内容导读
一 列表的创建
name_list = ['alex', 'seven', 'eric'] #直接通过大括号创建
name_list = list(['alex', 'seven', 'eric']) # 通过list() 内置函数创建
a =range(200) #直接创建0到199 的列表
# >> <class 'range'>
a = list(range(1,200,2)) #从1开始数,然后不断地加2,直到达到或超过终值(200)
# 列表推导式
a = [i+i for i in list1]
b = [i.upper() for i in list1 if isinstance(i,str)] # 如果值是str才保留
c = [i.upper() if isinstance(i,str) else i for i in list1] # 保留非str的值
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
d= ['%s %s' % (c, s) for c in colors for s in sizes]
#>>['black S', 'black M', 'black L', 'white S', 'white M', 'white L']
二 列表的基本操作
-
切片
name =slice(2,4) # >> s[2:4] == s[name] #代码中如果出现大量的硬编码下标值会使得可读性和可维护性大大降低,所有以此来解决 print(list1[0-2]) #>>>c 注意:此处0-2是减法运算,结果为-2 print(list1[0:2]) # >>>['a', 'b'] 注意:此处2是去不到的,实质是取 0,1 print(list1[-1:-5]) #>>>[ ] 注意:不能从右往左切 print(list1[-5:-1]) #>>>['a', 'b', 'c'] print(list1[-6:-1]) # >>>['a', 'b', 'c'] print(list1[-5:]) #>>>['a', 'b', 'c', 'b'] print(list1[0:5:2]) # >>>['a', 'c'] 注意:此处2为步长 -
增加
list1 = [1,2,3] list1.append("s") #追加 list1.insert(0,"ss") #插入, 在0处插入“ss” list1.extend(list2) # 将list2扩展到list1后面 list1+list2 # 将两个列表拼接起来 list1*3 # [1,2,3,1,2,3,1,2,3] -
删除
根据内容来删除 list1.remove("a") # 移除指定元素,(有多个此元素时,只删除第一个) #不知道位置,但是知道元素的值 根据索引来删除 del list1[1:2] # 批量删除 del list1[1] li = list1.pop() #删除并获取最后一个元素 li = list1.pop(local) #删除并获取指定位置的元素 #不知道值,知道位置 -
修改
list[2] = "aa" list[2:5] = "aaa" #>> > ['a', 'b', 'a', 'a', 'a'] list[2:5] = "aaa", 12, 13 #>> > ['a', 'b', 'aaa', 12, 13] -
查询
print(list1.index("a")) # 在列表中查找指定值第一次出现的索引。,"a"不存在报错 print(list1.count("a")) # 方法count计算指定的元素在列表中出现了多少次。 ,"a"不存在返回0 -
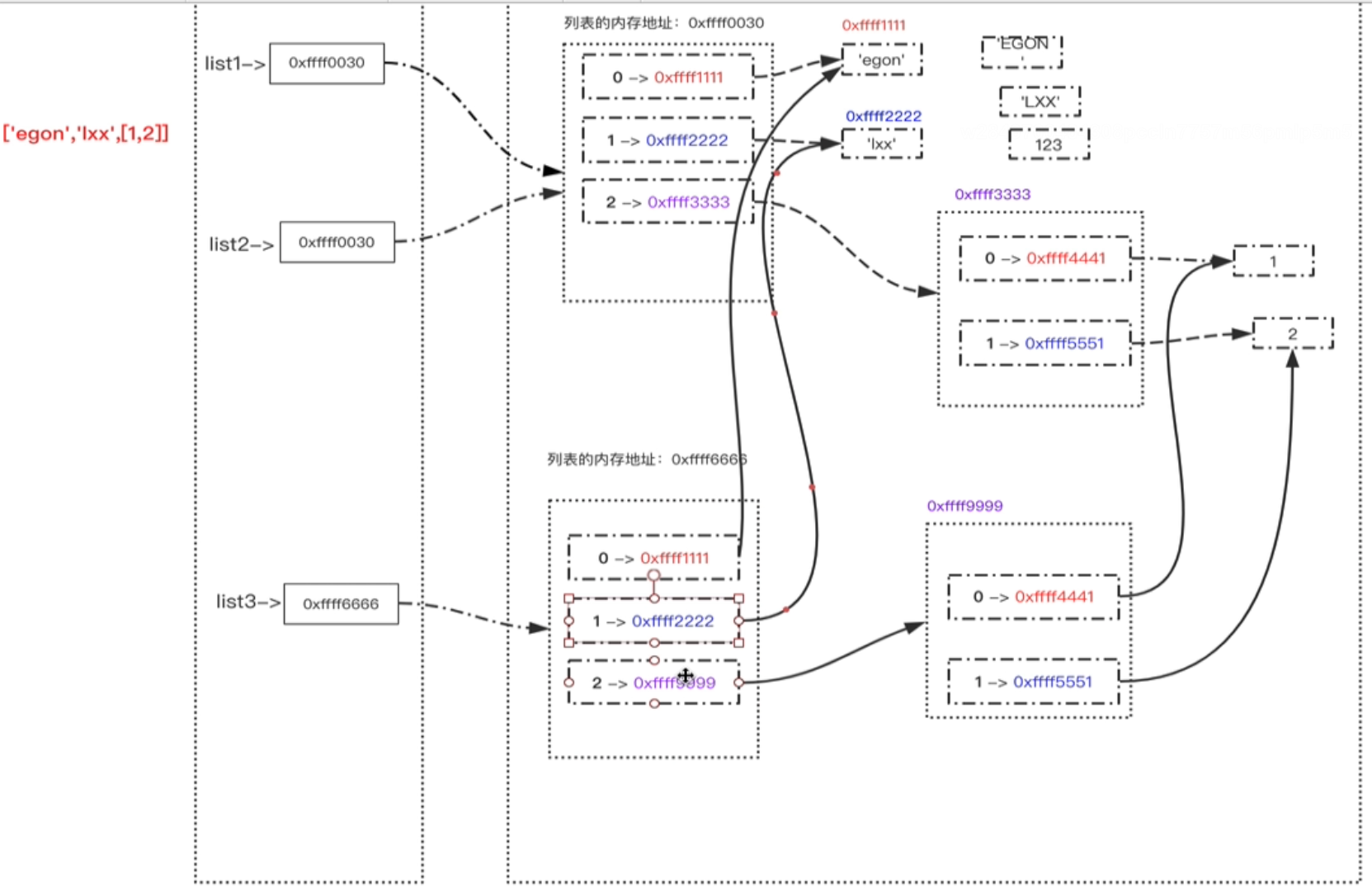
列表的深浅拷贝(根据数据的可变,与不可变,有所不同)
一句话 深浅拷贝的区别,深拷贝碰到容器(可变),就造一个新容器,装原来容器里的东西,其他都是拷贝原来的东西a = [1,2,3,[5,6] 浅拷贝 把原列表第一层的内存地址不加区分全部拷贝给新列表 a2 = a.copy() == a2 = a[ : ] #复制成一个独立的列表,列表内存地址不同,但列表内的数据的地址是相同的, #修改a中的不可变数据类型1,2,3,对a2没有影响,因为此时a中数据的内存地址都更换了 #但是修改a中的不可变数据类型,如[5,6],那么a2中的[5,6]也会发生改变 深拷贝 # 拷贝时对列表的值的可变性进行区分, #可变类型产生一个新的内存地址(容器),新内存地址里将原可变类型里的值复制一份 #不可变类型拷贝原内存地址 import copy list2 =copy.deepcopy(a) # list与list2全无瓜葛 -
排序
临时性的,需要赋值 sorted(list,reverse = True) #临时性的排序(可反向),如需永久,需要赋值 永久性的,改变自身 reverse() #反转列表 list1.sort() #永 注意 : 字符和数字不能混排,字母和符号按ASCII排 list1.sort(reverse=True ) #反向排序 list1.sort(key=len) # 根据长度来排序 -
枚举
sizes = ['S', 'M', 'L'] for i in enumerate(size): print(i) """ >>> (0, 'S') (1, 'M') (2, 'L') """ for index,i in enumerate(sizes) : print(index,i) """ 0 S 1 M 2 L """ # 流畅的python书上看到的用法 traveler_ids = [['USA', '31195855',1], ['BRA', 'CE342567',1],['ESP', 'XDA205856',1]] for i,s,g in traveler_ids: print(i,s,g) """ USA 31195855 1 BRA CE342567 1 ESP XDA205856 1 """ -
长度,包含,循环,清空
len(list) #长度 a in list: # 包含 list.clear() # 清空 -
min max sum
列表必须都是数值类型,否则出错,字典可以根据key的ASCII来计算min,和maxdigits = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] min(digits) #0 max(digits) #9 sum(digits) #45 -
列表的拆包(元组用法相同)
# 平行赋值 sizes = ['S', 'M', 'L'] s,m,l = sizes print(s,m,l) # >>S,M,L #对不敢兴趣的内容用 _ 下划线代替 _,_,l = sizes print(l) #>>L #用*来处理拆包剩下的元素 a, b, *rest = range(5) print(a, b, rest) # > 0, 1, [2, 3, 4] a, *body, c, d = range(5) *head, b, c, d = range(5)