一、前言
一些网站的敏感数据(如商品价格)是不希望被爬虫抓取。所以在不影响seo的情况下,一般采取什么策略呢,前端又可以做些什么呢?
二、常见爬虫策略
反爬虫不是阻止爬虫抓取数据,这是不现实的,所以可以在数据上做手脚。一般如果希望页面能在用户面前正常展示,就必须要做到识别真人与机器人。因此工程师们做了各种尝试,这些策略大多采用于后端。比如:
1、User-Agent + Referer检测
2、账号及Cookie验证
3、验证码
但是爬虫可以模拟真人操作,比如:
-
模拟浏览器环境识别验证码
- 接入第三方识别验证码
三、前端思路
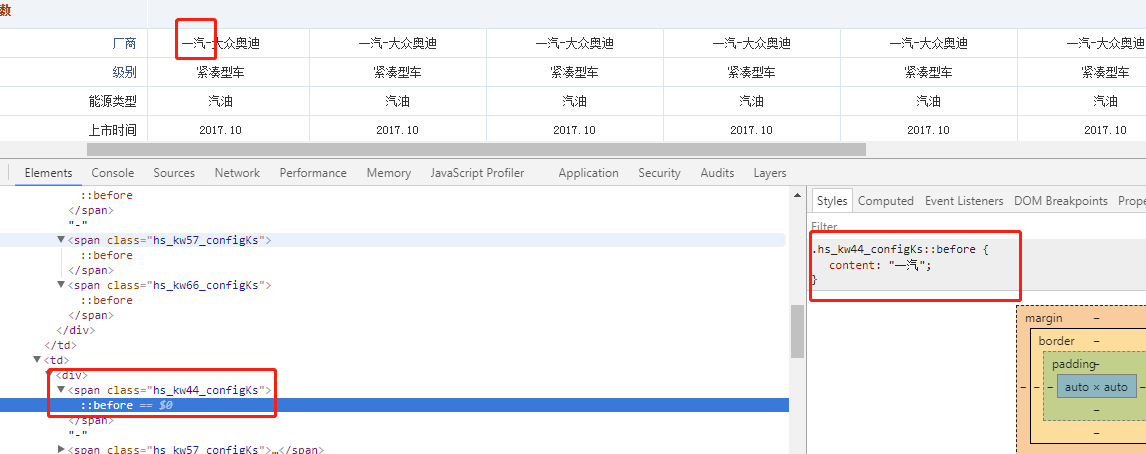
1、伪元素隐藏
把关键字写到伪元素的content里面,要爬取数据,必须解析css,这无疑增加了难度。
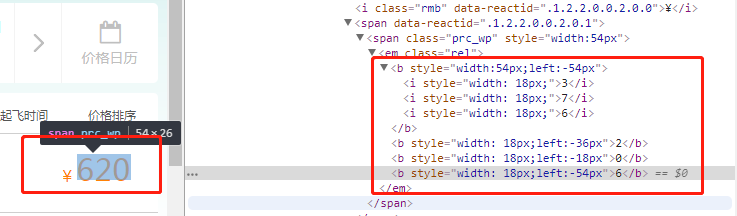
2、元素定位覆盖式
真实展示的价格是根据一定的规则(这个当然自己定义)错位产生的。爬虫抓取到数据一定会一脸懵逼。
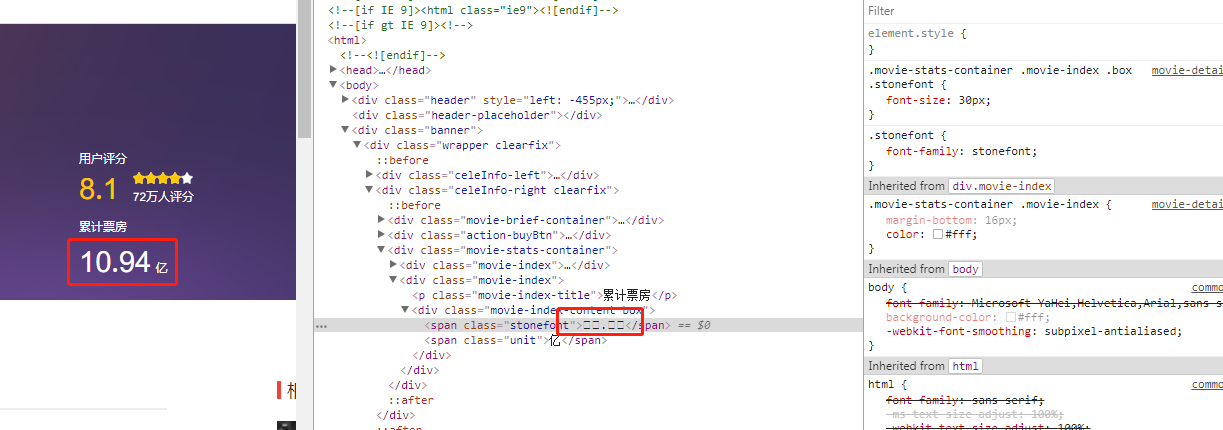
3、font-face
对于每日的电影院票价这一重要数据,源代码中展示的并不是纯粹的数字。而是在页面使用了font-face定义了字符集,并通过unicode去映射展示。比如unicode码在页面解析显示为:,爬虫只能抓取到这样的数据但是不知道后面的映射关系,所以也没办法;
动态的font字体
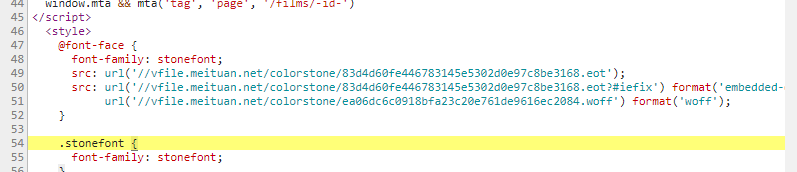
其实想破解这个还是有办法的,可以下载猫眼里面的字体库,然后找到映射关系。《反击“猫眼电影”网站的反爬虫策略》。
4、图片剪切

然后通过background-position去定位。
5、字符串分隔
不过不做混淆,趴下来再重组就可以还原了。