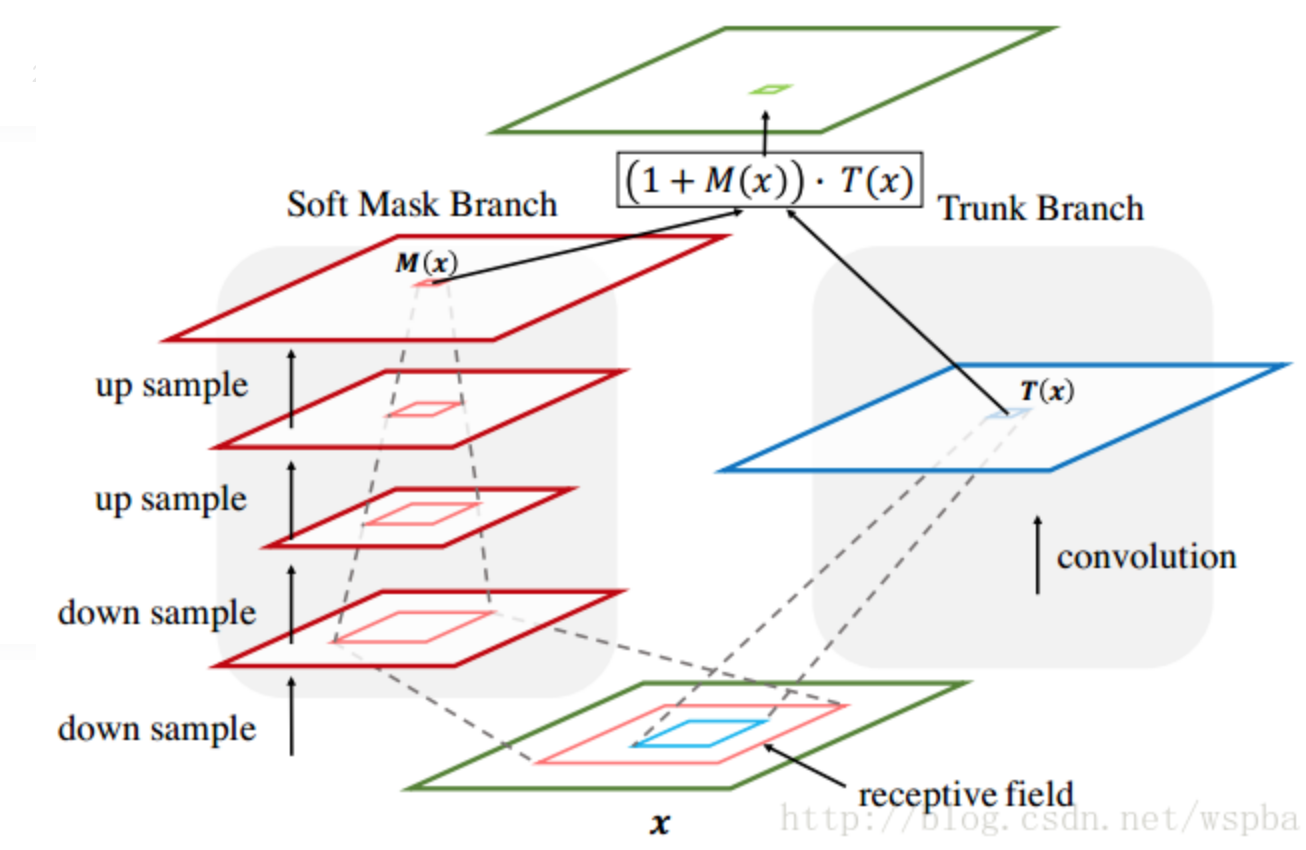
上图基本上可以囊括本位的绝大部分内容,对于某一层的输出feature map,
也就是下一层的输入
,对于一个普通的网络,只有右半部分,也就是Trunk Branch,作者在这个基础上增加了左半部分:Soft Mask Branch——一个Bottom-up Top-down的结构。
Bottom-up Top-down的结构首先通过一系列的卷基和pooling,逐渐提取高层特征并增大模型的感受野,之前说过高层特征中所激活的Pixel能够反映Attention所在的区域,于是再通过相同数量的up sample将feature map的尺寸放大到与原始输入一样大
(这里的upsample通过deconvolution(逆卷积)来实现,
可以利用bilinear interpolation 也可以利用deconvolution自己来学习参数,可参考FCN中的deconvolution使用方式),这样就将Attention的区域对应到输入的每一个pixel上,我们称之为Attention map。
Bottom-up Top-down
这种encoder-decoder
的结构在图像分割中用的比较多,如FCN,
也正好是利用了这种结构相当于一个weakly-supervised的定位任务的学习
接下来就要把Soft Mask Branch与Trunk Branch的输出结合起来
,Soft Mask Branch输出的Attention map中的每一个pixel值相当于对原始feature map上每一个pixel值的权重,
它会增强有意义的特征,
而抑制无意义的信息
,因此,
将Soft Mask Branch与Trunk Branch输出的feature map进行element-wised的(每个元素对应相乘)乘法,
就得到了一个weighted Attention map。
但是无法直接将这个weighted Attention map输入到下一层中,
因为Soft Mask Branch的激活函数是Sigmoid,输出值在(0,1)之间
(之所以这么做,我认为是不希望给前后两层的feature map带来太大的差异和扰动
,其次能够进一步的抑制不重要的信息),
因此通过一系列这样的乘法,
将会导致feature map的值越来越小,
并且也可能打破原始网络的特性,当层次极深时,给训练带来了很大的困难。
因此作者在得到了weighted Attention map之后又与原来Trunk Branch的feature map进行了一个element-wised的操作,这就和ResNet有异曲同工之妙,
该层的输出由下面这个式子组成:
其中M(x)为Soft Mask Branch的输出,F(x)为Trunk Branch的输出,那么当M(x)=0时,该层的输入就等于F(x),因此该层的效果不可能比原始的F(x)差,这一点也借鉴了ResNet中恒等映射的思想,同时这样的加法,也使得Trunk Branch输出的feature map中显著的特征更加显著,增加了特征的判别性。这样,优化的问题解决了,性能的问题也解决了,因此通过将这种残差结构进行堆叠,就能够很容易的将模型的深度达到很深的层次,具有非常好的性能。

. 基本原理
Attention模型最初应用于图像识别,模仿人看图像时,目光的焦点在不同的物体上移动。当神经网络对图像或语言进行识别时,每次集中于部分特征上,识别更加准确。如何衡量特征的重要性呢?最直观的方法就是权重,因此,Attention模型的结果就是在每次识别时,首先计算每个特征的权值,然后对特征进行加权求和,权值越大,该特征对当前识别的贡献就大。
机器翻译中的Attention模型最直观,易于理解,因为每生成一个单词,找到源句子中与其对应的单词,翻译才准确。此处就以机器翻译为例讲解Attention模型的基本原理。在此之前,需要先介绍一下目前机器翻译领域应用最广泛的模型——Encoder-Decoder结构,谷歌最新发布的机器翻译系统就是基于该框架[1],并且采用了Attention模型。
Encoder-Decoder框架包括两个步骤,第一步是Encoder,将输入数据(如图像或文本)编码为一系列特征,第二步是Decoder,以编码的特征作为输入,将其解码为目标输出。Encoder和Decoder是两个独立的模型,可以采用神经网络,也可以采用其他模型。机器翻译中的Encoder-Decoder示例如下图(取自[2]):