最初是看到这个网站,决心把所有统计分布梳理一遍:Univariate distribution relationships - WM
伯努里分布 | Bernoulli distribution
二项分布 | Binomial distribution
Βeta分布 | beta distribution
泊松分布 | Poisson Distribution
指数分布 | Exponential Distribution
伽玛分布 | Gamma distribution
正态分布 | Normal Distribution | Gaussian distribution
卡方分布 | chi-squared distribution
t分布 | Student t Distribution
F分布 | F Distribution
负二项分布 | Negative binomial distribution
几何分布 | Geometric Distribution
超几何分布 | Hypergeometric distribution
连续均匀分布 | Continuous Uniform Distribution
Βeta二项分布 | Beta-binomial distribution
多维高斯分布
狄利克雷分布
帕累托分布
柯西分布
参考:An R Introduction to Statistics
| density | cumulative | ||
| discrete | PMF | CDF | PDF requires an interval P(x1<X<x2) |
| continuous | CDF | PMF is exact value P(X=x) |
伯努里分布 | Bernoulli distribution
举例:抛一次硬币的结果服从伯努利分布。
最基础的分布之一,但还是要明确它的定义。
只有一次试验,结果只有两种(这里就是0或1),已知其中一个出现的概率(比如1为θ),那么伯努利分布就是一次试验下某个结果出现的概率。
看似简单,但伯努利分布确是统计分布的基石。以伯努利分布的角度来看待二项分布:n次伯努利试验「成功」次数的离散概率分布。

二项分布 | binomial distribution
举例:抛N次硬币的结果(m次正面,N-m次反面)就服从二项分布。
分布的简写,写出其PMF公式,解释每一项的含义,分布的性质,生物信息学案例,R代码实现。
X ~ B(n, p) - 说明该分布只由这两个参数决定
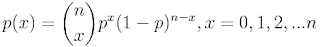
n次二项独立重复试验中,出现x次成功的概率,其中p为成功的概率。
分布的性质: 期望np和方差npq
二项分布与正态分布的关系
以DNA序列举例,100bp的DNA序列,其中A出现得概率为0.14,求A正好出现20次的概率。(假设:碱基间独立,这道题还是玩具,这个科学问题过于肤浅)
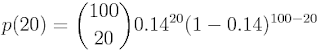
R的dbinom()函数可以直接给出某个值得PMF值;
dbinom(20, size = 100, prob = 0.14)
n和p都已知,分布已经确定,可以直接画出PMF和CDF图。(显然n决定bar的数量,p决定其PMF的形状,小于0.5就向左偏)
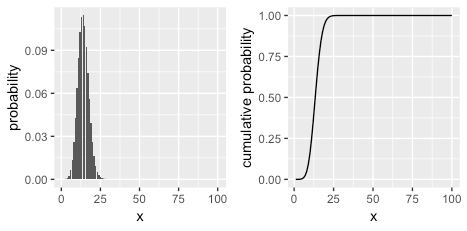
R代码:
N <- 100; p <- 0.14 g1 <- ggplot2::ggplot(data=data.frame(x=1:N, probability=dbinom(1:N, N, p)), aes(x=x, y=probability)) + geom_bar(stat="identity") g2 <- ggplot2::ggplot(data=data.frame(x=1:N, probability=pbinom(1:N, N, p)), aes(x=x, y=probability)) + geom_line() + labs(y="cumulative probability") cowplot::plot_grid(g1,g2)
接下来是一些脑经急转弯:
至少观察到28个A的概率?请用CDF来求解
等价于1-最多27个A,因为是离散的整数
1 - pbinom(27, size = 100, prob = 0.14)
还可以模拟,概率是什么?不就是事件发生的次数除以总的事件数吗?
rbinom有点难理解,第二第三个是二项分布的参数,第一个是整个实验的次数;比如第一次100个碱基里只有1个A,第二次没有,做100w次,因为是小概率事件,如果你只做100次,得到的概率几乎为0!!!
x <- rbinom(1000000, 100, 0.14) sum(x>=28) / length(x)
额外阅读:Compositional Heterogeneity within, and Uniformity between, DNA Sequences of Yeast Chromosomes
部分参考:Using the binomial distribution in R for bioinformatics
超前沿实例:
在motif enrichment分析时,某个motif在flanking area里出现的频率可以看做是二项分布。可以这样来做统计推断,假设背景里是二项分布,我们再在interested area里算概率。
Βeta分布 | beta distribution
举例:
如何通俗理解 beta 分布? - 讲得非常好
beta分布重要的性质?共轭,属于指数函数族。
beta分布最常出现在贝叶斯推断的先验估计中。
beta分布的写法如下: ,可以看到其只有两个参数,α和β,它们都是shape parameters,对于beta分布,它的定义域就是0到1,恰好是概率的区间,所以beta可以被用作是描述概率的概率分布。
,可以看到其只有两个参数,α和β,它们都是shape parameters,对于beta分布,它的定义域就是0到1,恰好是概率的区间,所以beta可以被用作是描述概率的概率分布。
由于beta分布的公式比较晦涩,有和gamma有很强的联系,暂时就不深入了。
接下来需要用R把beta分布可视化一下:
x <- seq(0, 1, length = 100) dbeta(x, 81, 219) library(ggplot2) g1 <- ggplot2::ggplot(data=data.frame(x=x, probability=dbeta(x, 81, 219)), aes(x=x, y=probability)) + geom_bar(stat="identity") g2 <- ggplot2::ggplot(data=data.frame(x=x, probability=dbeta(x, 181, 419)), aes(x=x, y=probability)) + geom_bar(stat="identity") cowplot::plot_grid(g1,g2)
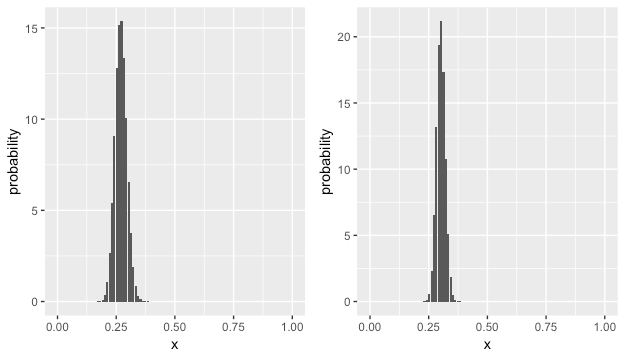
beta分布很适合作为二项分布模型的先验概率估计,因为它有着共轭的优秀性质。
用一句话来说,beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。
泊松分布 | Poisson Distribution
泊松分布看似简单,只有一个参数λ,其实还是有点难以理解的。
最好以二项分布为切入点,来理解泊松分布。The Connection Between the Poisson and Binomial Distributions
当二项分布X ~ B(n, p) 的n无限大、p无限小,且np=λ时,二项分布和泊松分布就是等价的。这就是为什么说泊松分布是用来描述rare event的。
大部分情况下,我们只是拿泊松分布来近似描述我们的数据。
举例1:随机抽取一个家庭,调查家里孩子的数量n,n服从均值为λ的泊松部分。近似而已。
只要随机变量是离散的,且其有一个明显的均值,那就可以用泊松分布来模拟随机变量的分布。
举例2:每次抛n次硬币,随机变量为得到正面的次数为m,显然在多次试验后m有个均值λ,那m就可以用均值为λ的泊松分布来模拟了。
一句话总结:泊松分布是二项分布的一个特例,n无限大且np极限为lambda。
分布的简写,写出其PMF公式,解释每一项的含义,分布的性质,生物信息学案例,R代码实现。
X ~ Po(λ) - 泊松分布只与lambda有关,记发比较多有π(),也有P()
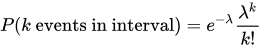
单位时间/空间内事件发生次数的概率,lambda就是单位时间/空间内的平均次数,k就是次数;
分布的性质:期望方差相等;两个泊松分布变量之和仍然为泊松分布;
R代码可视化:
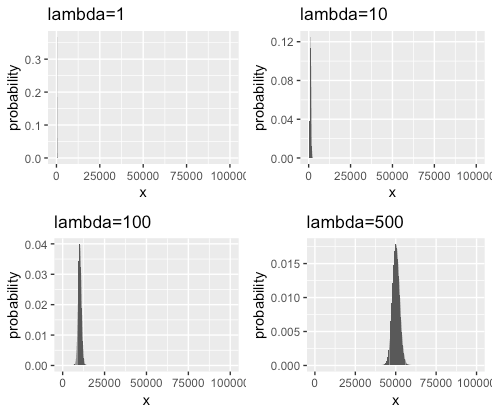
library(ggplot2) N <- 1000; g1 <- ggplot(data=data.frame(x=1:N*100, probability=dpois(1:N, 1)), aes(x=x, y=probability)) + geom_bar(stat="identity") + labs(title="lambda=1") g2 <- ggplot(data=data.frame(x=1:N*100, probability=dpois(1:N, 10)), aes(x=x, y=probability)) + geom_bar(stat="identity") + labs(title="lambda=10") g3 <- ggplot(data=data.frame(x=1:N*100, probability=dpois(1:N, 100)), aes(x=x, y=probability)) + geom_bar(stat="identity") + labs(title="lambda=100") g4 <- ggplot(data=data.frame(x=1:N*100, probability=dpois(1:N, 500)), aes(x=x, y=probability)) + geom_bar(stat="identity") + labs(title="lambda=500") cowplot::plot_grid(g1,g2,g3,g4)
进阶:
泊松分布和二项分布的关系,参考文章,比较分析会极大地加深你对统计的整体理解。
首先通过绘图来直观地理解结论:
为了把二项分布和泊松分布联系起来,二项分布的n必须无限大(因为泊松分布描述的就是无限情况下的期望问题),为了获得同期望,则 np 存在有极限 λ,所以才会要求p无限小。
R函数里的第一个参数1:N就是bar的个数,泊松分布只要lambda不变,第一个参数不会改变图的性状。
library(ggplot2) N <- 1000; lambda <- 10; p <- lambda/N g1 <- ggplot(data=data.frame(x=1:N, probability=dbinom(1:N, N, p)), aes(x=x, y=probability)) + geom_bar(stat="identity") + labs(title="Binomial distribution") g2 <- ggplot(data=data.frame(x=1:N, probability=dpois(1:N, lambda)), aes(x=x, y=probability)) + geom_bar(stat="identity") + labs(title="Poisson Distribution") cowplot::plot_grid(g1,g2)

怎么理解这两张图?只是从不同的角度来描述同一个东西。
二项分布:个体角度,作了n次试验,n接近无限大,成功(发生)k次的概率分布;
泊松分布:总体角度,单位时间的期望已知(次数无穷或不可知),单位时间内发生k次的概率;(对每一次而言是服从特定二项分布的,也就是泊松分布肯定可以被转换成二项分布)
进阶2:一个lambda就可以确定泊松分布吗,还有其他限定条件吗?因为同lambda下有无限种可能,他们都是同种泊松分布吗?
比较泊松分布和二项分布:
字面形式:泊松和二项都是描述某一事件发生n次的概率,但是前提却不一样。还是以通过学校大门为例,泊松分布的描述是每个人独立通过大门(每个人独立,但并不知道每个人通过的概率),一段事件内通过n人的概率,我们知道的是平均数。二项分布是我知道每个人通过的概率(也必须要独立),我可以知道N人选择后,其中有n个人选择通过的概率。
所以,重要的区别是每个事件到底是不是等概率发生的!!!
泊松分布性质:数学期望与方差相等,同为参数λ:E(X)=V(X)=λ
在RNA-seq中,技术误差是满足泊松分布的,因为期望和方差差不多。但是生物学重复之间的误差不能用泊松分布来描述,因为他的方差可能很大,所以要用负二项分布,加了一个额外的误差项。
生物信息中的举例:
1. 单位长度内DNA序列的变异数;
2. 一定时间内细胞里正在表达的基因的个数;
3. 快速估算测序量,如果要保证基因组上95%的区域覆盖深度在30x以上的话,那么最低的测序深度应该是多少? / 文章2
参考:书籍 - Statistical Bioinformatics with R 直达案例
泊松分布的现实意义是什么,为什么现实生活多数服从于泊松分布? - 知乎 案例
指数分布 | Exponential Distribution
要等到一个随机事件发生,需要经历多久时间。必须在泊松分布之后讲,因为它就是基于泊松过程Poisson point process的;必须在gamma分布之前讲,因为它是gamma分布的一个特例。
两次事件之间的时间间隔大于t 的概率,等同于t 时间内没有发生一件事的概率,因此就可以根据泊松分布来推导出指数分布。
具体参考这个:指数分布公式的含义是什么?
指数分布描述的是事件的时间间隔的概率。指数分布的公式可以从泊松分布推断出来。(连续型概率分布)
举例:婴儿出生的时间间隔;来电的时间间隔;奶粉销售的时间间隔;网站访问的时间间隔。
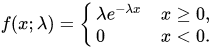
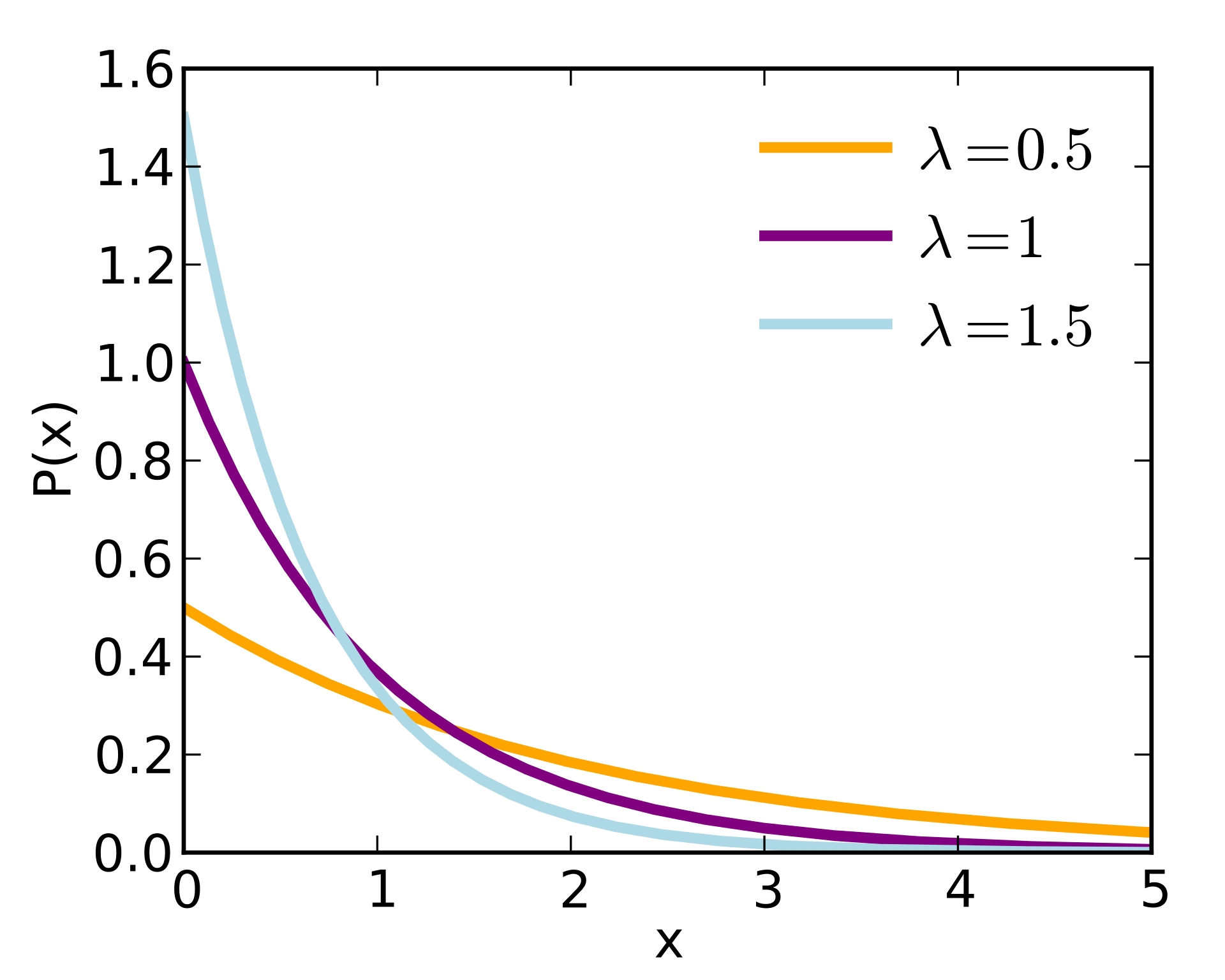
可以看到,随着间隔时间变长,事件的发生概率急剧下降,呈指数式衰减。
伽玛分布 | Gamma distribution
怎么来理解伽玛(gamma)分布? - 知乎上的统计和机器学习氛围很好
要等到n个随机事件都发生,需要经历多久时间
gamma分布有两个参数:一个形状参数α,一个inverse scale parameter:β.

知乎曾博的热评:α 代表一件事发生的次数;β代表它发生一次的概率(或者叫速率)。那么gamma 分布就代表这么一件事发生α 次所需要时间的分布。例如α=1 就是指数分布。
曾博的答案已经非常接近了,但是beta并不是概率,而是平均发生的时间。
再令,即从头开始到第
次事件的发生的时间,该随机变量分布即为Gamma分布。即
。
接下来的四个分布属于一个系列:正态分布的前世今生(3)-三大分布(卡方分布、t分布、F分布)。
这三个的概率密度最终都得写成基于gamma分布的形式:三大抽样分布:卡方分布,t分布和F分布的简单理解。
正态分布 | Normal Distribution | Gaussian distribution
最早出现,三大分布出现后更加捧出了它的大哥地位。
卡方分布 | chi-squared distribution
最早发现这个分布的其实是物理学家麦克斯韦,他在推导空气分子的运动速度的分布时,发现分子速度在三个坐标轴上的分量是正态分布,而分子运动速度的平方v^2符合自由度为3的χ2分布。麦克斯韦虽然发现了这个分布,但是真正把他完善并推广的是皮尔逊。
之前我们都是考虑一个随机变量X的分布,很直观,但有考虑随机分布的运算吗?比如X ~ X12 + X22,这又是个什么分布?怎么理解这个相加?
卡方分布只有一个参数,自由度。期望:n,方差:2n。
如何将卡方分布、卡方检验、卡方拟合优度检验联系在一起?
卡方检验的用途
应用案例:
t分布 | Student t Distribution
F分布 | F Distribution
负二项分布 | Negative binomial distribution

麻蛋,从来就搞不清楚什么是负二项分布!!!
“负二项分布”与“二项分布”的区别在于:“二项分布”是固定试验总次数N的独立试验中,成功次数k的分布;而“负二项分布”是所有到成功r次时即终止的独立试验中,失败次数k的分布。
是不是有点绕口,不好理解。
举例:若我们掷骰子,掷到一即视为成功。则每次掷骰的成功率是1/6。要掷出三次一,所需的掷骰次数属于集合{ 3, 4, 5, 6, ... }。掷到三次一的掷骰次数是负二项分布的随机变数。
就是我们一定要成功r次,无论做多少次实验。这个分布描述的是失败k次的概率。当r=1时,我们只需成功1次,所以失败0次的概率就等于一次成功的概率,就是p,失败一次就是第一次失败,再做一次实验,第二次成功。
Why do we use the negative binomial distribution for analysing RNAseq data?
搞清楚:负二项分布适用于描述重复样本之间某个基因的counts的分布,而不是不同处理之间的分布(不同处理之间不独立)。
Question: What Makes One Probability Distribution Better For Rna-Seq Than Another?
每一个reads计数是一个事件,计到该基因则为成功,计到其他基因则为失败。(哈哈,千万不要这么去理解负二项分布,负二项分布还有一种解释!!!)
Single-gene negative binomial regression models for RNA-Seq data with higher-order asymptotic inference
The technical variability in RNA-Seq read counts has been demonstrated to be near Poisson [9], but RNA-Seq reads from independent biological samples commonly show extra-Poisson variation (i.e., overdispersion) and practically useful models must also incorporate this biological variability.
The second definition sounds more intimidating but is much more useful. The NB distribution can be defined as a Poisson-Gamma mixture distribution. This means that the NB distribution is a weighted mixture of Poisson distributions where the rate parameter 
WHY SEQUENCING DATA IS MODELED AS NEGATIVE BINOMIAL (讲得是真的好,一定要看)
千万不要用百度、维基上的解释来套RNA-seq。
就简单的把负二项分布理解为泊松分布的变种就好了,它能够有效地度量数据的偏差(不是技术重复的偏差,而是生物学重复的偏差)。
就这个立即就OK了。
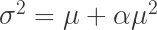
卡方分布
之前厌恶统计学,尤其是假设检验里面的各种莫名其妙的分布,老师就讲一些枯燥的公式理论,我都不知道有个屌用。
强烈要求中国的教学改革,因材施教,根据学生的背景知识来教学,而不是讲一些脱离实际的公式符号,这真的是在消耗某些学生的兴趣,将人才扼杀于摇篮之中。
其实教学是最昂贵的资源,发达国家早就做到了,因材施教,只是学费昂贵罢了。中国现在的脱离实际的应试教育也是国情所迫的,谁又能改变呢?AI吧!
普通个体要想真实掌握自己的命运就一定要会自学,还好有互联网,自学的人才能抱团取暖。致敬互联网的分享精神。
k个独立的标准正态分布变量的平方和服从自由度为k的卡方分布。卡方分布是一种特殊的伽玛分布。
Chi-Square Statistic: How to Calculate It / Distribution
三大抽样分布一般是指卡方分布(χ2分布)、t分布和F分布,是来自正态总体的三个常用的分布。
正文:二项分布和泊松分布的关系
定义
二项分布:P(X=k)=Cnkpk(1-p)(n-k)
抛硬币,假设硬币不平整,抛出正面的概率为p,那么在n次抛硬币的实验中,出现k次正面的概率
泊松分布: p(X=k)=λke-λ/k!
公共汽车站在单位时间内,来乘车的乘客数为k 的概率。假定平均到站乘客数为λ
二项分布和泊松分布的关系
n很大,p很小时泊松分布可以用来近似二项分布,此时 λ=np
二者关系的直观解释:
从泊松分布说起。把单位时间分成n等分,称为n个时间窗口。那么在某个时间窗口来一个客人的概率为λ/n.(稍后解释,其实这是不对的)那么我们可以将泊松分布和二项分布对应起来:在某个时间窗口里来了乘客 对应 抛出正面硬币;来了k个客人 对应 抛出k个正面。因此,泊松分布和二项分布近似了。
多项分布
二项分布的典型例子是扔硬币,硬币正面朝上概率为p, 重复扔n次硬币,k次为正面的概率即为一个二项分布概率。(严格定义见伯努利实验定义)。把二项分布公式推广至多种状态,就得到了多项分布。例如在上面例子中1出现k1次,2出现k2次,3出现k3次的概率分布情况。
高斯分布和多维高斯分布
狄利克雷分布 | dirichlet distribution
题外话:
最近学习了基因组组装的课程,其中在使用kmer估算基因组大小时,讲到了二项分布和泊松分布,课程把它们的由来和关系讲得十分透彻,同时与具体实例相结合,本文再对它做一个总结。
通过这个例子也会真实的感受到数学的神奇,数学公式的变换,奇妙的证明,最神奇的是它的应用,让我想起了一本很有名但我一直都没有去看的书 --《数学之美》
参考:
泊松分布和指数分布:10分钟教程 - 阮一峰
统计学是不是数学? - 知乎