论文:Cascade R-CNN Delving into High Quality Object Detection
论文链接:https://arxiv.org/abs/1712.00726
代码链接:https://github.com/zhaoweicai/cascade-rcnn
Cascade R-CNN算法是CVPR2018的文章,通过级联几个检测网络达到不断优化预测结果的目的,与普通级联不同的是,cascade R-CNN的几个检测网络是基于不同IOU阈值确定的正负样本上训练得到的,这是该算法的一大亮点。cascade R-CNN的实验大部分是在COCO数据集做的,而且效果非常出彩。
Figure1描述了文章的出发点,正是这个出发点吸引了我。(a)中u=0.5也是常用的正负样本界定的阈值,但是当阈值取0.5时会有较多的误检,因为0.5的阈值会使得正样本中有较多的背景,这是较多误检的原因;(b)用0.7的IOU阈值可以减少误检,但检测效果不一定最好,主要原因在于IOU阈值越高,正样本的数量就越少,因此过拟合的风险就越大。Figure1(c)和(d)中的曲线是用来描述localization performance,其中横坐标表示输入proposal和ground truth的IOU值,纵坐标表示输出的proposal和ground truth的IOU值。红、绿、蓝3条曲线代表训练检测模型时用的正负样本标签的阈值分别是0.7、0.6、0.5。从(c)可以看出,当一个检测模型采用某个阈值(假设u=0.6)来界定正负样本时,那么当输入proposal的IOU在这个阈值(u=0.6)附近时,该检测模型比基于其他阈值训练的检测模型的效果要好。
那么很自然地想到能不能直接用较大的阈值(比如u=0.7)来训练检测模型呢?这样是不行的,从Figure1(d)也可以看出u=0.7的效果下降比较明显,原因是较高的阈值会使得正样本数量减少,这样数据更加趋于不平衡,而且正样本数量的减少会使得模型更容易过拟合。因此这条路是走不通的,所以就有了这篇文章的cascade R-CNN,简单讲cascade R-CNN是由一系列的检测模型组成,每个检测模型都基于不同IOU阈值的正负样本训练得到,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,其界定正负样本的IOU阈值是不断上升的。
为什么要设计成cascade R-CNN这种级联结构呢?一方面:从Figure1(c)可以看出用不同的IOU阈值训练得到的检测模型对不同IOU的输入proposal的效果差别较大,因此希望训练每个检测模型用的IOU阈值要尽可能和输入proposal的IOU接近。另一方面:可以看Figure1(c)中的曲线,三条彩色曲线基本上都在灰色曲线以上,这说明对于这三个阈值而言,输出IOU基本上都大于输入IOU。那么就可以以上一个stage的输出作为下一个stage的输入,这样就能得到越来越高的IOU。总之,很难让一个在指定IOU阈值界定的训练集上训练得到的检测模型对IOU跨度较大的proposal输入都达到最佳,因此采取cascade的方式能够让每一个stage的detector都专注于检测IOU在某一范围内的proposal,因为输出IOU普遍大于输入IOU,因此检测效果会越来越好。
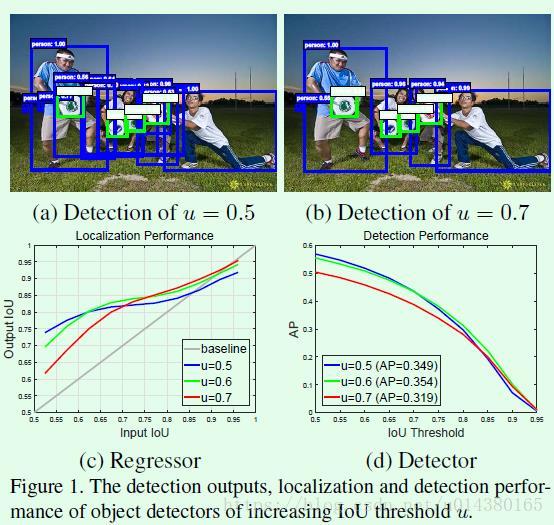
Figure3是关于几种网络结构的示意图。(a)是Faster RCNN,因为two stage类型的object detection算法基本上都基于Faster RCNN,所以这里也以该算法为基础算法。(b)是迭代式的bbox回归,从图也非常容易看出思想,就是前一个检测模型回归得到的bbox坐标初始化下一个检测模型的bbox,然后继续回归,这样迭代三次后得到结果。(c)是Integral Loss,表示对输出bbox的标签界定采取不同的IOU阈值,因为当IOU较高时,虽然预测得到bbox很准确,但是也会丢失一些bbox。(d)就是本文提出的cascade-R-CNN。cascade-R-CNN看起来和(b)这种迭代式的bbox回归以及(c)这种Integral Loss很像,和(b)最大的不同点在于cascade-R-CNN中的检测模型是基于前面一个阶段的输出进行训练,而不是像(b)一样3个检测模型都是基于最初始的数据进行训练,而且(b)是在验证阶段采用的方式,而cascade-R-CNN是在训练和验证阶段采用的方式。和(c)的差别也比较明显,cascade R-CNN中每个stage的输入bbox是前一个stage的bbox输出,而(c)其实没有这种refine的思想,仅仅是检测模型基于不同的IOU阈值训练得到而已。
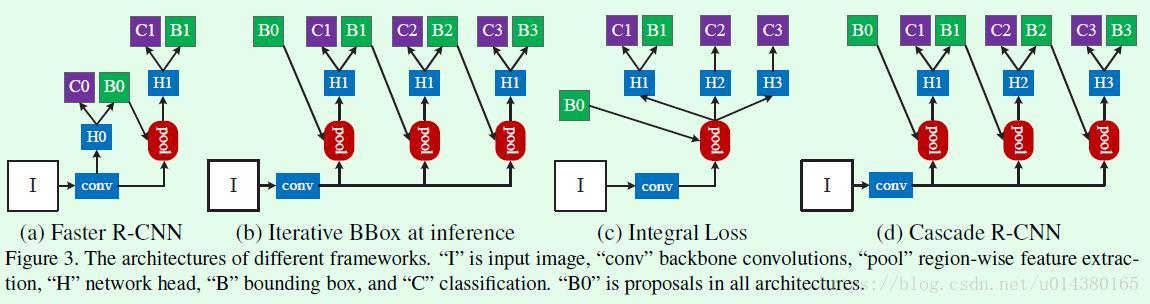
Figure3(b)这种迭代回归的方式有两个缺点:1、从Figure1(c)的实验可以知道基于不同IOU阈值训练的检测模型对不同IOU的proposal输入效果差别比较大,因此如果每次迭代都用基于相同IOU阈值的训练数据训练得到的检测模型,那么当输入proposal的IOU不在你训练检测模型时IOU值附近时,效果不会有太大提升。2、Figure2是关于迭代式bbox回归在不同阶段的四个回归值分布情况(蓝色点),可以看出在不同阶段这4个值得分布差异较大,对于这种情况,一成不变的检测模型显然难以在这种改变中达到最优效果。
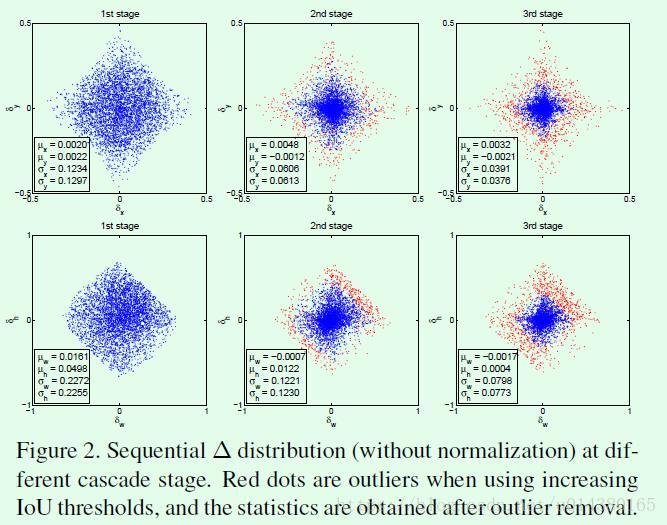
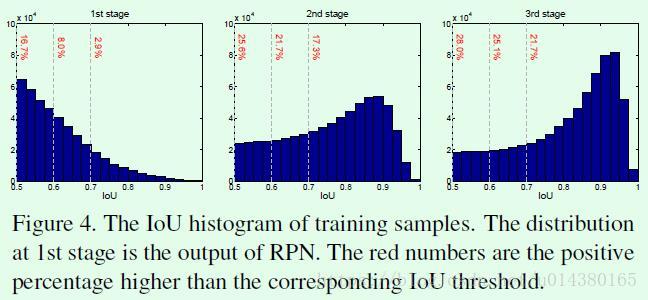
Figure4是cascade-R-CNN在不同阶段预测得到的proposal的IOU值分布情况。
实验结果:
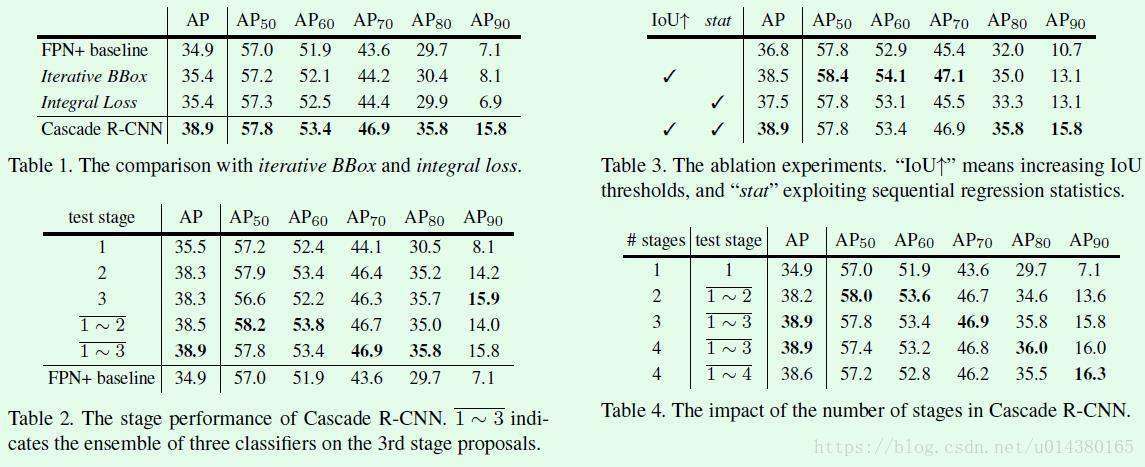
Table1是关于cascade R-CNN和Iterative bbox、Integral loss的对比。
在COCO数据集上的提升确实非常明显。
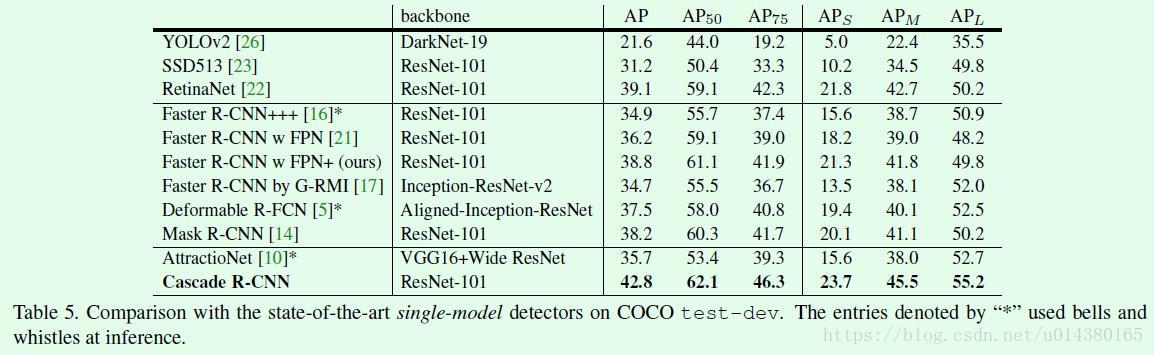
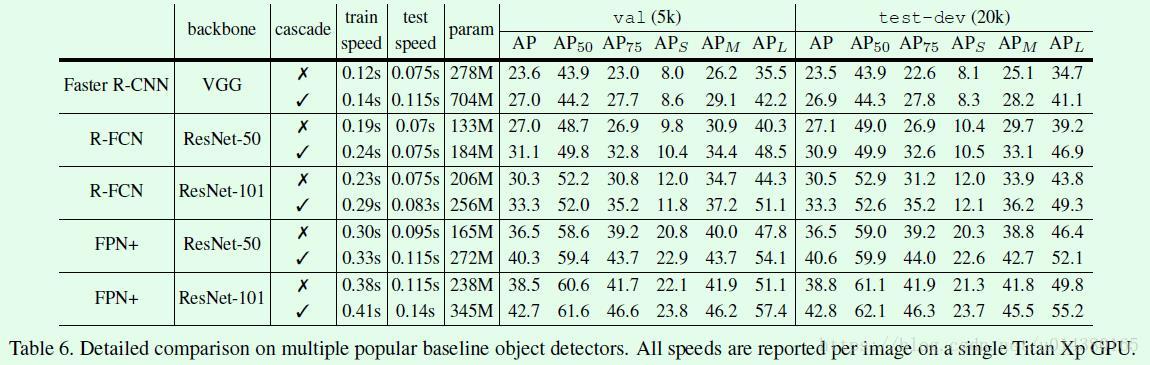
Table6主要通过在现有的two stage算法上添加cascade思想后的对比结果,另外还对比了训练、测试时间、参数量等信息。