一、需求分析
1、Mybatis是什么?
一个半自动化的orm框架(Object Relation Mapping)。
2、Mybatis完成什么工作?
在面向对象编程中,我们操作的都是对象,Mybatis框架是一个数据访问层的框架,帮我们完成对象在数据库中的
存、取工作。
为什么称为半自动化?
关系型数据库的操作是通过SQL语句来完成的,Mybatis在帮我们做对象的存取时,需要我们提供对应的SQL语句,它不自动帮我们生成SQL语句,而只帮我们完成:
1)对象属性到SQL语句参数的自动填充;
2)SQL语句执行结果集到对象的自动提取;
所以称为半自动的。而我们了解的另一个ORM框架Hibernate则是全自动的。
半自动化的不足:我们得辛苦一点编写SQL语句。
半自动化的优点:我们可以完全把控执行的SQL语句,可以随时灵活调整、优化。
3、为什么要用Mybatis?
1)mybatis学习、使用简单
2)半自动化的优点
4、为什么要学好Mybatis?
一线互联网公司出于性能、调优、使用简单、完全可控的需要,在数据库访问层都是采用Mybatis。
5 、为什么要用orm框架?
都是为了提高生产效率,少写代码,少写重复代码!
不用orm框架,能用什么来完成数据的存取?
jdbc
看看jdbc编程的代码示例
package com.study.leesmall.sample.mybatis.jdbc; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.util.ArrayList; import java.util.List; import javax.sql.DataSource; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.datasource.DataSourceUtils; import org.springframework.stereotype.Component; import org.springframework.util.StringUtils; import com.study.leesmall.sample.mybatis.model.User; @Component public class UserDao { @Autowired private DataSource dataSource; public void addUser(User user) throws SQLException { try ( // 1、获取连接 Connection conn = DataSourceUtils.getConnection(dataSource); // 2、创建预编译语句对象 PreparedStatement pst = conn.prepareStatement( "insert into t_user(id,name,sex,age,address,phone,wechat,email,account,password) " + " values(?,?,?,?,?,?,?,?,?,?)");) { // 3、设置参数值 int i = 1; pst.setString(i++, user.getId()); pst.setString(i++, user.getName()); pst.setString(i++, user.getSex()); pst.setInt(i++, user.getAge()); pst.setString(i++, user.getAddress()); pst.setString(i++, user.getPhone()); pst.setString(i++, user.getWechat()); pst.setString(i++, user.getEmail()); pst.setString(i++, user.getAccount()); pst.setString(i++, user.getPassword()); // 4、执行语句 int changeRows = pst.executeUpdate(); } } public List<User> queryUsers(String likeName, int minAge, int maxAge, String sex) throws SQLException { // 1、根据查询条件动态拼接SQL语句 StringBuffer sql = new StringBuffer( "select id,name,sex,age,address,phone,wechat,email,account,password from t_user where 1 = 1 "); if (!StringUtils.isEmpty(likeName)) { sql.append(" and name like ? "); } if (minAge >= 0) { sql.append(" and age >= ? "); } if (maxAge >= 0) { sql.append(" and age <= ? "); } if (!StringUtils.isEmpty(sex)) { sql.append(" and sex = ? "); } try (Connection conn = DataSourceUtils.getConnection(dataSource); PreparedStatement pst = conn.prepareStatement(sql.toString());) { // 2 设置查询语句参数值 int i = 1; if (!StringUtils.isEmpty(likeName)) { pst.setString(i++, "%" + likeName + "%"); } if (minAge >= 0) { pst.setInt(i++, minAge); } if (maxAge >= 0) { pst.setInt(i++, maxAge); } if (!StringUtils.isEmpty(sex)) { pst.setString(i++, sex); } // 3 执行查询 ResultSet rs = pst.executeQuery(); // 4、提取结果集 List<User> list = new ArrayList<>(); User u; while (rs.next()) { u = new User(); list.add(u); u.setId(rs.getString("id")); u.setName(rs.getString("name")); u.setSex(rs.getString("sex")); u.setAge(rs.getInt("age")); u.setPhone(rs.getString("phone")); u.setEmail(rs.getString("email")); u.setWechat(rs.getString("wechat")); u.setAccount(rs.getString("account")); u.setPassword(rs.getString("password")); } rs.close(); return list; } } }
用JdbcTemplate的代码示例:
package com.study.leesmall.sample.mybatis.jdbc; import java.sql.ResultSet; import java.sql.SQLException; import java.util.ArrayList; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.jdbc.core.RowMapper; import org.springframework.util.StringUtils; import com.study.leesmall.sample.mybatis.model.User; //@Component public class UserDaoUseJdbcTemplate { @Autowired private JdbcTemplate jdbcTemplate; public void addUser(User user) throws SQLException { String sql = "insert into t_user(id,name,sex,age,address,phone,wechat,email,account,password) " + " values(?,?,?,?,?,?,?,?,?,?)"; jdbcTemplate.update(sql, user.getId(), user.getName(), user.getSex(), user.getAge(), user.getAddress(), user.getPhone(), user.getWechat(), user.getEmail(), user.getAccount(), user.getPassword()); } public List<User> queryUsers(String likeName, int minAge, int maxAge, String sex) throws SQLException { // 1、根据查询条件动态拼接SQL语句 StringBuffer sql = new StringBuffer( "select id,name,sex,age,address,phone,wechat,email,account,password from t_user where 1 = 1 "); List<Object> argList = new ArrayList<>(); if (!StringUtils.isEmpty(likeName)) { sql.append(" and name like ? "); argList.add("%" + likeName + "%"); } if (minAge >= 0) { sql.append(" and age >= ? "); argList.add(minAge); } if (maxAge >= 0) { sql.append(" and age <= ? "); argList.add(maxAge); } if (!StringUtils.isEmpty(sex)) { sql.append(" and sex = ? "); argList.add(sex); } return jdbcTemplate.query(sql.toString(), argList.toArray(), new RowMapper<User>() { public User mapRow(ResultSet rs, int rowNum) throws SQLException { User u = new User(); u.setId(rs.getString("id")); u.setName(rs.getString("name")); u.setSex(rs.getString("sex")); u.setAge(rs.getInt("age")); u.setPhone(rs.getString("phone")); u.setEmail(rs.getString("email")); u.setWechat(rs.getString("wechat")); u.setAccount(rs.getString("account")); u.setPassword(rs.getString("password")); return u; } }); } }
参数设置代码、结果集处理代码、JDBC过程代码都会大量重复,毫无技术含量!
那就写个框架做了它!显示我们的牛B!
6、框架确切需求
1)用户只需定义持久层接口(dao接口)、接口方法对应的SQL语句。
2)用户需指明接口方法的参数与SQL语句参数的对应关系。
3)用户需指明SQL查询结果集与对象属性的映射关系。
4)框架完成接口对象的生成,JDBC执行过程
二、设计
1、需求 1
1)用户只需定义持久层接口(dao接口)、接口方法对应的SQL语句。
设计问题:
1)我们该提供什么样的方式来让用户定义SQL语句?
2)SQL语句怎么与接口方法对应?
3)这些SQL语句、对应关系我们框架需要获取到,谁来获取?又该如何表示存储
1.1 SQL定义方式
XML方式:独立于代码,修改很方便(不需改代码)
注解方式:直接加在方法上,零xml配置
问题:SQL语句可做增、删、改、查操作,我们是否要对SQL做个区分?
答:要,因为jdbc中对应有不同的方法 executeQuery executeUpdate
xml方式定义SQL语句定义方式 :设计增删改查的元素:
<!ELEMENT insert(#PCDATA) > <!ELEMENT update(#PCDATA) > <!ELEMENT delete(#PCDATA) > <!ELEMENT select (#PCDATA) >
<insert>insert into t_user(id,name,sex,age) values(?,?,?,?)</insert>
注解方式定义SQL语句定义方式 :设计增删改查的注解:@Insert @Update @Delete @Select ,注解项定义SQL

@Documented @Retention(RUNTIME) @Target({ METHOD }) public @interface Insert { String value(); }
@Insert("insert into t_user(id,name,sex,age) values(?,?,?,?)")
public void addUser(User user);
1.2 SQL语句与接口方法对应
xml方式时,如何来映射SQL语句对应的接口方法?
为元素定义一个id,id的值为对应的类名.方法名,如何?
<insert id="com.study.leesmall.sample.UserDao.addUser"> insert into t_user(id,name,sex,age) values(?,?,?,?) </insert>
一个Dao接口中可能会定义很多个数据访问方法,id这么写很长,能不能便捷一点?
这是在做SQL与接口方法的映射,我们来加一个mapper元素,它可包含多个insert、update、delete、select元素,相当于分组,一个接口中定义的分到一组。
在mapper中定义一个属性namespace,指定里面元素的名称空间,namespace的值对应接口类名,里面元素的id对应方法名。
mybatis-mapper.dtd
<!ELEMENT mapper (insert* | update* | delete* | select*)+ >
<!ATTLIST mapper namespace CDATA #IMPLIED >
<!ELEMENT insert(#PCDATA) >
<!ELEMENT update(#PCDATA) >
<!ELEMENT delete(#PCDATA) >
<!ELEMENT select (#PCDATA) >
这个xml文件命名为 userDaoMapper.xml,内容如下:
<mapper namespace="com.study.leesmall.sample.userDao"> <insert id="addUser"> insert into t_user(id,name,sex,age) values(?,?,?,?) </insert> </mapper>
1.3 映射关系的获取与表示、存储
xml方式:
解析xml来获取
注解方式:
读取注解信息
问题:
1) 怎么表示?
得设计一个类来表示从xml、注解获得的SQL映射信息。
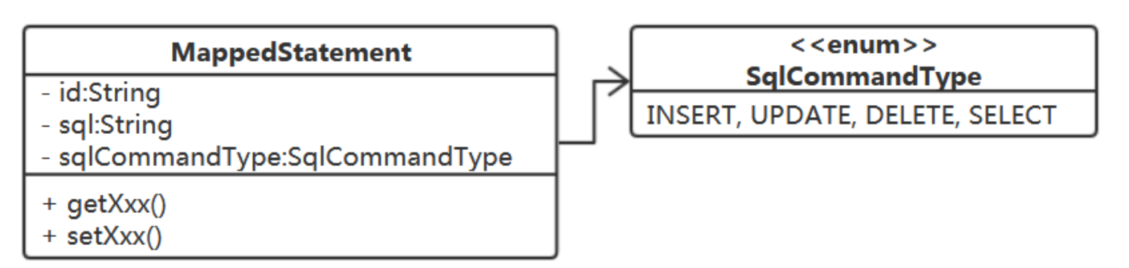
注意:
id为唯一id:
xml方式:id=namespace.id属性值
注解方式:id=完整类名.方法名
2) 怎么存储得到的MappedStatement?
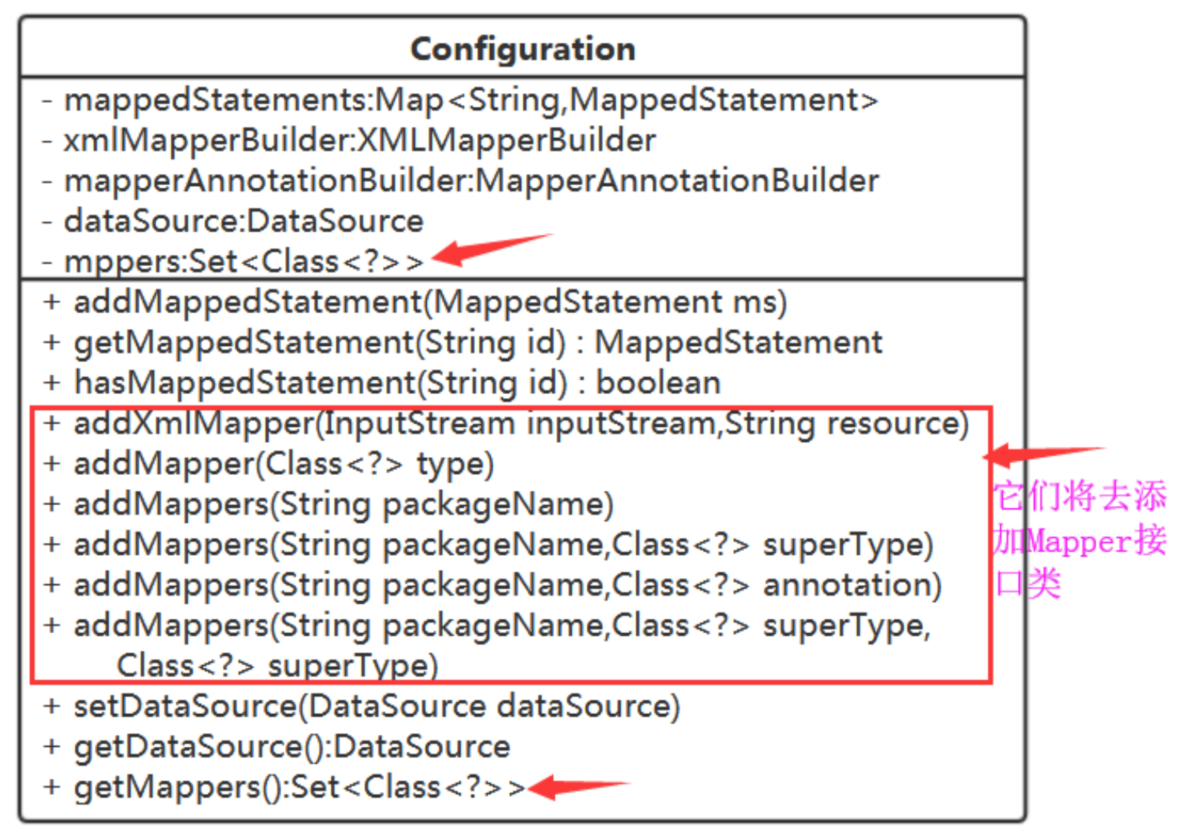
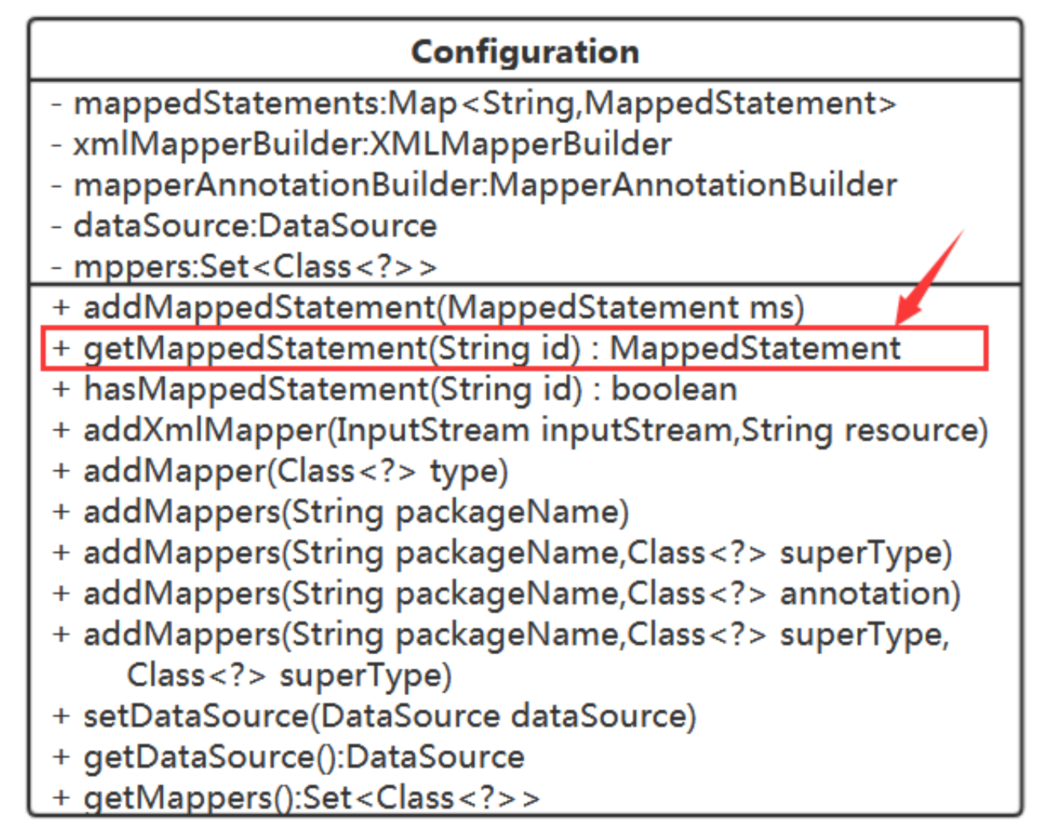
这些其实就是一个配置信息,我们定义一个Configuration类:

注意:key 为MappedStatement的id
3) 得有类来负责解析xml

XmlMapperBuilder负责解析xml文档(parse方法的resource参数用来指定inputStream的来源),parse方法它调用XMLStatementBuilder来解析里面的parse方法,解析完成以后,把获得的信息存储到Configuration里面
4)mapper中可以让用户如何来指定文件位置?
文件可以是在类目录下,也可是在文件系统目录下。如何区分?
规定:
类目录下的方式通过 resource属性指定;
文件系统文件通过 url属性指定,值采用URL 本地文件格式指定:file:///
<configuration> <mappers> <mapper resource="com/leesmall/UserMapper.xml"/> <mapper url="file:///var/mappers/CourseMapper.xml"/> <mappers> </configuration>
定义 mybatis-config.dtd
<!ELEMENT configuration (mappers?)+ > <!ELEMENT mappers (mapper*)> <!ELEMENT mapper EMPTY> <!ATTLIST mapper resource CDATA #IMPLIED url CDATA #IMPLIED >
5) 增加了一个config xml文件,就的有类来解析它。
增加解析mybatis-config.xml配置文件的类

6) 注解的方式需要获取SQL映射信息,也得有个类来做这件事

7) 谁来使用MapperAnnotationBuilder?
Configuration吧,在它里面持有MapperAnnotationBuilder,增加添加Mapper接口类的方法。

8) 用户如何来指定他们的Mapper接口类?
1、在mybatis-config.xml的mappers中通过mapper指定?
<configuration> <mappers> <mapper resource="com/leesmall/UserMapper.xml"/> <mapper url="file:///var/mappers/CourseMapper.xml"/> <mappers> </configuration>
如何来区分它是个Mapper接口呢?
给mapper加一个属性class来专门指定Mapper类名
<configuration> <mappers> <mapper resource="com/leesmall/UserMapper.xml"/> <mapper url="file:///var/mappers/CourseMapper.xml"/> <mapper class="com.study.leesmall.dao.UserDao" /> <mappers> </configuration>
mybatis-config.dtd
<!ELEMENT configuration (mappers?)+ > <!ELEMENT mappers (mapper*)> <!ELEMENT mapper EMPTY> <!ATTLIST mapper resource CDATA #IMPLIED url CDATA #IMPLIED class CDATA #IMPLIED >
问题:
1、这样一个一个类来指定,好繁琐?能不能指定一个包名,包含包下所有接口、子孙包下的接口类?
2、包含包下所有的接口,好像不是很灵活,能不能让用户指定包下所有某类型的接口?
如是什么类型的类,或带有某注解的接口。
好的,这很容易,在mappers元素中增加一个package元素,pacakge元素定义三个属性
mybatis-config.dtd
<!ELEMENT configuration (mappers?)+ > <!ELEMENT mappers (mapper*,package*)> <!ELEMENT mapper EMPTY> <!ATTLIST mapper resource CDATA #IMPLIED url CDATA #IMPLIED class CDATA #IMPLIED > <!ELEMENT package EMPTY> <!ATTLIST package name CDATA #IMPLIED type CDATA #IMPLIED annotation CDATA #IMPLIED >
<configuration> <mappers> <mapper resource="com/leesmall/UserMapper.xml"/> <mapper url="file:///var/mappers/CourseMapper.xml"/> <mapper class="com.study.leesmall.dao.UserDao" /> <package name="com.study.leesmall.mapper" /> <package name="com.study.leesmall.mapper" type="com.study.leesmall.MapperInterface"/> <package name="com.study.leesmall.mapper" annotation="com.study.leesmall.mybtis.annotation.Mapper"/> <package name="com.study.leesmall.mapper" type="com.study.leesmall.MapperInterface" annotation="com.study.leesmall.mybtis.annotation.Mapper"/> <mappers> </configuration>
为了用户使用方便,我们给定义一个@Mapper注解,默认规则:指定包下加了@Mapper注解的接口,如何?

加了package元素,又得在Configuration中增加对应的方法了:
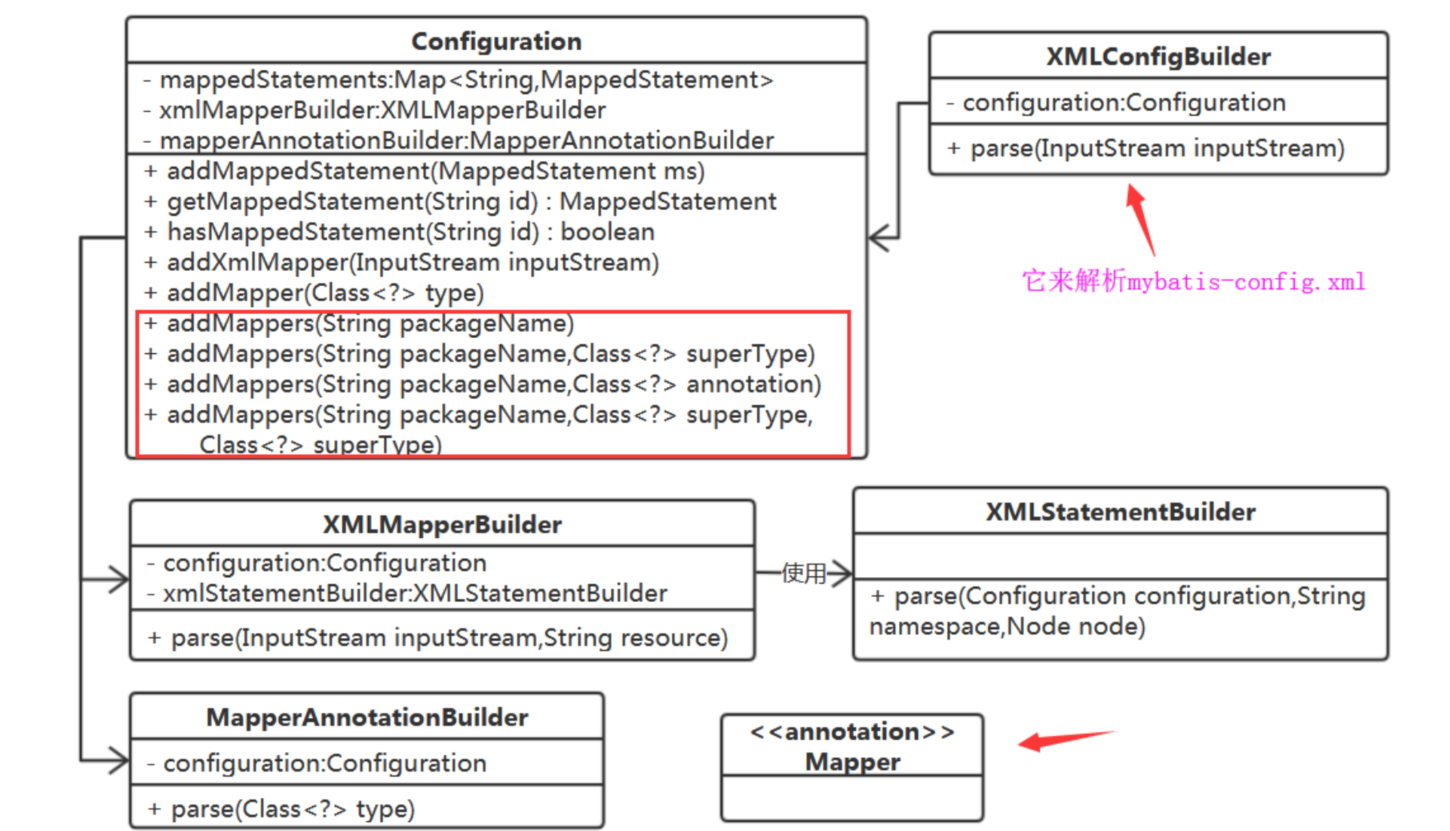
约定俗成的规则:指定包下扫到的@Mapper接口,例如UserDao,还可以在包下定义 UserDao.xml,会被加载解析。
2 需求2
需求2、用户需指明接口方法的参数与语句参数的对应关系。
2.1 语句参数指定
看下面的Mapper示例
@Mapper public interface UserDao { @Insert("insert into t_user(id,name,sex,age) values(?,?,?,?)") void addUser(User user); }
User对象的属性如何与 values(?)对应?
靠解析 t_user(id,name,sex,age) 可行吗?
难度太大!
万一User的name叫xname呢!
既然靠我们来解析不行,那就请用户指明吧。用户如何来指明呢?
我们来给定个规则: ? 用 #{属性名} 代替,我们来解析SQL语句中的 #{属性名} 来决定参数对应。
@Insert("insert into t_user(id,name,sex,age) values(#{id},#{name},#{sex},#{age})")
void addUser(User user);
万一是这种情况呢?
@Insert("insert into t_user(id,name,sex,age) values(#{id},#{name},#{sex},#{age})")
void addUser(String id,String xname,String sex,int age);
完全可以要求用户必须与参数名对应 :#{xname}。
为了提高点自由度(及后面方便SQL复用),可以定义一个注解让用户使用,该注解只可用在参数上

@Insert("insert into t_user(id,name,sex,age) values(#{id},#{name},#{sex},#{age})")
void addUser(String id,@Param("name")String xname,String sex,int age);
万一是这种情况呢?
@Insert("insert into t_user(id,name,sex,age,org_id) values(#{id},#{name},#{sex},#{age},#{id})")
void addUser(User user,Org org);
User和Org中都有id属性,name属性
好办,如果方法参数是对象,则以 参数名.属性 的方式指定SQL参数:
@Insert("insert into t_user(id,name,sex,age,org_id) values(#{user.id},#{user.name},#{user.sex},#{user.age},#{org.id})")
void addUser(User user,Org org);
一样也可以使用@Param
如果方法参数是这种情况呢?
@Insert("insert into t_user(id,name,sex,age) values(#{id},#{name},#{sex},#{age})")
void addUser(Map map);
对应Map中的key
如果方法参数是这种情况呢?
@Insert("insert into t_user(id,name,sex,age,org_id) values(#{user.id},#{user.name},#{user.sex},#{user.age},#{org.id})")
void addUser(Map map,Org org);
@Insert("insert into t_user(id,name,sex,age,org_id) values(#{user.id},#{user.name},#{user.sex},#{user.age},#{org.id})")
void addUser(@Param("user")Map map,Org org);
再来看下下面的场景:
@Select("select id,name,sex from t_user where sex = #{sex} order by #{orderColumn}")
List<User> query(String sex, String orderColumn);
order by #{orderColumn} order by ? 可以吗?
不可以,也就是说 方法参数不全是用来做SQL语句的预编译参数值的,有些是来构成SQL语句的一部分的。
那怎么让用户指定呢?
一样,定义个规则: ${属性名} 表示这里是字符串替换
@Select("select id,name,sex from t_user where sex = #{sex} order by ${orderColumn}")
List<User> query(String sex, String orderColumn);
2.2 SQL中参数映射解析
问题:
1) SQL中参数映射解析要完成的是什么工作?
解析出真正的SQL语句
获得方法参数与语句参数的对应关系 : 问号N---哪个参
public void addUser(User user) throws SQLException { try ( // 1、获取连接 Connection conn = DataSourceUtils.getConnection(dataSource); // 2、创建预编译语句对象 PreparedStatement pst = conn.prepareStatement( "insert into t_user(id,name,sex,age,address,phone,wechat,email,account,password) " + " values(?,?,?,?,?,?,?,?,?,?)");) { // 3、设置参数值 int i = 1; pst.setString(i++, user.getId()); pst.setString(i++, user.getName()); pst.setString(i++, user.getSex()); pst.setInt(i++, user.getAge()); pst.setString(i++, user.getAddress()); pst.setString(i++, user.getPhone()); pst.setString(i++, user.getWechat()); pst.setString(i++, user.getEmail()); pst.setString(i++, user.getAccount()); pst.setString(i++, user.getPassword()); // 4、执行语句 int changeRows = pst.executeUpdate(); } }
怎么解析?
@Insert("insert into t_user(id,name,sex,age,org_id) values(#{user.id},#{user.name},#{user.sex},#{user.age},#{org.id})")
void addUser(@Param("user")Map map,Org org);
方式有:
正则表达式
antlr
怎么表示?
问号的index、值来源
2) 这个解析的工作在何时做好?谁来做好?
设计怎么来执行一个Mapper接口了
SqlSession
SqlSessionFactory
3. 需求4
1)用户只需定义持久层接口(dao接口)、接口方法对应的SQL语句。
2)用户需指明接口方法的参数与语句参数的对应关系。
3)用户需指明查询结果集与对象属性的映射关系。
4)框架完成接口对象的生成,JDBC执行过程。
3.1 SQL语句有了,参数对应关系也有了,我们想想怎么执行SQL吧。
问题:
1、要执行SQL,我们得要有DataSource,谁来持有DataSource?

2、谁来执行SQL? Configuration ?
不合适,它是配置对象,持有所有配置信息!
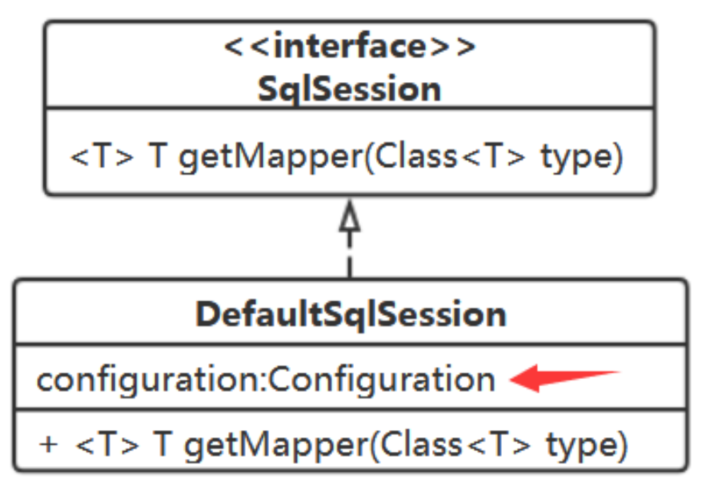
既然是来做事的,那就先定义一个接口吧:SqlSession

该为它定义什么方法呢?
需求4:框架完成接口对象的生成,JDBC执行过程。
用户给定Mapper接口类,要为它生成对象,用户再使用这个对象完成对应的数据库操作。

使用示例:
UserDao userDao = sqlSession.getMapper(UserDao.class); userDao.addUser(user);
来为它定义一个实现类:DefaultSqlSession
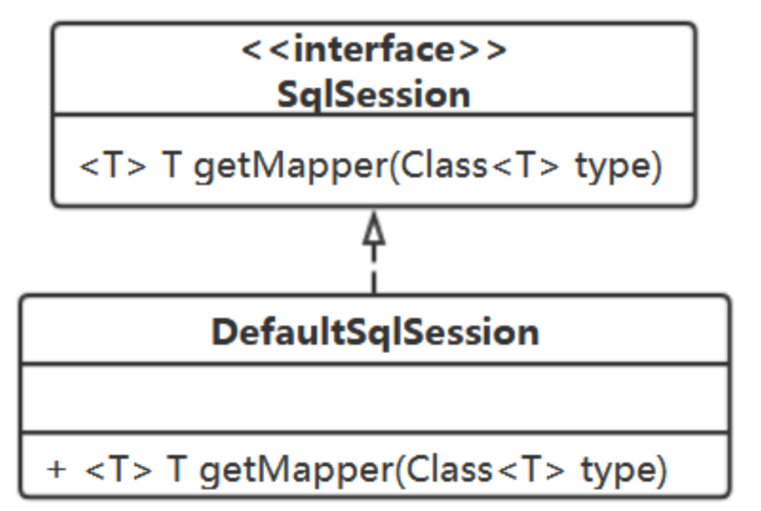
它该持有什么属性吗?
用户给入一个接口类,DefaultSqlSession中就为它生成一个对象?
万一给入的不是一个Mapper接口呢?
也为其生成一个对象就不合理了?
那怎么判断给入的接口类是否是一个Mapper接口呢?
那就只有在配置阶段扫描、解析Mapper接口时做个存储了。
存哪,用什么存?
这也是配置信息,还是存在Configuration 中,就用个Set来存吧。
DefaultSqlSession中需要持有Configuration
3.2 对象生成
1、如何为用户给入的Mapper接口生成对象?
很简单,JDK动态代理
Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, invocationHandler);
写一版DefaultSqlSession的实现:
package com.study.leesmall.mybatis.session; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Proxy; import com.study.leesmall.mybatis.config.Configuration; public class DefaultSqlSession implements SqlSession { private Configuration configuration; public DefaultSqlSession(Configuration configuration) { super(); this.configuration = configuration; } @Override public <T> T getMapper(Class<T> type) { //检查给入的接口 if (!this.configuration.getMappers().contains(type)) { throw new RuntimeException(type + " 不在Mapper接口列表中!"); } //得到 InvocationHandler InvocationHandler ih = null; // TODO 必须要有一个 // 创建代理对象 T t = (T)Proxy.newProxyInstance(type.getClassLoader(), new Class<?>[] {type}, ih); return t; } }
问题:每次调用getMapper(Class type)都需要生成一个新的实例吗?
代理对象中持有InvocationHandler,如果InvocationHandler能做到线程安全,就只需要一个实例。
还得看InvocationHandler,先放这吧,把InvocationHandler搞定先
3.3 执行SQL的InvocationHandler
了解 InvocationHandler
InvocationHandler 是在代理对象中完成增强。我们这里通过它来执行SQL。
public interface InvocationHandler { /** @param proxy 生成的代理对象 @param method 被调用的方法 @param args @return Object 方法执行的返回值 */ public Object invoke(Object proxy, Method method, Object[] args) throws Throwable; }
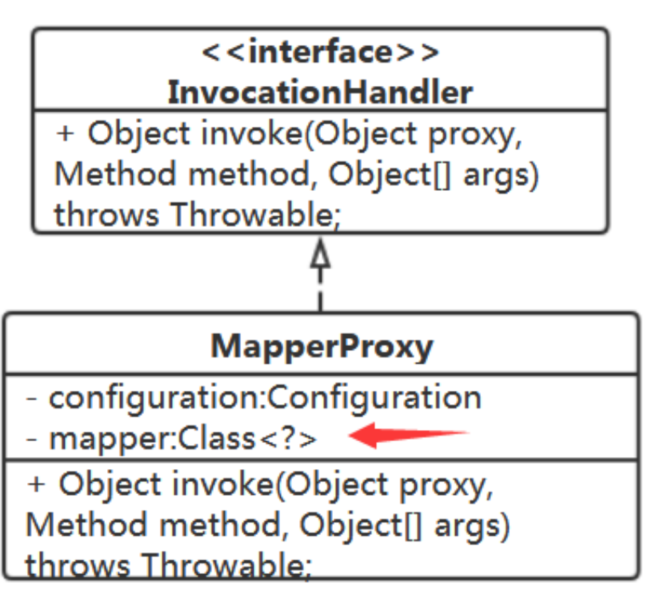
来实现我们的InvocationHandler: MapperProxy
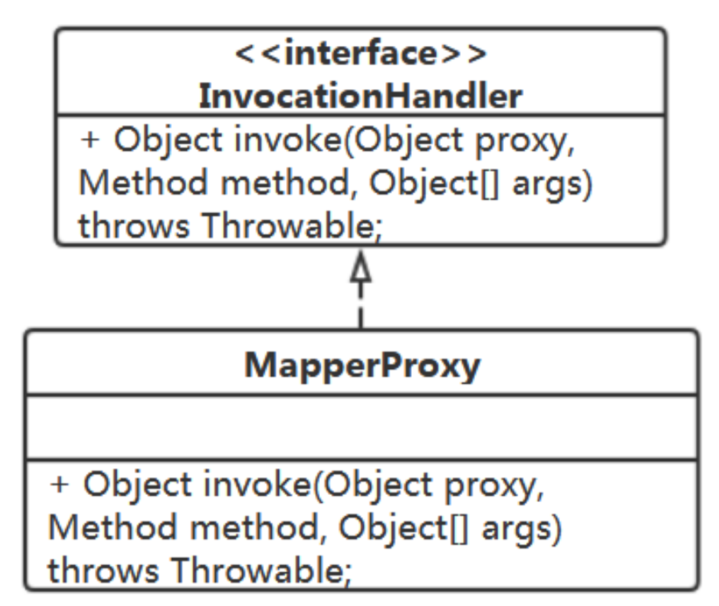
package com.study.leesmall.mybatis.session; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; public class MapperProxy implements InvocationHandler { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // TODO 这里需要完成哪些事? return null; } }
思考: 在 MapperProxy.invoke方法中需要完成哪些事?
package com.study.leesmall.mybatis.session; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; public class MapperProxy implements InvocationHandler { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // TODO 这里需要完成哪些事? // 1、获得方法对应的SQL语句 // 2、解析SQL参数与方法参数的对应关系,得到真正的SQL与语句参数值 // 3、获得数据库连接 // 4、执行语句 // 5、处理结果 return null; } }
1、获得方法对应的SQL语句
要获得SQL语句,需要用到Configuration,MapperProxy中需持有Configuration
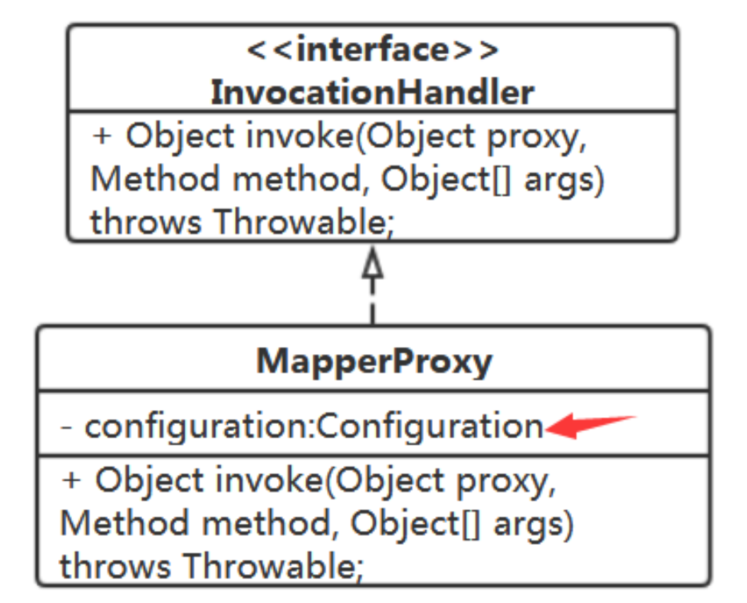
问题:id怎么得来?
id是类名.方法名。从invoke方法的参数中能得来吗?
public Object invoke(Object proxy, Method method, Object[] args)
method参数能得到方法名,但得到的类名不是Mapper接口类名。
那就直接让MapperProxy持有其增强的Mapper接口类吧!简单!
2、解析SQL参数与方法参数的对应关系,得到真正的SQL与语句参数值
逻辑:
1)查找SQL语句中的 #{属性} ,确定是第几个参数,再在方法参数中找到对应的值,存储下来,替换 #{属性} 为? 。
2)查找SQL语句中的 ${属性} ,确定是哪个参数,再在方法参数中找到对应的值,替换 ${属性} 。
3)返回最终的SQL与参数数组。
解析过程涉及的数据:SQL语句、方法的参数定义、方法的参数值
@Insert("insert into t_user(id,name,sex,age) values(#{id},#{name},# {sex},#{age})") void addUser(String id,@Param("name")String xname,String sex,int age);
Parameter[] params = method.getParameters();
public Object invoke(Object proxy, Method method, Object[] args)
说明: 这里是要确定SQL中的?N是哪个参数值。
这里要分三种情况: 方法参数是0参数,单个参数、多个参数。
0参数:不需要考虑参数了。
单个参数:SQL中的参数取值参数的属性或就是参数本身。
多个参数:则需要确定SQL中的参数值取第几个参数的值。
多个参数的情况,可以有两种做法:
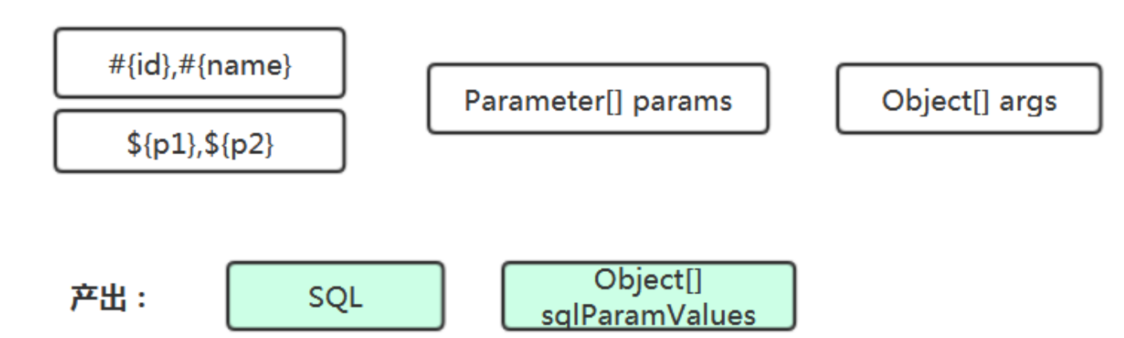
方式一: 查找#{属性},根据Parameter[]中的名称(注解名、序号)匹配确定是第几个参数,再到 Object[] args中取到对应的值。
方式二:先将Parameter[] 和 Object[] args转为Map,参数名(注解名、序号)为key,Object参数值为值;然后再查找SQL语句中的 #{}${},根据里面的名称到map中取对应的值。
哪种方式更好呢?
我们来看下两者查找过程的输出:

方式一相较于方式二,看起来复杂的地方是要遍历Parameter[] 来确定索引号。
思考一下:这种查找对应关系的事,需要每次调用方法时都做吗?方法的参数会有很多个吗?
这个对应关系可以在扫描解析Mapper接口时做一次即可。在调用Mapper代理对象的方法时,
就可以直接根据索引号去Object[] args中取参数值了。
方式2则每次调用Mapper代理对象的方法时,都需要创建转换Map。
而且方式一,单个参数与多个参数我们可以同样处理。
要在扫描解析Mapper接口时做参数解析我们就需要定义对应的存储结构,及修改MappedStatement了
?N--- 参数索引号 的对应关系如何表示?
?N 就是一个数值,而且是一个顺序数(只是jdbc中的?是从1开始)。我们完全可以用List来存储。
参数索引号,仅仅是个索引号吗?
@Insert("insert into t_user(id,name,sex,age,org_id) values(#{user.id},#
{user.name},#{user.sex},#{user.age},#{org.id})")
void addUser(User user,Org org);
它应该是索引号、和里面的属性两部分。
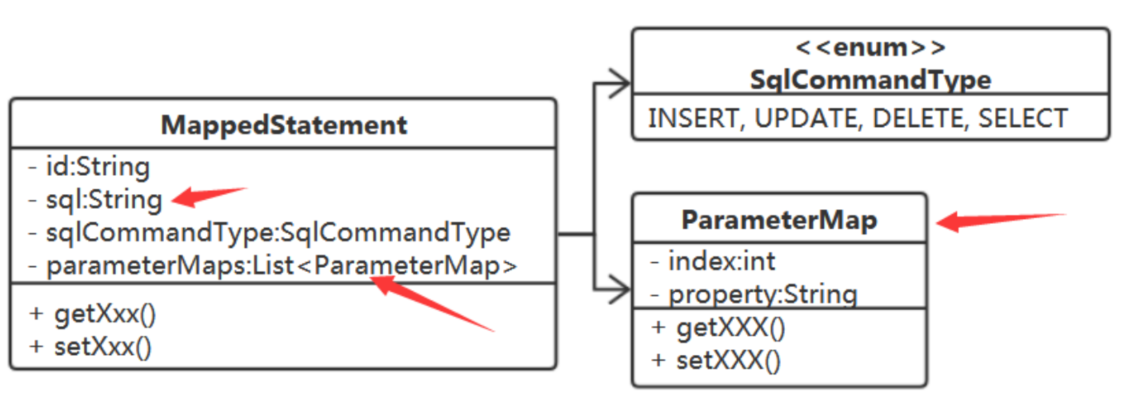
解析阶段由它们俩完成这件事:

我们在MappedStatement中再增加一个方法来完成根据参数映射关系得到真正参数值的方法:

把MapperProxy的invoke方法填填看:
@Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // TODO 这里需要完成哪些事? // 1、获得方法对应的SQL语句 String id = this.mapper.getName() + "." + method.getName(); MappedStatement ms = this.configuration.getMappedStatement(id); // 2、解析SQL参数与方法参数的对应关系,得到真正的SQL与语句参数值 RealSqlAndParamValues rsp = ms.getRealSqlAndParamValues(args); // 3、获得数据库连接 Connection conn = this.configuration.getDataSource().getConnection(); // 4、执行语句。 PreparedStatement pst = conn.prepareStatement(rsp.getSql()); // 疑问:语句一定是PreparedStatement? // 设置参数 if (rsp.getParamValues() != null) { int i = 1; for (Object p : rsp.getParamValues()) { pst.setxxx(i++, p); //这里写不下去了.......如何决定该调用pst的哪 个set方法? } } // 5、处理结果 return null; }
4 JavaType、JdbcType转换
1 认识它们
JavaType:java中的数据类型。
JdbcType:Jdbc规范中根据数据库sql数据类型定义的一套数据类型规范,各数据库厂商遵照这套规范来提供jdbc驱动中数据类型支持。
疑问:为什么我们在这里需要考虑它呢?
pst.setxxx(i++, p),我们不能根据p的类型选择set方法吗?
看pst的set方法中与对应的:

我们判断p的类型,然后选择不可吗? 像下面这样
int i = 1; for (Object p : rsp.getParamValues()) { if (p instanceof Byte) { pst.setByte(i++, (Byte) p); } else if (p instanceof Integer) { pst.setInt(i++, (int) p); } else if (p instanceof String) { pst.setString(i++, (String) p); } ... else if(...) }
我们来看一下这种情况:

看PreparedStatment的set方法:


上面前两种情况怎么处理?
这个需要用户说明其要使用的JDBCType,不然鬼知道他想要什么。
让用户怎么指定呢?
#{user.id,jdbcType=TIME}
javaType有需要指定不呢?
好像不需要,那就暂放下。
第3种情况怎么处理?
这是一个未知的问题,鬼知道将来使用我的框架的人会需要怎么处理他们的对象呢!
如何以不变应万变呢?
面向接口编程
定义一个什么样的接口呢?
该接口的用途是什么?
完成Object p 的pst.setXXX()。
2 TypeHandler
下面这个if-else-if的代码是否可以通过TypeHandler,换成策略模式?
int i = 1; for (Object p : rsp.getParamValues()) { if (p instanceof Byte) { pst.setByte(i++, (Byte) p); } else if (p instanceof Integer) { pst.setInt(i++, (int) p); } else if (p instanceof String) { pst.setString(i++, (String) p); } ... else if(...) }
定义一些常用数据类型的TypeHandler.
先不急着去定义,我们来考虑一下下面的问题。
这个怎么使用它呢?
在MapperProxy.invoke()中?
int i = 1; for (Object p : rsp.getParamValues()) { TypeHandler th = getTypeHandler(p.getClass);//还需要别的参数吗? th.setParameter(pst,i++,p); }
还需要JDBCType。
int i = 1; for (Object p : rsp.getParamValues()) { TypeHandler th = getTypeHandler(p.getClass,jdbcType);//jdbcType 从哪来? th.setParameter(pst,i++,p); }
问题:
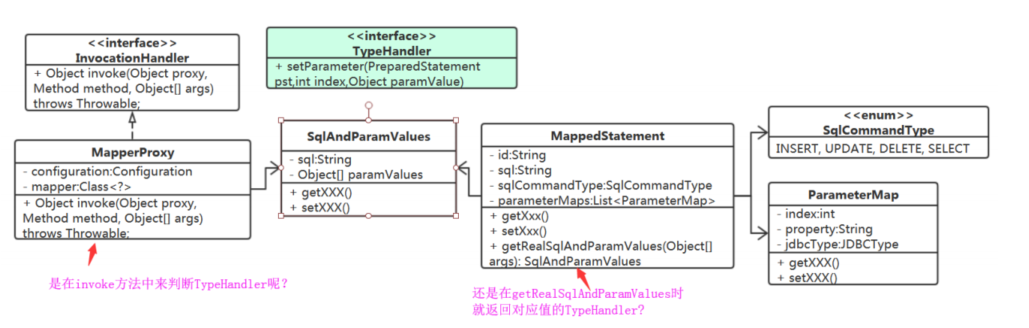
1、是在invoke方法中来判断TypeHandler呢?还是在MappedStatement的getRealSqlAndParamValues时就返回值对应的TypeHandler?
选择后者更合适!
那SqlAndParamValues中的参数值就不能是Object[]。它是值和TypeHandler两部分构成。
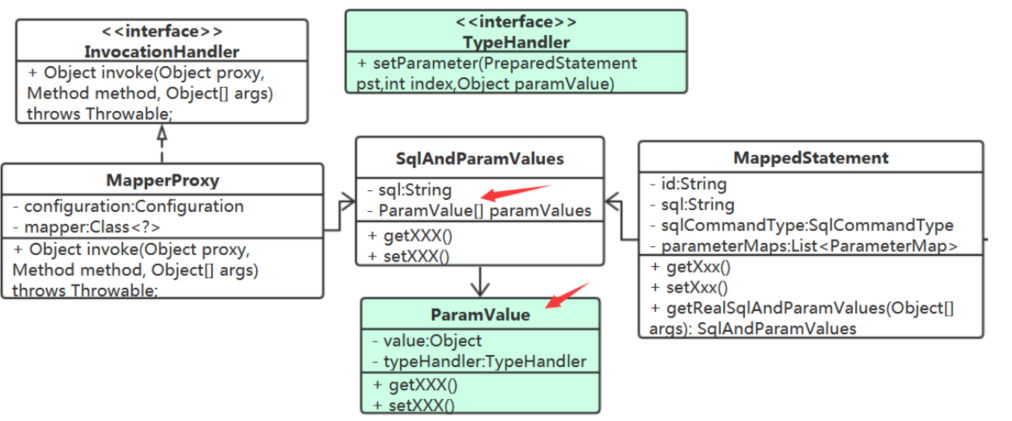
MapperProxy中的代码就变成下面这样了:
int i = 1; for (ParamValue p : rsp.getParamValues()) { TypeHandler th = p.getTypeHandler() th.setParameter(pst,i++,p.getValue()); }
2、MappedStatement又从哪里去获取TypeHandler呢?
我们会定义一些常用的,用户可能会提供一些。用户怎么提供?存储到哪里?
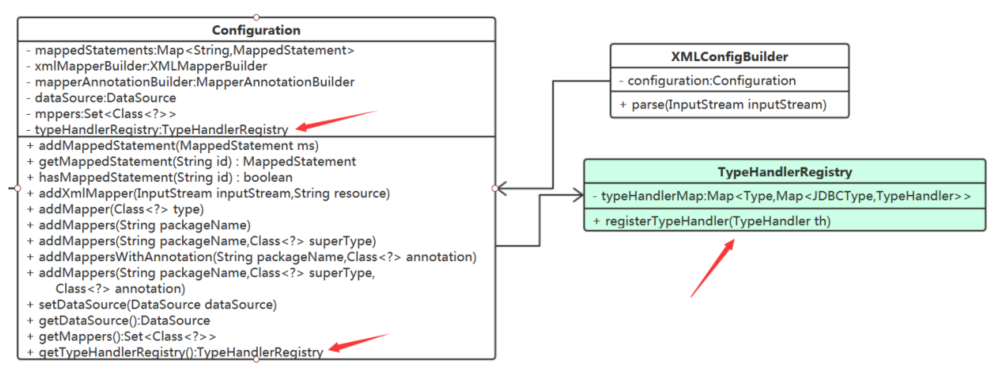
Configuration 吧,它最合适了。以什么结构来存储呢?
这里涉及到查找,需要根据 参数的javaType、jdbcTyp来查找。
那就定义一个map吧,如下这样如何?
Map<Type,Map<JDBCType,TypeHandler>> typeHandlerMap;
我们定义一个TypeHandlerRegistry类来持有所有的TypeHandler,Configuration 中则持有TypeHandlerRegistry
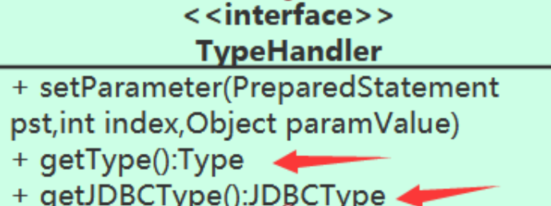
同时我们完善一下TypeHandler
3、用户如何来指定它们的TypeHandler?
在mybatis-config.xml中增加一个元素来让用户指定吧。
mybatis-config.dtd
<!ELEMENT configuration (mappers?, typeHandlers?)+ > <!ELEMENT mappers (mapper*,package*)> <!ELEMENT mapper EMPTY> <!ATTLIST mapper resource CDATA #IMPLIED url CDATA #IMPLIED class CDATA #IMPLIED > <!ELEMENT package EMPTY> <!ATTLIST package name CDATA #IMPLIED type CDATA #IMPLIED annotation CDATA #IMPLIED > <!ELEMENT typeHandlers (typeHandler*,package*)> <!ELEMENT typeHandler EMPTY> <!ATTLIST typeHandler class CDATA #REQUIRED >
既可以用typeHandler指定单个,也可用package指定扫描的包,扫描包下实现了TypeHandler接口的类
mybatis-config.xml
<configuration> <mappers> <mapper resource="com/leesmall/UserMapper.xml"/> <mapper url="file:///var/mappers/CourseMapper.xml"/> <mapper class="com.study.leesmall.dao.UserDao" /> <package name="com.study.leesmall.mapper" /> <mappers> <typeHandlers> <typeHandler class="com.study.leesmall.type.XoTypeHandler" /> <package name="com.study.leesmall.type" /> </typeHandlers> </configuration>
解析注册的工作就交给XMLConfigBuilder

4、MappedStatement中来决定TypeHandler,它就需要Configuration

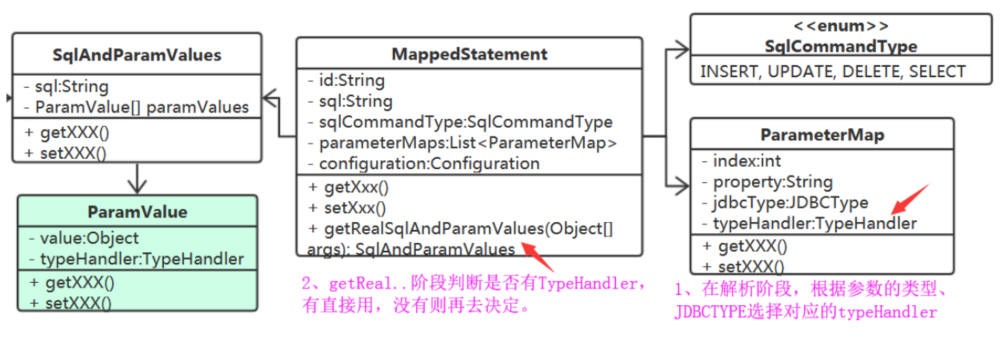
5、可不可以在解析语句参数关系时,就决定好TypeHandler?
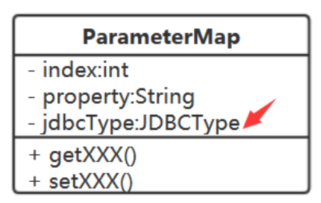
可以。我们在ParameterMap中增加typeHandler属性。
用户在SQL语句参数中必须要指定JDBCType吗?
常用的数据类型可以不指定,我们可以提供默认的TypeHandler。
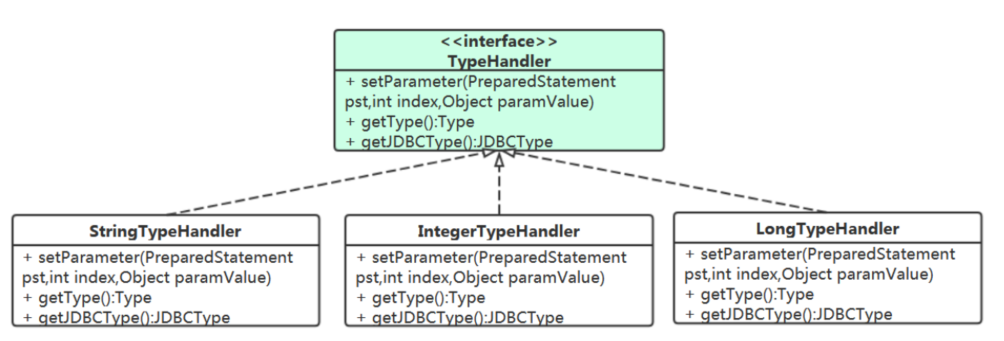
public class StringTypeHandler implements TypeHandler { @Override public Type getType() { return String.class; } @Override public JDBCType getJDBCType() { return JDBCType.VARCHAR; } @Override public void setParameter(PreparedStatement pst, int index, Object paramValue) throws SQLException { pst.setString(index, (String) paramValue); } }
用户在SQL中参数定义没有指定JDBCType,则我们可以直接使用我们默认的TypeHandler
如 #{user.name}
我们判断它的参数类型为String,就可以指定它的TypeHandler为 StringTypeHandler。可能它的数据库类型不为VACHAR,而是一个CHAR定长字符,没关系!因为pst.setString对VARCHAR、CHAR是通用的。
5 执行结果处理
5.1 执行结果处理要干的是什么事
pst.executeUpate()的返回结果是int,影响的行数。
pst.executeQuery()的返回结果是ResultSet。
在得到SQL语句执行的结果后,要转为方法的返回结果进行返回。这就是执行结果处理要干的事
根据方法的返回值类型来进行相应的处理。
这里我们根据SQL语句执行结果的不同,分开处理:
@Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // TODO 这里需要完成哪些事? // 1、获得方法对应的SQL语句 String id = this.mapper.getName() + "." + method.getName(); MappedStatement ms = this.configuration.getMappedStatement(id); // 2、解析SQL参数与方法参数的对应关系,得到真正的SQL与语句参数值 RealSqlAndParamValues rsp = ms.getRealSqlAndParamValues(args); // 3、获得数据库连接 Connection conn = this.configuration.getDataSource().getConnection(); // 4、创建语句对象。 PreparedStatement pst = conn.prepareStatement(rsp.getSql()); // 5、设置语句参数 int i = 1; for (ParamValue p : rsp.getParamValues()) { TypeHandler th = p.getTypeHandler() th.setParameter(pst,i++,p.getValue()); } // 6、执行语句并处理结果 switch (ms.getSqlCommandType()) { case INSERT: case UPDATE: case DELETE: int rows = pst.executeUpdate(); return handleUpdateReturn(rows, ms, method); case SELECT: ResultSet rs = pst.executeQuery(); return handleResultSetReturn(rs, ms, method); } } private Object handleUpdateReturn(int rows, MappedStatement ms, Method method) { // TODO Auto-generated method stub return null; } private Object handleResultSetReturn(ResultSet rs, MappedStatement ms, Method method) { // TODO Auto-generated method stub return null; }
5.2 pst.executeUpate()的返回结果处理
pst.executeUpate()的返回结果是int
方法的返回值可以是什么?
void、int、long 、 其他的不可以!
private Object handleUpdateReturn(int rows, MappedStatement ms, Method method) { Class<?> returnType = method.getReturnType(); if (returnType == Void.TYPE) { return null; } else if (returnType == int.class || returnType == Integer.class) { return rows; } else if (returnType == long.class || returnType == Long.class) { return (long) rows; } throw new IllegalArgumentException("update类方法的返回值只能是:void/int/Integer/long/Long"); }
5.3 pst.executeQuery()的返回结果处理
pst.executeQuery()的返回结果是ResultSet
方法的返回值可以是什么?
可以是void、单个值、集合。
单个值可以是什么类型的值?
任意值、(map)
@Select("select count(1) from t_user where sex = #{sex}")
int query(String sex);
@Select("select id,name,sex,age,address from t_user where id = #{id}")
User queryUser(String id);
@Select("select id,name,sex,age,address from t_user where id = #{id}")
Map queryUser1(String id);
集合可以是什么类型?
List、Set、数组、Vector
@Select("select id,name,sex,age,address from t_user where sex = #{sex}
order by #{orderColumn}")
List<User> query(String sex, String orderColumn);
@Select("select id,name,sex,age,address from t_user where sex = #{sex}
order by #{orderColumn}")
List<Map> query1(String sex, String orderColumn);
集合的元素可以是什么类型的?
任意类型的,集合只是单个值多做几遍。
结果集中的列如何与结果、结果的属性对应?
根据结果集列名与属性名对应
如果属性名与列名不一样呢?
则需用户显式说明映射规则。
需要考虑JDBCType --- JavaType的处理吗?
无论结果是什么类型的,在这里我们都是要完成一件事:从查询结果中获得数据返回,只是返回类型不同,有不同的获取数据的方式。
请思考:如何让下面这个方法的代码的写好后不再改变?
private Object handleResultSetReturn(ResultSet rs, MappedStatement ms, Object[] args) { // TODO Auto-generated method stub return null; }
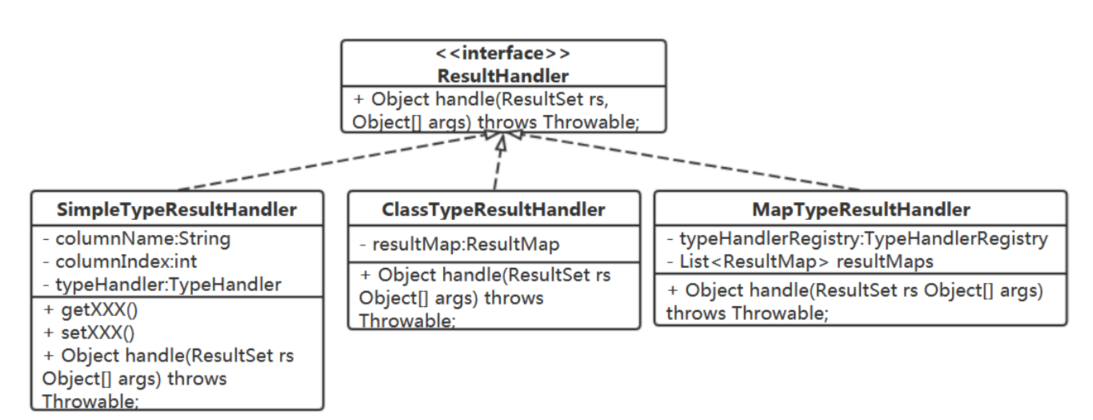
我需要在此做个抽象,应用策略模式,不同的处理实现这个抽象接口。

那么在handleResultSetReturn()方法中我们从哪得到ResultHandler呢?
从MappedStatement 中获取,每个语句对象(查询类型的)中都持有它对应的结果处理器。
在解析准备MappedStatement对象时根据方法的返回值类型选定对应的ResultHandler。
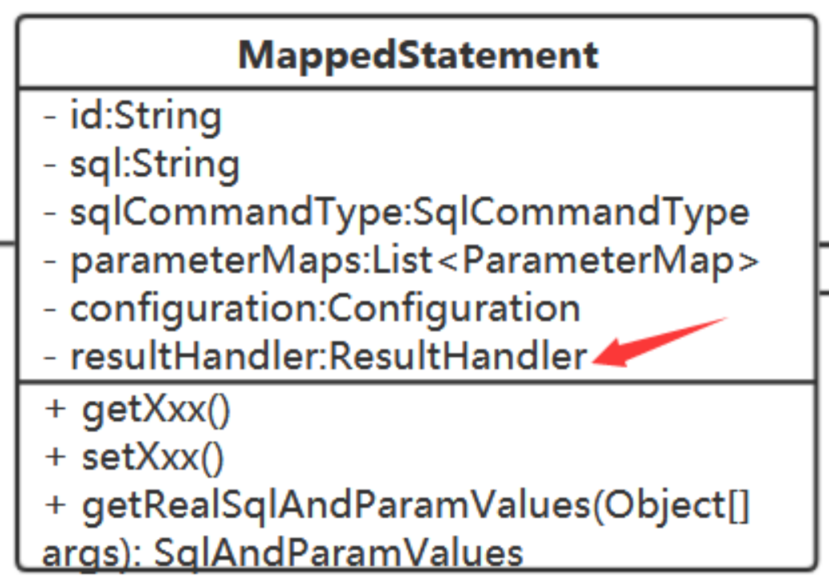
在handleResultSetReturn方法中只需调用ms中的ResultHandler:
private Object handleResultSetReturn(ResultSet rs, MappedStatement ms, Object[] args) throws Throwable { return ms.getResultHandler().handle(rs, args); }
5.3.1 方法返回单个值
@Select("select count(1) from t_user where sex = #{sex}")
int query(String sex);
@Select("select id,name,sex,age,address from t_user where id = #{id}")
User queryUser(String id);
@Select("select id,name,sex,age,address from t_user where id = #{id}")
Map queryUser1(String id);
1、基本数据类型、String 如何处理?
针对这种情况,提供对应的ResultHandler实现:
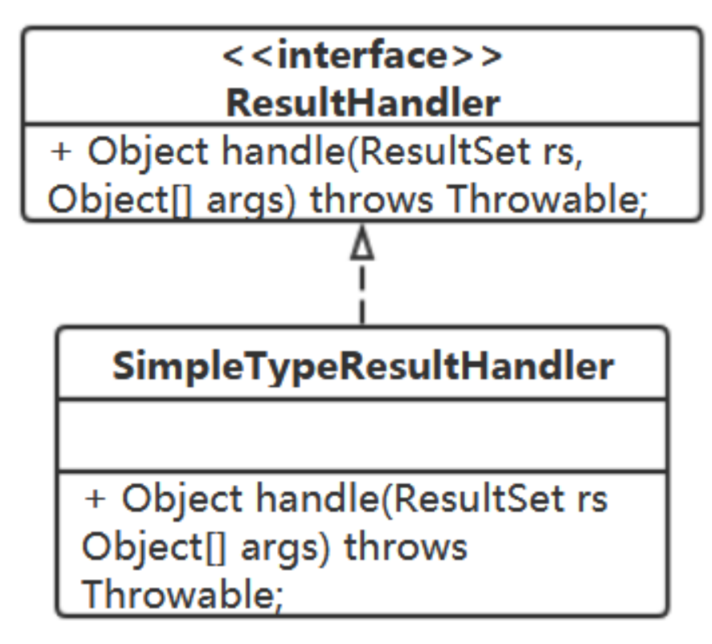
SimpleTypeResultHandler中需要定义什么属性?
handle方法中的逻辑该是怎样的?
public Object handle(ResultSet rs, Object[] args) throws Throwable { //从rs中取对应值 return rs.getXXX(OOO); }
问题1:该调用rs的哪个get方法?
得根据返回值来,返回值类型从哪来?
从SimpleTypeResultHandler中取,在创建MappedStatement时,根据反射获得的返回值类型给入到SimpleTypeResultHandler中。

SimpleTypeResultHandler的handle方法中的代码逻辑如下:
private Object handle(ResultSet rs, Object[] args) throws Throwable { Class<?> returnType = method.getReturnType(); if (returnType == short.class || returnType == Short.class) { return rs.getShort(xxx); } else if (returnType == int.class || returnType == Integer.class) { return rs.getInt(xxx); } else if (returnType == long.class || returnType == Long.class) { return rs.getLong(xxx); } ... return null;
问题2:该取结果集中的哪一列?
如果结果集中只有一列:那就取第1列。
如果结果集中是有多列呢?
问题:结果集中应不应该有多列?
两种方案:
1、该返回值情况下不允许结果集多列。
2、不限制,用户指定列名。
问题3:这么多if else 合适吗?
不合适,咋办?策略模式
该定义怎样的策略?
这是要做什么事情?
从结果集中获取值,跟pst.setXXX一样。
可不可以在TypeHandler中加方法?

public interface TypeHandler<T> { Type getType(); JDBCType getJDBCType(); void setParameter(PreparedStatement pst, int index, Object paramValue) throws SQLException; T getResult(ResultSet rs, String columnName) throws SQLException; T getResult(ResultSet rs, int columnIndex) throws SQLException; }
public class StringTypeHandler implements TypeHandler<String> { @Override public Type getType() { return String.class; } @Override public JDBCType getJDBCType() { return JDBCType.VARCHAR; } @Override public void setParameter(PreparedStatement pst, int index, Object paramValue) throws SQLException { pst.setString(index, (String) paramValue); } @Override public String getResult(ResultSet rs, String columnName) throws SQLException { return rs.getString(columnName); } @Override public String getResult(ResultSet rs, int columnIndex) throws SQLException { return rs.getString(columnIndex); } }
一样的,在启动解析阶段完成结果的TypeHandler选定。

根据返回值类型,从TypeHandlerRegistry中取,要取,还得有JDBCType,用户可以指定,也可不指定,不指定则使用默认的该类型的TypeHandler。
默认TypeHandler如何注册,修改registerTypeHandler方法的定义:
registerTypeHandler(TypeHandler th,boolean defalut){ Map<JDBCType,TypeHandler> cmap = typeHandlerMap.get(th.getType); if(cmap == null) { cmap = new HashMap<JDBCType,TypeHandler>(); typeHandlerMap.put(th.getType,cmap); } camp.put(th.getJDBCType(),th); if(default) { cmap.put(DefaultJDBCType.class/null,th); } }
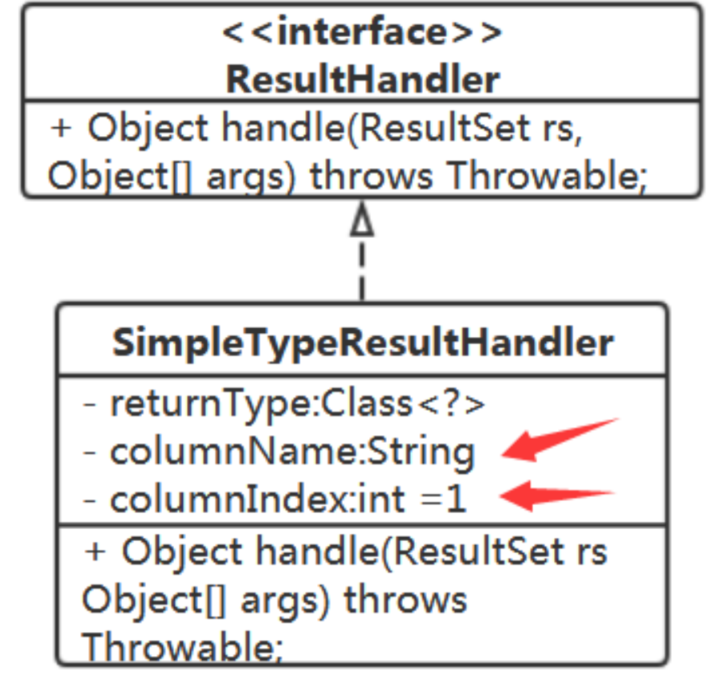
很好,那就可以在SimpleTypeResultHandler中持有对应的TypeHandler。
问:在SimpleTypeResultHandler中还有必要持有Class<?> returnType吗?
不需要,在TypeHandler中有了。

SimpleTypeResultHandler 的handle方法代码就简单了:
public Object handle(ResultSet rs, Object[] args) throws Throwable { if (StringUtils.isNotEmpty(columnName)) { return typeHandler.getResult(rs, columnName); } else { return typeHandler.getResult(rs, columnIndex); } }
2 对象类型返回结果的处理
@Select("select id,name,sex,age,address from t_user where id = #{id}")
User queryUser(String id);
分析:
1、要完成的事情是什么?
创建对象
从结果集中取数据给到对象
问题:
1、如何创建对象?
反射调用构造方法。
构造方法有多种情况:
1 未显式定义构造方法
public class User { private String id; private String name; private String sex; ... public String getId() { return id; } public void setId(String id) { this.id = id; } ... }
这种情况不需要考虑什么,直接创建对象!
2 显式定义了一个构造方法
public class User { private String id; private String name; private String sex; ... public User(String id, String name, String sex) { super(); this.id = id; this.name = name; this.sex = sex; } public String getId() { return id; } public void setId(String id) { this.id = id; } ... }
此种情况下,要创建对象,则需要对应的构造参数值。
问题1:构造参数值从哪来?
ResultSet
问题2:怎么知道该从ResultSet中取哪个列的值,取什么类型的值?
得定义构造参数与ResultSet中列的对应规则,下面的规则是否可以?
1、优先采用指定列名的方式:用参数名称当列名、或用户为参数指定列名(参数名与列名不
一致时、取不到参数名时);
2、如不能取得参数名,则按参数顺序来取对应顺序的列。
问题3:用户如何来指定列名?
注解、xml配置
public User(@Arg(column="id")String id, @Arg(column="xname")String name, @Arg(column="sex")String sex) { super(); this.id = id; this.name = name; this.sex = sex; }
@Documented @Retention(RUNTIME) @Target(PARAMETER) public @interface Arg { String name() default "";
String column() default "";
Class<?> javaType() default void.class;
JdbcType jdbcType() default JdbcType.UNDEFINED;
Class<? extends TypeHandler> typeHandler() default UndefinedTypeHandler.class; }
<resultMap id="User" type="com.study.leesmall.mybatis.sample.model.User"> <constructor> <arg name="" column="" JdbcType="" javaType="" typeHandler=""/> </constructor> </resultMap>
mybatis-mapper.dtd 中增加如下定义
<!ELEMENT resultMap (constructor?)> <!ATTLIST resultMap id CDATA #REQUIRED type CDATA #REQUIRED > <!ELEMENT constructor (arg*)> <!ELEMENT arg EMPTY> <!ATTLIST arg javaType CDATA #IMPLIED column CDATA #IMPLIED jdbcType CDATA #IMPLIED typeHandler CDATA #IMPLIED name CDATA #IMPLIED >
问题4:这些映射信息得到后如何表示、存储?
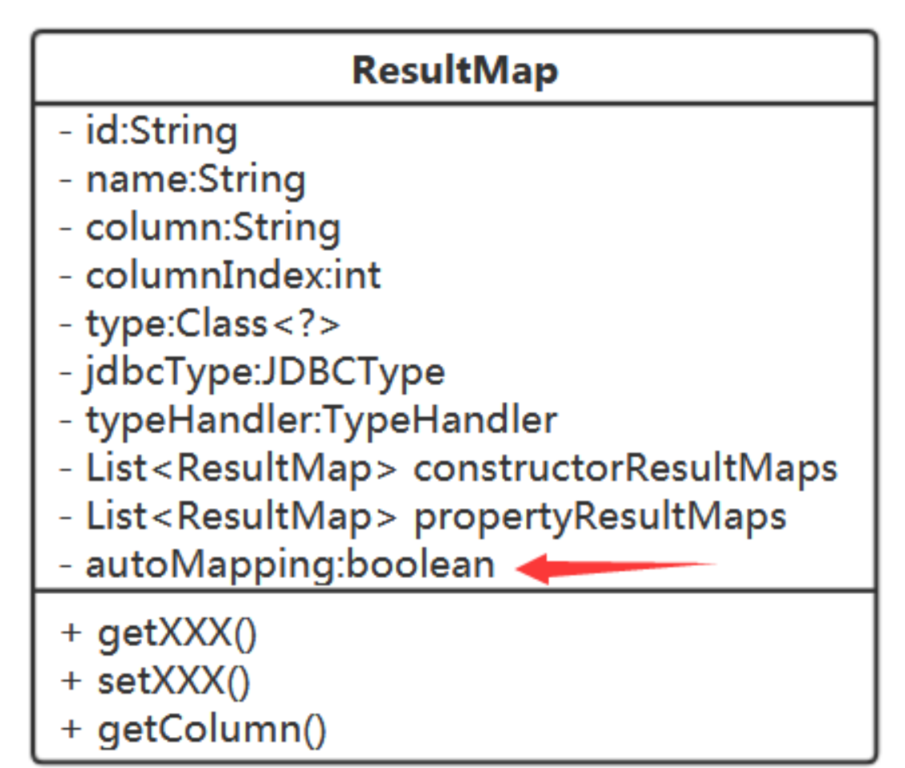
定义一个结果映射实体:ResultMap

注意,在创建ResultMap时,当用户没有指定TypeHandler或是UndefinedTypeHandler时,要根据type、jdbcType取对应的typeHandler,没有则为null;
问题5、ResultMap 元素怎么表示?
ResultMap类定义本身就是表示一种java类型与JDBCType类型的映射,基本数据类型与复合类型(类)都是java类型。
扩充一下ResultMap即可:

注意:这里有个使用规则需要注意一下:
如果ResultMap中有TypeHandler,则该结果直接通过调用TypeHandler来获得。没有TypeHandler时则看有constructorResultMaps没,有则根据此取结果集中的值来调用对应的构造方法创建对象。
3 定义了多个构造方法,怎么办?
public class User { private String id; private String name; private String sex; ... public User(String id, String name, String sex) { super(); this.id = id; this.name = name; this.sex = sex; } public User(String id, String name, String sex, int age) { super(); this.id = id; this.name = name; this.sex = sex; this.age = age; } public String getId() { return id; } public void setId(String id) { this.id = id; } ... }
用户指定构造方法,没有指定时则用默认构造方法(没有则报错)。
用户怎么指定:
注解 :
@MapConstructor public User(@Arg("id")String id, @Arg("xname")String name, @Arg("sex")String sex) { super(); this.id = id; this.name = name; this.sex = sex; }
/** * 标识选用的构造方法 */ @Documented @Retention(RUNTIME) @Target(CONSTRUCTOR) public @interface MapConstructor { }
xml:根据constructor元素中 arg元素的数量、javaType来确定构造函数。注意arg有顺序规则、必须指定构造方法的全部参数。
<resultMap id="User" type="com.study.leesmall.mybatis.sample.model.User"> <constructor> <arg column="id" javaType="String"/> <arg column="name" javaType="String"/> <arg column="sex" javaType="String"/> </constructor> </resultMap>
2、该给对象哪些属性值?
创建出对象后,可以从结果集中取值来填充对象的属性。
问题1:该给哪些属性赋值?
可以有两种规则:
1、用户指定要给哪些属性赋值。
2、自动映射赋值:取列的值赋给同名的属性。
两者可以一起使用。
那么这里就涉及两个事情:
1、用户如何指定?
注解方式: 我们给定义一个注解 @Result
public class User { @Result private String id; @Result(column="xname") private String name; ... }
@Documented @Retention(RUNTIME) @Target({ TYPE, FIELD }) public @interface Result { String column() default ""; Class<?> javaType() default void.class; JdbcType jdbcType() default JdbcType.UNDEFINED; Class<? extends TypeHandler> typeHandler() default UndefinedTypeHandler.class; }
xml方式:
<resultMap id="User" type="com.study.leesmall.mybatis.sample.model.User"> <constructor> <arg column="id" javaType="String"/> <arg column="name" javaType="String"/> <arg column="sex" javaType="String"/> </constructor> <result property="age" column="age" /> </resultMap>
mybatis-mapper.dtd
<!ELEMENT resultMap (constructor?,result*)> <!ATTLIST resultMap id CDATA #REQUIRED type CDATA #REQUIRED > <!ELEMENT constructor (arg*)> <!ELEMENT arg EMPTY> <!ATTLIST arg javaType CDATA #IMPLIED column CDATA #IMPLIED jdbcType CDATA #IMPLIED typeHandler CDATA #IMPLIED name CDATA #IMPLIED > <!ELEMENT result EMPTY> <!ATTLIST result property CDATA #IMPLIED javaType CDATA #IMPLIED column CDATA #IMPLIED jdbcType CDATA #IMPLIED typeHandler CDATA #IMPLIED >
问题:这些信息如何表示、存储?

2、是否自动映射如何指定?
增加一个属性即可:
autoMapping="true"
<resultMap id="User" type="com.study.leesmall.mybatis.sample.model.User" autoMapping="true"> <result property="age" column="age" /> </resultMap>
<!ELEMENT resultMap (constructor?,result*)> <!ATTLIST resultMap id CDATA #REQUIRED type CDATA #REQUIRED autoMapping (true|false) #IMPLIED >
注解方式:
/** 标识类对象要进行自动映射 */ @Documented @Retention(RUNTIME) @Target({ TYPE, FIELD }) public @interface AutoMapping { }
@AutoMapping public class User { @Result private String id; @Result(column="xname") private String name; ... }
为方便统一开启自动映射,我们可以在Configuration中设计一个全局配置参数,具体的可以覆盖全局的。

在哪可配置它?
在mybatis-config.xml中增加一个配置项即可。
<configuration> <settings> <setting name="autoMappingBehavior" value="PARTIAL"/> </settings> </configuration>
3、对象中包含对象该如何映射及处理
对象中包对象是个问题,先把问题搞清楚,看下面的语句示例:
<!-- Very Complex Statement --> <select id="selectBlogDetails" resultMap="detailedBlogResultMap"> select B.id as blog_id, B.title as blog_title, B.author_id as blog_author_id, A.id as author_id, A.username as author_username, A.password as author_password, A.email as author_email, A.bio as author_bio, A.favourite_section as author_favourite_section, P.id as post_id, P.blog_id as post_blog_id, P.author_id as post_author_id, P.created_on as post_created_on, P.section as post_section, P.subject as post_subject, P.draft as draft, P.body as post_body from Blog B left outer join Author A on B.author_id = A.id left outer join Post P on B.id = P.blog_id where B.id = #{id} </select>
再看类
public class Blog { private String id; private String title; private Author author; private List<Post> posts; .... } public class Author { private String id; private String username; ... } public class Post { private String id; private String subject; ... }
这就是对象中包含对象,要从查询结果中得到Blog,Blog的Author posts数据。
这就是ORM中的关系映射问题。
结果的映射是简单的,因为就是指定里面的属性取哪个列的值。
public class Blog { @Result(column="blog_id") private String id; @Result(column="blog_title") private String title; @Result private Author author; @Result private List<Post> posts; .... } public class Author { @Result(column="author_id") private String id; @Result(column="author_username") private String username; ... } public class Post { @Result(column="post_id") private String id; @Result(column="post_subject") private String subject; ... }
我们的ResultMap类也是支持的:
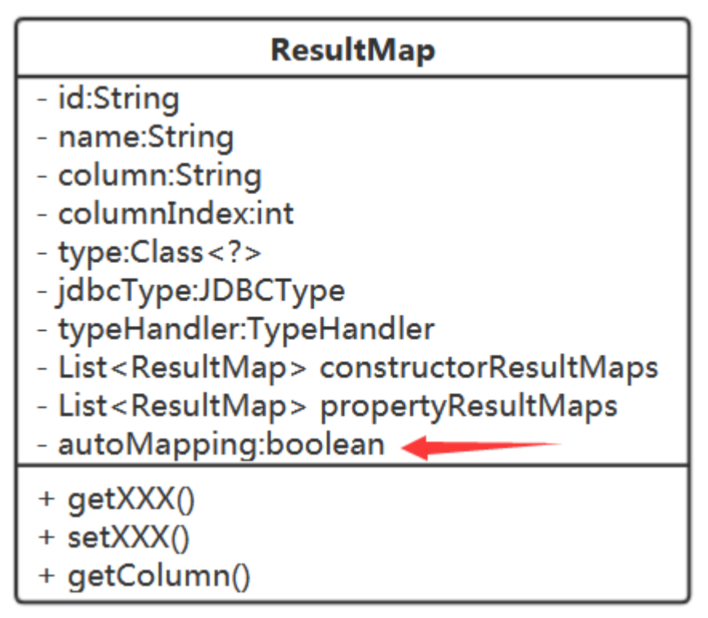
但是从结果集中取值来填装对象则是复杂的!
请先看查询的结果示例:
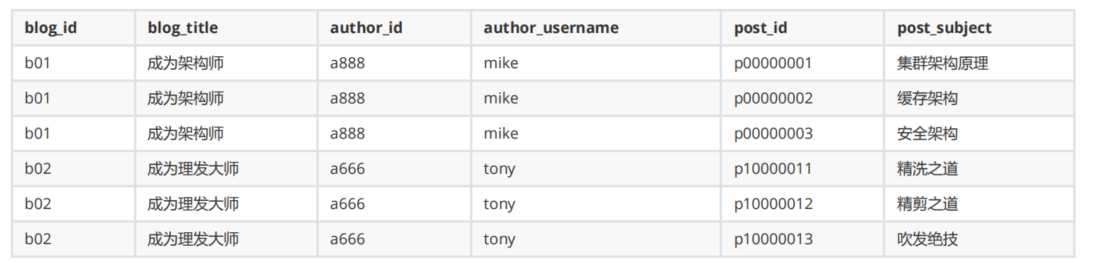
while(rs.next()){ }
复杂点:不是一行一个Blog对象,处理行时要判断该行的blog是否已取过了。
问题核心点在哪?
当我操作一行,如何判断该行的Blog已经取过没?
这就要求要知道区分Blog的唯一标识、区分Author的唯一标识。怎么知道?
用户得告诉我们他们的id属性是哪个,对应的列是哪个。
让用户怎么来指定id属性呢?
注解方式:在@Arg 、@Rersult注解中增加id指定项。
@Documented @Retention(RUNTIME) @Target(PARAMETER) public @interface Arg { boolean id() default false; String name() default ""; String column() default ""; Class<?> javaType() default void.class; JdbcType jdbcType() default JdbcType.UNDEFINED; Class<? extends TypeHandler> typeHandler() default UndefinedTypeHandler.class; }
@Documented @Retention(RUNTIME) @Target({ TYPE, FIELD }) public @interface Result { boolean id() default false; String column() default ""; Class<?> javaType() default void.class; JdbcType jdbcType() default JdbcType.UNDEFINED; Class<? extends TypeHandler> typeHandler() default UndefinedTypeHandler.class; }
xml方式增加:增加argId、id元素
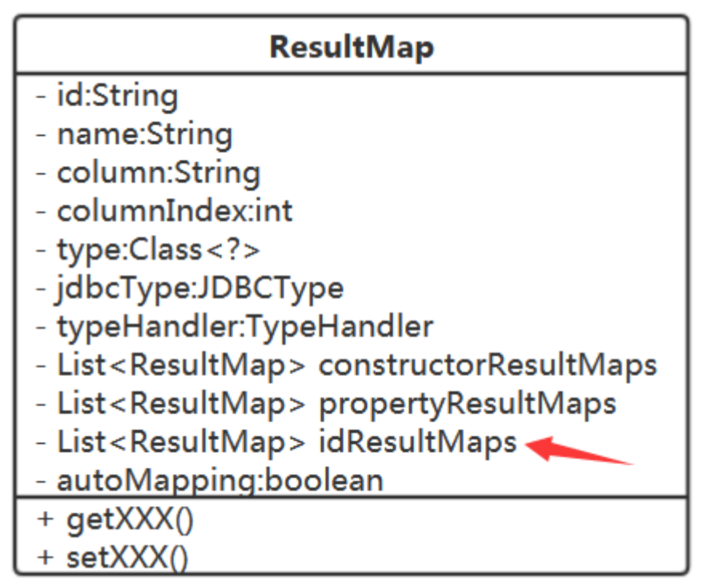
<resultMap id="detailedBlogResultMap" type="Blog"> <constructor> <idArg column="blog_id" javaType="int"/> </constructor> .... </resultMap> <resultMap id="AuthorMap" type="Author"> <id property="id" column="author_id"/> <result property="username" column="author_username"/> <result property="password" column="author_password"/> </resultMap>
在ResultMap中增加ID信息
问题:要体现出一对一,一对多关系吗?我们会在哪里需要知道这个关系?
看一个mybatis中的复杂xml ResultMap示例:
<!-- 超复杂的 Result Map --> <resultMap id="detailedBlogResultMap" type="Blog"> <constructor> <idArg column="blog_id" javaType="int"/> </constructor> <result property="title" column="blog_title"/> <association property="author" javaType="Author"> <id property="id" column="author_id"/> <result property="username" column="author_username"/> <result property="password" column="author_password"/> <result property="email" column="author_email"/> <result property="bio" column="author_bio"/> <result property="favouriteSection" column="author_favourite_section"/> </association> <collection property="posts" ofType="Post"> <id property="id" column="post_id"/> <result property="subject" column="post_subject"/> <association property="author" javaType="Author"/> <collection property="comments" ofType="Comment"> <id property="id" column="comment_id"/> </collection> </collection> </resultMap>
知道唯一标识了,要判断前面是否取过了,则还需要有个上下文持有取到的对象,并能根据id列值取到对应的对象。
为对象类型返回结果定义一个ResultHandler实现ClassTypeResultHandler:

3 Map
@Select("select id,name,sex,age,address from t_user where id = #{id}")
Map queryUser1(String id);
不能在解析阶段获得ResultMap
当执行完第一次查询就可以确定下来

我们从结果集中能得到的是JDBCType
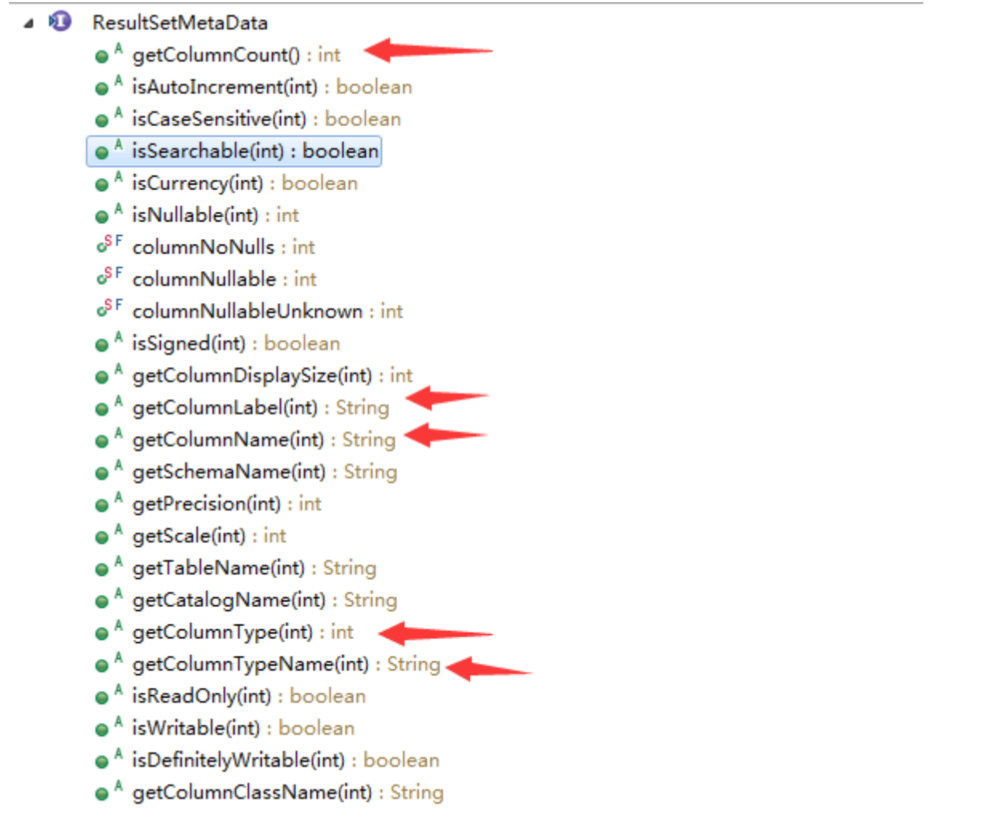
问题:
1、key 用什么?
用列名
2、取成什么java类型的值?
JDBCType中根据整型类型值获得对应的JDBCType
/** * Returns the {@code JDBCType} that corresponds to the specified * {@code Types} value * @param type {@code Types} value * @return The {@code JDBCType} constant * @throws IllegalArgumentException if this enum type has no constant with * the specified {@code Types} value * @see Types */ public static JDBCType valueOf(int type) { for( JDBCType sqlType : JDBCType.class.getEnumConstants()) { if(type == sqlType.type) return sqlType; } throw new IllegalArgumentException("Type:" + type + " is not a valid "+ "Types.java value."); }
TypeHandler ---> javaType
在TypehandlerRegistry中定义一个JDBCType类型对应的默认的TypeHandler集合,来完成取java值放入到Map中

第一次处理结果时,要把这个ResultMaps填充好,后需查询结果的处理就是直接使用resultMaps
5.3.2 方法返回集合
返回集合就是单个的重复
if(method.getReturnType() == List.class) { Type genericType = method.getGenericReturnType(); if(genericType == null) { // 当集合中放Map } else if (genericType instanceof ParameterizedType) { ParameterizedType t = (ParameterizedType) genericType; Class<?> elementType = (Class<?>)t.getActualTypeArguments()[0]; } }