1. 安装hadoop
详细请参见本人的另外一片博文《Hadoop 2.7.3 分布式集群安装》
2. 下载hive 2.3.4
解压文件到/opt/software
tar -xzvf ~/Downloads/apache-hive-2.3.4-bin.tar.gz -C /opt/software/
3. 配置hive环境变量:
sudo vim /etc/profile
在文件末尾添加:
#hive export HIVE_HOME=/opt/apache-hive-2.3.4-bin export HIVE_CONF_HOME=$HIVE_HOME/conf export PATH=.:$HIVE_HOME/bin:$PATH export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/* export HCAT_HOME=$HIVE_HOME/hcatalog export PATH=$HCAT_HOME/bin:$PATH
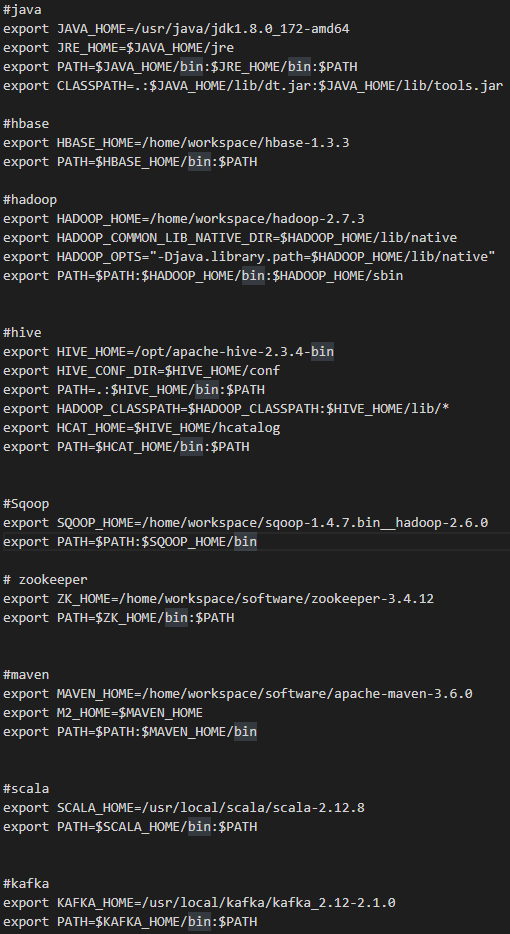
在本人机器上之前已经配置好了hadoop和jdk
4. 配置hive配置文件
cd /opt/software/apache-hive-2.3.4-bin/conf/ mv beeline-log4j2.properties.template beeline-log4j2.properties mv hive-env.sh.template hive-env.sh mv hive-exec-log4j2.properties.template hive-exec-log4j2.properties mv hive-log4j2.properties.template hive-log4j2.properties mv llap-cli-log4j2.properties.template llap-cli-log4j2.properties mv llap-daemon-log4j2.properties.template llap-daemon-log4j2.properties mv hive-default.xml.template hive-default.xml
vim /opt/software/apache-hive-2.3.4-bin/conf/hive-site.xml
修改以下几个配置项:
javax.jdo.option.ConnectionURL
javax.jdo.option.ConnectionUserName
javax.jdo.option.ConnectionPassword
javax.jdo.option.ConnectionDriverName
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?characterEncoding=UTF8&useSSL=false&createDatabaseIfNotExist=true</value>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
注意: com.mysql.cj.jdbc.Driver这个配置可能在有些文章中是让配置成com.mysql.jdbc.Driver,这是不对的,如果这样,在启动hive时会警告
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
将${system:java.io.tmpdir}和${system:user.name}替换为/home/lenmom/hive_tmp和lenmom
:%s/${system:java.io.tmpdir}//home/lenmom/hive_tmp/g
:%s/${system:user.name}//lenmom/g
如果不替换,在运行的时候会报错,类似
Failed with exception java.io.IOException:java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:user.name%7D
the configration below is the configuration from production systems(cdh 5.11.1):
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--hive cli terminal settings--> <property> <name>hive.cli.print.current.db</name> <value>false</value> <description>Whether to include the current database in the Hive prompt.</description> </property> <property> <name>hive.cli.print.header</name> <value>false</value> <description>Whether to print the names of the columns in query output.</description> </property> <property> <name>hive.cli.prompt</name> <value>hive</value> <description>Command line prompt configuration value. Other hiveconf can be used in this configuration value. Variable substitution will only be invoked at the Hive CLI startup. </description> </property> <property> <name>hive.cli.pretty.output.num.cols</name> <value>-1</value> <description>The number of columns to use when formatting output generated by the DESCRIBE PRETTY table_name command. If the value of this property is -1, then Hive will use the auto-detected terminal width. </description> </property> <!-- metastore - mysql--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>User for Hive Metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>Password for Hive Metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://127.0.0.1:3306/hive_2_3_4?characterEncoding=UTF8&useSSL=false&createDatabaseIfNotExist=true</value> <description></description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description></description> </property> <property> <name>hive.metastore.try.direct.sql.ddl</name> <value>false</value> <description></description> </property> <property> <name>hive.metastore.try.direct.sql</name> <value>true</value> <description>Whether Hive Metastore should try to use direct SQL queries instead of DataNucleus for certain read paths. This can improve metastore performance by orders of magnitude when fetching many partitions. In case of failure, execution will fall back to DataNucleus. This configuration is not supported and is disabled when Hive service is configured with Postgres</description> </property> <property> <name>datanucleus.autoCreateSchema</name> <value>false</value> <description>Automatically create or upgrade tables in the Hive Metastore database when needed. Consider setting this to false and managing the schema manually.</description> </property> <property> <name>datanucleus.metadata.validate</name> <value>false</value> <description>Prevent Metastore operations in the event of schema version incompatibility. Consider setting this to true to reduce probability of schema corruption during Metastore operations. Note that setting this property to true will also set datanucleus.autoCreateSchema property to false and datanucleus.fixedDatastore property to true. Any values set in Cloudera Manager for these properties will be overridden</description> </property> <property> <name>hive.metastore.schema.verification</name> <value>true</value> <description>Prevent Metastore operations in the event of schema version incompatibility. Consider setting this to true to reduce probability of schema corruption during Metastore operations. Note that setting this property to true will also set datanucleus.autoCreateSchema property to false and datanucleus.fixedDatastore property to true. Any values set in Cloudera Manager for these properties will be overridden</description> </property> <property> <name>datanucleus.autoStartMechanism</name> <value>SchemaTable</value> <description></description> </property> <property> <name>datanucleus.fixedDatastore</name> <value>true</value> <description></description> </property> <property> <name>datanucleus.autoStartMechanism</name> <value>SchemaTable</value> <description></description> </property> <property> <name>hive.async.log.enabled</name> <value>false</value> <description></description> </property> <property> <name>hive.metastore.execute.setugi</name> <value>true</value> <description></description> </property> <property> <name>javax.jdo.PersistenceManagerFactoryClass</name> <value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value> <description>class implementing the jdo persistence</description> </property> <!--file format setting--> <property> <name>hive.default.fileformat</name> <value>Parquet</value> <description>Default file format for CREATE TABLE statement. Options are TextFile and SequenceFile,rcfile,ORC,Parquet. Users can explicitly say CREATE TABLE ... STORED AS [textfile, sequencefile, rcfile, orc,parquet] to override</description> </property> <property> <name>hive.default.fileformat.managed</name> <value>parquet</value> <description> 可能值: [none, textfile, sequencefile, rcfile, orc,parquet]. 指定了创建 managed table 时默认的文件格式。 此值不会影响创建的外部表的默认文件格式。如果此值是 none 或没有设置,将会使用 hive.default.fileformat 指定的值 </description> </property> <property> <name>hive.default.rcfile.serde</name> <value>org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe</value> <description>The default SerDe Hive will use for the RCFile format</description> </property> <property> <name>hive.fileformat.check</name> <value>true</value> <description>Whether to check file format or not when loading data files</description> </property> <property> <name>hive.file.max.footer</name> <value>100</value> <description>maximum number of lines for footer user can define for a table file</description> </property> <!-- Hive Metastore Setting Turning Begin--> <property> <name>hive.metastore.server.max.threads</name> <value>3000</value> <description>Maximum number of worker threads in the Hive Metastore Server's thread pool</description> </property> <property> <name>hive.metastore.server.min.threads</name> <value>50</value> <description>Minimum number of worker threads in the Hive Metastore Server's thread pool</description> </property> <property> <name>datanucleus.connectionPool.maxPoolSize</name> <value>50</value> <description></description> </property> <property> <name>hive.metastore.server.max.message.size</name> <value>500</value> <description>Maximum message size Hive MetaStore accepts</description> </property> <property> <name>hive.cluster.delegation.token.store.class</name> <value>org.apache.hadoop.hive.thrift.MemoryTokenStore</value> <description>The delegation token store implementation class. Use DBTokenStore for Highly Available Metastore Configuration</description> </property> <property> <name>hive.metastore.client.socket.timeout</name> <value>300</value> <description>Timeout for requests to the Hive Metastore Server. Consider increasing this if you have tables with a lot of metadata and see timeout errors. Used by most Hive Metastore clients such as Hive CLI and HiveServer2, but not by Impala. Impala has a separately configured timeout</description> </property> <property> <name>hive.metastore.fshandler.threads</name> <value>15</value> <description> The number of threads the metastore uses when bulk adding partitions to the metastore. Each thread performs some metadata operations for each partition added, such as collecting statistics for the partition or checking if the partition directory exists. This config is also used to control the size of the threadpool used when scanning the filesystem to look for directories that could correspond to partitions, each thread performs a list status on each possible partition directory </description> </property> <!--hive server2 settings--> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://127.0.0.1:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary',default 10000.</description> </property> <property> <name>hive.server2.thrift.http.port</name> <value>10001</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'http'.</description> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>0.0.0.0</value> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property> <property> <name>hive.server2.webui.host</name> <value>0.0.0.0</value> <description>the HiveServer2 binds to the wildcard address ("0.0.0.0") on all of its ports</description> </property> <property> <name>hive.server2.webui.port</name> <value>10002</value> <description>The port the HiveServer2 WebUI will listen on. This can be set to 0 to disable the WebUI</description> </property> <property> <name>hive.server2.webui.use.ssl</name> <value>false</value> <description> Encrypt communication between clients and HiveServer2 WebUI using Transport Layer Security (TLS) (formerly known as Secure Socket Layer (SSL) </description> </property> <property> <name>hive.server2.webui.max.threads</name> <value>50</value> <description>The max threads for the HiveServer2 WebUI</description> </property> <property> <name>hive.server2.enable.doAs</name> <value>true</value> <description>HiveServer2 will impersonate the beeline client user when talking to other services such as MapReduce and HDFS.</description> </property> <property> <name>hive.warehouse.subdir.inherit.perms</name> <value>true</value> <description>Let the table directories inherit the permission of the Warehouse or Database directory instead of being created with the permissions derived from dfs umask. This allows Impala to insert into tables created via Hive </description> </property> <property> <name>hive.log.explain.output</name> <value>false</value> <description>When enabled, HiveServer2 logs EXPLAIN EXTENDED output for every query at INFO log4j level.</description> </property> <property> <name>hive.server2.use.SSL</name> <value>false</value> <description>Encrypt communication between clients and HiveServer2 using Transport Layer Security (TLS) (formerly known as Secure Socket Layer (SSL)).</description> </property> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive-staging</value> <description>Directory in HDFS where Hive writes intermediate data between MapReduce jobs. If not specified, Hive uses a default location.</description> </property> <property> <name>hive.querylog.location</name> <value>/home/lenmom/workspace/software/apache-hive-2.3.4-bin/logs</value> <description></description> </property> <!--beeline not show detail mr logs, the logs would be redirect to the log files.--> <property> <name>hive.server2.logging.operation.enabled</name> <value>true</value> <description>When enabled, HiveServer2 will temporarily save logs associated with ongoing operations. This enables clients like beeline and Hue to request and display logs for a particular ongoing operation. Logs are removed upon completion of operation. </description> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/home/lenmom/workspace/software/apache-hive-2.3.4-bin/logs</value> <description>Top level directory where operation logs are temporarily stored if Enable HiveServer2 Operations Logging is true. Logs are stored in session and operation level subdirectories under this location and are removed on completion of operation. </description> </property> <property> <name>hive.execution.engine</name> <value>mr</value> <description>The default execution engine for running hive queries. Can be set to mr for MapReduce or spark for Spark.</description> </property> <!--this item can only take effect if hive.execution.engine set to spark--> <!-- <property> <name>spark.master</name> <value>yarn-cluster</value> <description>Name of the Spark on YARN service that this Hive service instance depends on. If selected, Hive jobs can use the Spark execution engine instead of MapReduce2. Requires that Hive depends on YARN. See Configuring Hive on Spark for more information about Hive on Spark. In CDH releases lower than 5.7, Hive on Spark also requires setting Enable Hive on Spark to true </description> </property> --> <!--hive server2 perf tuning--> <property> <name>hive.server2.session.check.interval</name> <value>900000</value> <description> The check interval for session/operation timeout, in milliseconds, which can be disabled by setting to zero or a negative value </description> </property> <property> <name>hive.server2.idle.session.timeout</name> <value>43200000</value> <description> Session will be closed when not accessed for this duration of time, in milliseconds; disable by setting to zero or a negative value </description> </property> <property> <name>hive.server2.idle.session.timeout_check_operation</name> <value>true</value> <description> Session will be considered to be idle only if there is no activity, and there is no pending operation. This setting takes effect only if session idle timeout (hive.server2.idle.session.timeout) and checking (hive.server2.session.check.interval) are enabled </description> </property> <property> <name>hive.server2.idle.operation.timeout</name> <value>21600000</value> <description></description> </property> <property> <name>hive.server2.thrift.min.worker.threads</name> <value>5</value> <description></description> </property> <property> <name>hive.server2.thrift.max.worker.threads</name> <value>1000</value> <description></description> </property> <property> <name>mapred.reduce.tasks</name> <value>-1</value> <description>Default number of reduce tasks per job. Usually set to a prime number close to the number of available hosts. Ignored when mapred.job.tracker is "local". Hadoop sets this to 1 by default, while Hive uses -1 as the default. When set to -1, Hive will automatically determine an appropriate number of reducers for each job. </description> </property> <property> <name>hive.exec.reducers.max</name> <value>999</value> <description>Max number of reducers to use. If the configuration parameter Hive Reduce Tasks is negative, Hive will limit the number of reducers to the value of this parameter. </description> </property> <property> <name>hive.auto.convert.join</name> <value>true</value> <description>Enable optimization that converts common join into MapJoin based on input file size.</description> </property> <property> <name>hive.auto.convert.join.noconditionaltask.size</name> <value>20971520</value> <description>If Hive auto convert join is on, and the sum of the size for n-1 of the tables/partitions for a n-way join is smaller than the specified size, the join is directly converted to a MapJoin (there is no conditional task) </description> </property> <!-- <property> <name>hive.optimize.index.filter</name> <value>true</value> </property> --> <!-- hive.vectorized.execution--> <!-- <property> <name>hive.vectorized.groupby.checkinterval</name> <value>4096</value> </property> <property> <name>hive.vectorized.groupby.flush.percent</name> <value>0.1</value> </property> <property> <name>hive.vectorized.execution.enabled</name> <value>true</value> </property> <property> <name>hive.vectorized.execution.reduce.enabled</name> <value>false</value> </property> --> <property> <name>hive.optimize.bucketmapjoin.sortedmerge</name> <value>false</value> <description>Whether to try sorted merge bucket (SMB) join</description> </property> <property> <name>hive.smbjoin.cache.rows</name> <value>10000</value> <description>The number of rows with the same key value to be cached in memory per SMB-joined table</description> </property> <property> <name>hive.fetch.task.conversion</name> <value>minimal</value> <description> Some select queries can be converted to a single FETCH task instead of a MapReduce task, minimizing latency. A value of none disables all conversion, minimal converts simple queries such as SELECT * and filter on partition columns, and more converts SELECT queries including FILTERS </description> </property> <property> <name>hive.fetch.task.conversion.threshold</name> <value>268435456</value> <description>Above this size, queries are converted to fetch tasks</description> </property> <property> <name>hive.limit.pushdown.memory.usage</name> <value>0.4</value> <description> The maximum percentage of heap to be used for hash in ReduceSink operator for Top-K selection. 0 means the optimization is disabled. Accepted values are between 0 and 1 </description> </property> <property> <name>hive.optimize.reducededuplication</name> <value>true</value> <description>Remove extra map-reduce jobs if the data is already clustered by the same key, eliminating the need to repartition the dataset again</description> </property> <property> <name>hive.optimize.reducededuplication.min.reducer</name> <value>4</value> <description>When the number of ReduceSink operators after merging is less than this number, the ReduceDeDuplication optimization will be disabled.</description> </property> <property> <name>hive.map.aggr</name> <value>true</value> <description> Enable map-side partial aggregation, which cause the mapper to generate fewer rows. This reduces the data to be sorted and distributed to reducers. </description> </property> <property> <name>hive.map.aggr.hash.percentmemory</name> <value>0.5</value> <description> Portion of total memory used in map-side partial aggregation. When exceeded, the partially aggregated results will be flushed from the map task to the reducers. </description> </property> <property> <name>hive.optimize.sort.dynamic.partition</name> <value>false</value> <description>When dynamic partition is enabled, reducers keep only one record writer at all times, which lowers the memory pressure on reducers</description> </property> <property> <name>hive.mv.files.thread</name> <value>15</value> <description> The number of threads used by HiveServer2 to move data from the staging directory to another location (typically to the final table location). A separate thread pool of workers of this size is used for each query, which means this configuration can be set on a per-query basis too </description> </property> <property> <name>hive.blobstore.use.blobstore.as.scratchdir</name> <value>false</value> <description> When writing data to a table on a blobstore (such as S3), whether or not the blobstore should be used to store intermediate data during Hive query execution. Setting this to true can degrade performance for queries that spawn multiple MR / Spark jobs, but is useful for queries whose intermediate data cannot fit in the allocated HDFS cluster. </description> </property> <property> <name>hive.load.dynamic.partitions.thread</name> <value>15</value> <description> Number of threads used to load dynamically generated partitions. Loading requires renaming the file its final location, and updating some metadata about the new partition. Increasing this can improve performance when there are a lot of partitions dynamically generated. </description> </property> <property> <name>hive.exec.input.listing.max.threads</name> <value>15</value> <description> Maximum number of threads that Hive uses to list input files. Increasing this value can improve performance when there are a lot of partitions being read, or when running on blobstores </description> </property> <!--beeline user name and password, this configuration is optional, default is empty--> <!-- <property> <name>hive.server2.thrift.client.user</name> <value>hadoop</value> <description>Username to use against thrift client</description> </property> <property> <name>hive.server2.thrift.client.password</name> <value>hadoop</value> <description>Password to use against thrift client</description> </property> --> <!--spark settings--> <property> <name>spark.executor.memory</name> <value>4294967296</value> <description>Maximum size of each Spark executor's Java heap memory when Hive is running on Spark</description> </property> <property> <name>spark.yarn.executor.memoryOverhead</name> <value>4096</value> <description> This is the amount of extra off-heap memory that can be requested from YARN, per executor process. This, together with spark.executor.memory, is the total memory that YARN can use to create JVM for an executor process </description> </property> <property> <name>spark.executor.cores</name> <value>4</value> <description>Number of cores per Spark executor.</description> </property> <property> <name>spark.driver.memory</name> <value>8589934592</value> <description>Maximum size of each Spark driver's Java heap memory when Hive is running on Spark.</description> </property> <property> <name>spark.yarn.driver.memoryOverhead</name> <value>4096</value> <description> This is the amount of extra off-heap memory that can be requested from YARN, per driver. This, together with spark.driver.memory, is the total memory that YARN can use to create JVM for a driver process </description> </property> <property> <name>spark.dynamicAllocation.enabled</name> <value>true</value> <description>When enabled, Spark will add and remove executors dynamically to Hive jobs. This is done based on the workload</description> </property> <property> <name>spark.dynamicAllocation.initialExecutors</name> <value>1</value> <description> Initial number of executors used by the application at any given time. This is required if the dynamic executor allocation feature is enabled. </description> </property> <property> <name>spark.dynamicAllocation.minExecutors</name> <value>1</value> <description>Lower bound on the number of executors used by the application at any given time. This is used by dynamic executor allocation</description> </property> <property> <name>spark.dynamicAllocation.maxExecutors</name> <value>8</value> <description>Upper bound on the number of executors used by the application at any given time. This is used by dynamic executor allocation</description> </property> <property> <name>spark.shuffle.service.enabled</name> <value>true</value> <description>enable spark External shuffle Service.</description> </property> <!--merge small files--> <property> <name>hive.merge.mapfiles</name> <value>true</value> <description> Merge small files at the end of a map-only job. When enabled, a map-only job is created to merge the files in the destination table/partitions </description> </property> <property> <name>hive.merge.mapredfiles</name> <value>true</value> <description> Merge small files at the end of a map-reduce job. When enabled, a map-only job is created to merge the files in the destination table/partitions </description> </property> <property> <name>hive.merge.sparkfiles</name> <value>true</value> <description> Merge small files at the end of a Spark job. When enabled, a map-only job is created to merge the files in the destination table/partitions </description> </property> <property> <name>hive.merge.smallfiles.avgsize</name> <value>167772160</value> <description> When the average output file size of a job is less than the value of this property, Hive will start an additional map-only job to merge the output files into bigger files. This is only done for map-only jobs if hive.merge.mapfiles is true, for map-reduce jobs if hive.merge.mapredfiles is true, and for Spark jobs if hive.merge.sparkfiles is true </description> </property> <property> <name>hive.merge.size.per.task</name> <value>268435456</value> <description>The desired file size after merging. This should be larger than hive.merge.smallfiles.avgsize</description> </property> <property> <name>hive.exec.reducers.bytes.per.reducer</name> <value>268435456</value> <description>Size per reducer. If the input size is 10GiB and this is set to 1GiB, Hive will use 10 reducers</description> </property> <property> <name>hive.exec.copyfile.maxsize</name> <value>33554432</value> <description>Smaller than this size, Hive uses a single-threaded copy; larger than this size, Hive uses DistCp</description> </property> <!--cbo optimization--> <property> <name>hive.cbo.enable</name> <value>true</value> <description>Enabled the Calcite-based Cost-Based Optimizer for HiveServer2</description> </property> <property> <name>hive.stats.fetch.column.stats</name> <value>true</value> <description>Whether column stats for a table are fetched during explain</description> </property> <property> <name>hive.compute.query.using.stats</name> <value>true</value> <description> Enable optimization that checks if a query can be answered using statistics. If so, answers the query using only statistics stored in metastore </description> </property> <property> <name>hive.stats.fetch.partition.stats</name> <value>true</value> <description> hive.stats.fetch.partition.stats如果没有可用的统计信息或hive.stats.fetch.partition.stats = false,则查询启动可能会稍慢。在这种情况下,Hive最终会为每个要访问的文件查看文件大小,调整hive.metastore.fshandler.threads有助于减少Metastore操作所需的总时间 </description> </property> <property> <name>hive.stats.autogather</name> <value>true</value> <description>auto collect statistics when using insert overwrite command,default true</description> </property> <property> <name>hive.stats.collect.rawdatasize</name> <value>true</value> <description>auto collect raw data size statistics when using insert overwrite command</description> </property> <!--hive server2 metrics--> <property> <name>hive.service.metrics.file.location</name> <value>/home/lenmom/workspace/software/apache-hive-2.3.4-bin/logs/metrics.log</value> <description></description> </property> <property> <name>hive.server2.metrics.enabled</name> <value>true</value> <description></description> </property> <property> <name>hive.service.metrics.file.frequency</name> <value>30000</value> <description></description> </property> <!--hive permmission settings--> <property> <name>hive.security.authorization.createtable.owner.grants</name> <value>ALL</value> <description></description> </property> <property> <name>hive.security.authorization.task.factory</name> <value>org.apache.hadoop.hive.ql.parse.authorization.HiveAuthorizationTaskFactoryImpl</value> <description></description> </property> <property> <name>hive.users.in.admin.role</name> <value>hive</value> <description></description> </property> <property> <name>hive.security.authorization.createtable.user.grants</name> <value>lenmom,hive,admin:ALL;test:select</value> <description></description> </property> <property> <name>hive.security.authorization.createtable.role.grants </name> <value>data:ALL;test:select</value> <description></description> </property> <property> <name>hive.security.authorization.createtable.group.grants</name> <value>data:ALL;test:select</value> <description></description> </property> <!--Table Lock Manager:Required--> <property> <name>hive.support.concurrency</name> <value>true</value> <description>Enable Hive's Table Lock Manager Service</description> </property> <property> <name>hive.server2.support.dynamic.service.discovery</name> <value>true</value> <description></description> </property> <property> <name>hive.server2.zookeeper.namespace</name> <value>hiveserver2</value> <description>The parent node in ZooKeeper used by HiveServer2 when supporting dynamic service discovery.</description> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> <description>The port at which the clients will connect.If ZooKeeper is not using the default value(2181) for ClientPort, you need to set hive.zookeeper.client.port </description> </property> <property> <name>hive.zookeeper.quorum</name> <value>127.0.0.1:2181</value> <description> Zookeeper quorum used by Hive's Table Lock Manager, a list of hosts seperated with comma,if the zk port number is 2181,then this can be ommited. </description> </property> <!--transaction comfiguration--> <property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value> <description></description> </property> <property> <name>hive.exec.dynamic.partition</name> <value>true</value> <description></description> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> <description></description> </property> <property> <name>hive.compactor.initiator.on</name> <value>true</value> <description></description> </property> <property> <name>hive.compactor.worker.threads</name> <value>1</value> <description> thrift metastore上运行的工作线程数.为了支持事务,必须设置该值为一个正整数.增加该值会减少表 或分区在压缩时需要的时间,但同时会增加hadoop集群的后台负载,因为会有更多的MR作业在后台运行 </description> </property> <property> <name>hive.enforce.bucketing</name> <value>true</value> <description> hive2.x以下版本默认为false,hive2.x版本已经将该属性移除,也就是说永远为true.为了支持 insert,update,delete操作,必须设置该属性为true。如果部署版本为hive2.x版本,可以不设置该值。 </description> </property> </configuration>
其中最后那部分
<!--transaction comfiguration--> <property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value> </property> <property> <name>hive.exec.dynamic.partition</name> <value>true</value> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property> <property> <name>hive.compactor.initiator.on</name> <value>true</value> </property> <property> <name>hive.compactor.worker.threads</name> <value>1</value> <description> thrift metastore上运行的工作线程数.为了支持事务,必须设置该值为一个正整数.增加该值会减少表 或分区在压缩时需要的时间,但同时会增加hadoop集群的后台负载,因为会有更多的MR作业在后台运行 </description> </property> <property> <name>hive.enforce.bucketing</name> <value>true</value> <description> hive2.x以下版本默认为false,hive2.x版本已经将该属性移除,也就是说永远为true.为了支持 insert,update,delete操作,必须设置该属性为true。如果部署版本为hive2.x版本,可以不设置该值。 </description> </property>
是为了让hive支持事务,即行级更新.
or you can use the following script in hive hql script to enable transaction:
set hive.support.concurrency=true; set hive.enforce.bucketing=true; set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; set hive.compactor.initiator.on=true; set hive.compactor.worker.threads=2;
此外,如果要支持行级更新,还要在hive元数据库中执行一下sql语句
use hive; truncate table hive.NEXT_LOCK_ID; truncate table hive.NEXT_COMPACTION_QUEUE_ID; truncate table hive.NEXT_TXN_ID; insert into hive.NEXT_LOCK_ID values(1); insert into hive.NEXT_COMPACTION_QUEUE_ID values(1); insert into hive.NEXT_TXN_ID values(1); commit;
默认情况下,这几张表的数据为空.如果不添加数据,会报以下错误:
org.apache.hadoop.hive.ql.lockmgr.DbTxnManager FAILED: Error in acquiring locks: Error communicating with the metastore
配置hive-env.sh
cp /opt/software/apache-hive-2.3.4-bin/conf/hive-env.sh.template /opt/software/apache-hive-2.3.4-bin/conf/hive-env.sh
sudo vim /opt/software/apache-hive-2.3.4-bin/conf/hive-env.sh
添加以下配置:
export HADOOP_HEAPSIZE=1024 HADOOP_HOME=/opt/software/hadoop-2.7.3/ #这里设置成自己的hadoop路径 export HIVE_CONF_DIR=/opt/software/apache-hive-2.3.4-bin/conf/ export HIVE_AUX_JARS_PATH=/opt/software/apache-hive-2.3.4-bin/lib/ export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
5. 安装mysql数据库
具体请参见本人的博文《ubuntu18.04 安装mysql server》
6. 下载mysql-connector-java-8.0.11.jar或者到mysql官方网站下载
cp mysql-connector-java-8.0.11.jar $HIVE_HOME/lib/
7. 创建并初始化hive mysql元数据库
mysql -uroot -proot mysql> create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci; #在mysql中创建hive数据库 Query OK, 1 row affected, 2 warnings (0.11 sec) mysql> create user 'hive' identified by 'hive'; #创建hive用户,密码为hive Query OK, 0 rows affected (0.03 sec) mysql> grant all privileges on *.* to 'hive' with grant option; #授权hive用户的权限 Query OK, 0 rows affected (0.11 sec) mysql> flush privileges; #刷新权限 Query OK, 0 rows affected (0.01 sec) mysql> exit
如果是mysql5.7以下版本,设置远程访问,授权,则使用以下语句:
grant all privileges on *.* to hive@'%'identified by 'hive'; #授权hive用户远程访问 flush privileges; #应用授权设置
初始化hive元数据库:
$HIVE_HOME/bin/schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/lenmom/workspace/software/apache-hive-2.3.4-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/lenmom/workspace/software/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://127.0.0.1:3306/hive?characterEncoding=UTF8&useSSL=false&createDatabaseIfNotExist=true Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: hive Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary. Starting metastore schema initialization to 2.3.0 Initialization script hive-schema-2.3.0.mysql.sql Initialization script completed schemaTool completed
note: we can also use the following script to initialize the hive database:
$HIVE_HOME/bin/schematool -initSchemaTo 2.3.0 -dbType mysql -verbose
which the -initSchemaTo specifies the hive database schema version it initializes. and this will be persistent in the table

use there is already exists a hive metastore exists with lower version, we can the following script to upgrade the metastore database:
$ schematool -dbType mysql -passWord hive -upgradeSchemaFrom 0.13.1 -userName hive Metastore connection URL: jdbc:mysql://127.0.0.1:3306/hive?useUnicode=true&characterEncoding=UTF-8 Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: hive Starting upgrade metastore schema from version 0.13.1 to 2.3.4 Upgrade script upgrade-0.13.1-to-<new_version>.mysql.sql Completed pre-0-upgrade-0.13.1-to-<new_version>.mysql.sql Completed upgrade-0.13.1-to-<new_version>.mysql.sql schemaTool completed
执行该命令会自动读取hive配置文件中的连接信息,在mysql的hive库中创建表结构和数据的初始化
8. 先启动Hadoop,然后进入hive的lib目录,使用hive 命令 启动hive
在hdfs中建立hive文件夹
hdfs dfs -mkdir -p /tmp hdfs dfs -mkdir -p /usr/hive/warehouse hdfs dfs -chmod g+w /tmp hdfs dfs -chmod g+w /usr/hive/warehouse
启动hadoop
start-dfs.sh #启动hdfs start-yarn.sh #启动yarn #或者,但是一般不建议全部启动,除非你的机器配置特别强 start-all.sh #全部启动
启动hive meta service
在默认的情况下,metastore和hive服务运行在同一个进程中,使用这个服务,可以让metastore作为一个单独的进程运行,我们可以通过METASTOE——PORT来指定监听的端口号, 默认端口为9083
hive --service metastore &

启动hiveservice2服务
Hive以提供Thrift服务的服务器形式来运行,可以允许许多个不同语言编写的客户端进行通信,使用需要启动HiveServer服务以和客户端联系,我们可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口,在默认情况下,端口号为10000,这个可以通过以下方式来启动Hiverserver:
bin/hive --service hiveserver2 -p 10002
其中-p参数也是用来指定监听端口的,启动后,用java,python等编程语言可以通过jdbc等驱动的访问hive的服务了,适合编程模式。HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供更好的支持。
hiveserver2
#或者
hive --service hiveserver2 & #最后的&表示在后台运行 thrift端口号默认为10000, web http://{hive server ip address}:10002/ 访问

启动hive web界面启动方式
hive –service hwi & #用于通过浏览器来访问hive,浏览器访问地址是:http://{hive server ip address}:9999/hwi
注意:这个需要使用到web的war包,需要通过源码编译,这个服务是可选的,可以不需要启动,但是metastore是必须要启动的。具体操作为
a) 下载对应的src tar包
b) cd ${HIVE_SRC_HOME}/hwi/web
c) 打包 jar -cvf hive-hwi-2.3.4.war *
d) cp hive-hwi-2.3.4.war ${HIVE_HOME}/lib
在${HIVE_HOME}/conf/hive-site.xml下添加以下配置
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.3.4.war</value>
<description>This sets the path to the HWI war file, relative to ${HIVE_HOME}. </description>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>192.168.1.254</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
启动hive客户端
hive

9. 如果遇到错误,可以打开hive日志调试模式
hive --hiveconf hive.root.logger=DEBUG,console
10 其他机器如果需要使用hive
安装hive客户端,可参照以下操作
scp -r /opt/software/apache-hive-2.3.4-bin root@lenmom11:/opt/software/ #复制前面安装的hive到目标机器 # /etc/profile中添加hive的环境变量 #hive export HIVE_HOME=/opt/software/apache-hive-2.3.4-bin export HIVE_CONF_DIR=$HIVE_HOME/conf export PATH=.:$HIVE_HOME/bin:$PATH #修改hive-site.xml内容为 <?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehouse</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.1.254:9083</value> </property> <property> <name>hive.querylog.location</name> <value>/opt/software/apache-hive-2.3.4-bin/logs</value> </property> </configuration>
如果要使用beeline,出现错误
Error: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous (state=,code=0)
Beeline version 2.1.0 by Apache Hive
分析 : 访问权限问题
解决 :在hdfs 的配置文件core-site.xml中加入如下配置,root 为位置填入 User:* ,etc hadoop.proxyuser.eamon.hosts
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加以下配置
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
reference: