一、RabbitMQ概述
RabbitMQ是一种消息队列,是一个公共的消息中间件,用于不同进程之间的通讯。
除了RabbitMQ以外,还有ZeroMQ、ActiveMQ等等。
前面学习了两种队列:
- 线程 QUEUE:只能用于线程间通信,不能跨进程。
- 进程 QUEUE:只能用于父进程与子进程之间通信,或同属于同一父进程下的多个子进程之间。两个完全独立的python程序是无法通过这种队列通讯的。
RabbitMQ是用erlang语言开发的,依赖于erlang。在Windows上安装RabbitMQ需要安装erlang环境。
RabbitMQ支持多种语言接口,Python主要使用pika来对其进行操作,pika是一个纯Python的AMQP客户端。

安装RabbitMQ步骤:
- erlang下载地址:http://www.erlang.org/downloads 安装
- RabbitMQ下载地址:http://www.rabbitmq.com/install-windows.html 安装
- 在python中安装pika(pycharm中)
二、RabbitMQ架构
RabbitMQ由于需要同时为多个应用服务,其中维护的队列不止一个。
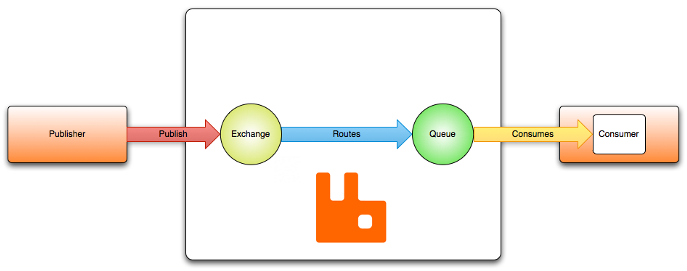
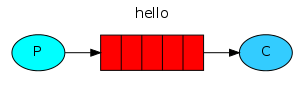
上图是一个典型的生产者消费者模型,中间是RabbitMQ消息队列,他由Exchange和Queue组成。消息队列服务实体又叫broker(即中间方块部分)。
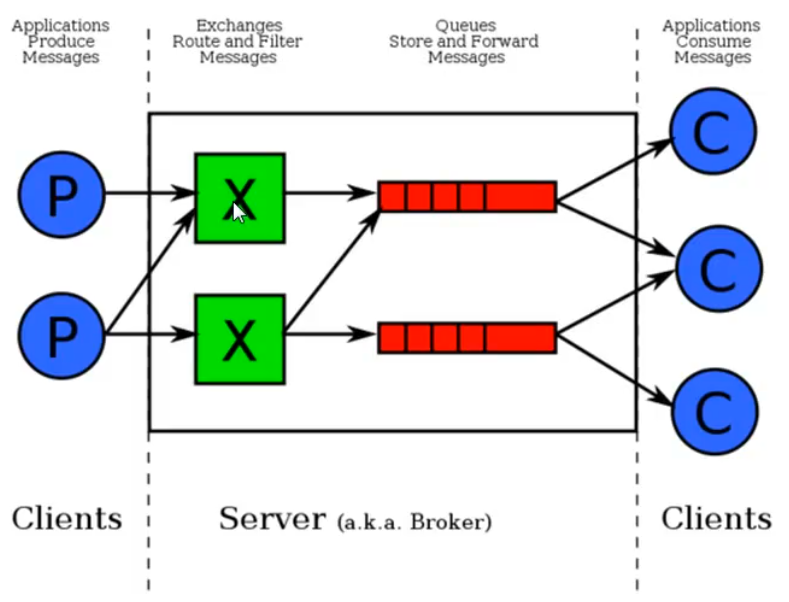
图中,红色部分就是多个队列。绿色部分是Exchange。
RabbitMQ默认端口:
Client端通讯口:5672
后台管理口:15672 http://localhost:15672
server间内部通讯口:25672
新安装好的RabbitMQ无法登录后台管理界面:
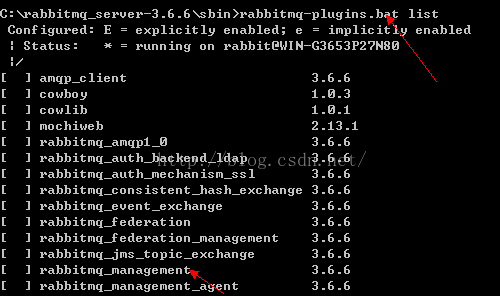
- 在cmd窗口下进入rabbitmq安装目录下的sbin目录,使用rabbitmq-plugins.bat list查看已安装的插件列表。
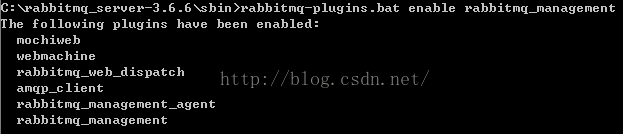
- 使用rabbitmq-plugins.bat enable rabbitmq_management开启网页管理界面
- 重启rabbitmq。
- 在浏览器中输入http://127.0.0.1:15672/
- 输入用户名和密码(默认为guest)

三、最简单的使用
生产者:
import pika # 建立一个socket链接 conn = pika.BlockingConnection( pika.ConnectionParameters('localhost') ) # 声明一个管道 channel = conn.channel() # 定义一个queue channel.queue_declare(queue='hello') # 通过管道发送数据到队列hello中 channel.basic_publish(exchange='', routing_key='hello', # queue的名字 body='Hello World!!') # 内容 print('[X] Sent "Hello World!!"') conn.close() # 关闭链接
消费者:
import pika conn = pika.BlockingConnection( # 如果消费者在其他机器上,这里的localhost需要修改为server的IP地址 pika.ConnectionParameters('localhost') ) channel = conn.channel() # 为什么还要在这里声明queue,因为我们不确定在这之前是否已经有produce声明了queue # 如果能确定已经存在queue,那就不用声明了 channel.queue_declare(queue='hello') # 参数ch是管道对象内存地址,method是消息要发给谁的信息 def callback(ch, method, properties, body): print('[x] Received %r' % body) # 从hello队列中中获取消息 channel.basic_consume( callback, # 如果收到消息就调用这个函数来处理消息 queue='hello', # 指定队列名称 no_ack=True # 是否向服务器确认消息处理完毕,见后述详解no_ack ) print('[*] Waiting for messages.To exit press CTRL+C') # 开始接收,一直接收,没有就卡住 channel.start_consuming()
在这种模式下,如果一个生产者对应多个消费者(即启动多个消费者),此时队列中的消息是以轮训的方式发送给每个消费者的(类似负载均衡)。
no_ack:
消费者受到消息后,需要一定的时间来处理消息,使用no_ack=True表示不管处理完还是没有处理完,都不会给服务端发确认。这种情况下,服务端不会管消费者是否处理完消息就直接将消息从队列中删除了。
如果要让消费者在处理完后给服务端发送确认消息后,再从队列中删除(如果未处理完就断掉了,那么就将消息给另外一个活动的消费者处理),那么就不要使用no_ack=True这个参数,并且在callback方法中添加下面代码:
ch.basic_ack(delivery_tag=method.delivery_tag)
如下代码:
# 参数ch是管道对象内存地址,method是消息要发给谁的信息 def callback(ch, method, properties, body): print('[x] Received %r' % body) # 处理完毕后回应服务端 ch.basic_ack(delivery_tag=method.delivery_tag) # 从hello队列中中获取消息 channel.basic_consume( callback, # 如果收到消息就调用这个函数来处理消息 queue='hello1', # 指定队列名称 )
四、持久化
在RabbitMQ服务重启后,队列和里面的消息都会丢失。
如何持久化队列:
# 定义一个queue,并持久化 channel.queue_declare(queue='hello', durable=True)
使用durable=Ture来持久化queue(客户端和服务器端都得写)。但是queue中的数据还是会丢失!
如何持久化队列中的消息:
# 通过管道发送数据到队列hello中,并持久化 channel.basic_publish(exchange='', routing_key='hello1', # queue的名字 body='Hello World!!', # 内容 # 持久化队列中的消息 properties=pika.BasicProperties(delivery_mode=2) )
持久化队列中消息,如上述代码中,添加properties=pika.BasicProperties(delivery_mode=2)。
注意:消息持久化的delivery_mode必须搭配队列持久化durable使用,否则队列都不持久化,里面的消息会丢失。
Windows命令行查看queue:

五、Exchange转发器
Exchange在定义时要指定类型,以决定哪些queue符合条件,可以接受消息。可以存在多个exchange。
四种类型:
fanout:所有bind到此exchange的queue都可以接受到消息。
direct:通过routingKey和exchange决定的那个唯一的queue可以接受消息。(完全匹配)
topic:所有符合routingKey(可以是一个表达式)所bind的queue可以接受消息。(模糊匹配)
header:通过headers来决定把消息发给哪些queue。
Fanout:广播
生产者:
import pika conn = pika.BlockingConnection( pika.ConnectionParameters(host='localhost') ) channel = conn.channel() # 只需定义exchange,无需定义queue了 channel.exchange_declare( exchange='logs1', # 定义exchange名称 exchange_type='fanout', # exchange类型,这里为广播 durable=True # 持久化exchange ) message = "Hello World!!" channel.basic_publish( exchange='logs', # exchange的名称 routing_key='', # 以前这里写的是queue的名字,现在指定为空 body=message # 发送的消息 ) print('[X] Sent %r' % message) conn.close()
消费者:
import pika conn = pika.BlockingConnection( pika.ConnectionParameters(host='localhost') ) channel = conn.channel() channel.exchange_declare(exchange='logs', exchange_type='fanout', durable=True # 和生产者一致,需要持久化 ) res = channel.queue_declare(exclusive=True) # 自动生成一个队列名称(唯一的名称),并在此queue的消费者断开后,自动销毁queue queue_name = res.method.queue # 获取自动生成的队列名例如amq.gen-55TO5iqNph0I5MmG5GlKuA # 将定义好的queue绑定到exchange上 channel.queue_bind(exchange='logs', queue=queue_name ) print('[X] Waiting for logs. To exit press CTRL+C') # 回调函数 def callback(ch, methos, properties, body): print('[X] %r' % body) # 接收消息 channel.basic_consume(callback, queue=queue_name, # 指定队列名 no_ack=True # 无响应,也可以使用主动通知的形式 ) channel.start_consuming() # 开始监听消息
注意:channel.queue_declare(exclusive=True)中的exclusive=True会自动生成一个唯一的队列名,并在该队列的消费者断开后,自动销毁该queue。这里为什么要用这种形式,是因为我们这里的队列只用于接收这个fanout广播消息,接收完不需要这个queue了就可以删除了,如果还需要接收其他exchange的消息,那可能就需要自己去指定名称了。
注意注意:fanout模式,在exchange接收到生产者的消息后,只会发给当前已绑定的queues,分发给所有的queue后,消息就删除了。所以在生产者发送消息后再绑定到exchange的消费者队列是无法接受到这条消息的。
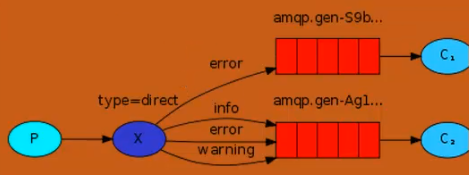
direct:
生产者:
import pika conn = pika.BlockingConnection( pika.ConnectionParameters(host='localhost') ) channel = conn.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct' # 转发类型为direct(完全匹配) ) severity = 'error' # 发送级别为error,用于(完全)匹配 message = 'Hello World!' channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message ) print('[X] Sent %r:%r' % (severity, message)) conn.close()
消费者:
import pika conn = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = conn.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct' ) res = channel.queue_declare(exclusive=True) # 随机生成一个queue_name(自动销毁) queue_name = res.method.queue # 获取随机名 severities = ['info', 'warning', 'error'] # 接收三个级别的匹配字符 # 利用for循环,为同一个queue绑定3个级别的消息(即3个匹配字符) for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity ) print('[*] Waiting for logs.To exit press CTRL+C') def callback(ch, method, properties, body): print('[X] %r:%r' % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True ) channel.start_consuming()
direct模式,就是使用routing_key来区分将消息发给哪个队列,需要接收的队列必须使用routing_key来绑定到exchange上。发消息必须制定routing_key,从而exchange才能根据这个值来进行转发。direct是完全匹配的模式,一个字符都不能差。
topic:
topic与direct的使用方法很相似,在生产者中没什么不同,而在消费者中,topic是将一个匹配的表达式(类似正则表达式)和queue绑定到一个exchange中,这样,只要生产者产生的消息能够匹配这个表达式,exchange就会把这个消息发送给匹配上的queue。
生产者:
import pika conn = pika.BlockingConnection( pika.ConnectionParameters(host='localhost') ) channel = conn.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic' # 转发类型为direct(完全匹配) ) severity = 'Leo.warning' # 发送一个应用+级别的消息 message = 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=severity, body=message ) print('[X] Sent %r:%r' % (severity, message)) conn.close()
消费者:
import pika conn = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = conn.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic' ) res = channel.queue_declare(exclusive=True) # 随机生成一个queue_name(自动销毁) queue_name = res.method.queue # 获取随机名 severity = '*.warning' # 匹配一个级别的任何应用发来的消息,是一个类似于正则的表达式 channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=severity ) print('[*] Waiting for logs.To exit press CTRL+C') def callback(ch, method, properties, body): print('[X] %r:%r' % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True ) channel.start_consuming()
topic的匹配表达式:
"#":匹配0-N个单词(单词由字母和数字组成)。
"*":匹配0-1个单词。
中间只能用“.”来间隔。例如 “ *.info.* ”, " #.warning.* "
注意:在消费者的代码中queue_bind函数的参数中routing_key中"*"和"."和"#"都代表着匹配字符。而在生产者的basic_publish函数的参数中routing_key中字符串如果出现"*"、"."和"#",都代表一个普通字符。
六、RabbitMQ实现RPC(简单版,无exchange部分)
RPC:remote procedure call 远程过程调用,即客户端发送一条命令,服务端执行方法调用,并返回结果。
RabbitMQ中实现RPC思路:
生产者--->rpc_Queue--->消费者
消费者<---res_Queue<---生产者
通过两个队列,来互相传递命令和执行结果。
客户端代码:(发送调用命令)
import pika import time import uuid class FibonacciRpcClient(object): def __init__(self): # 链接RabbitMQ self.connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost') ) self.channel = self.connection.channel() # 随机生成一个队列 result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue # 获取队列名称 # 定义一个消费者,回调函数是on_response(),消息队列名称是callback_queue self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue) # 消费者回调函数 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body # 发送消息(命令),并接受响应 def call(self, n): # 定义self.response为空 self.response = None # 生成一个uuid,对应一个命令 self.corr_id = str(uuid.uuid4()) # 发送消息,队列名为rpc_queue,将响应队列和uuid一并发送给服务端,队列名为 # callback_queue,uuid为corr_id,body为消息体 self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id ), body=str(n) ) # 消息发送完毕后,循环调用非阻塞模式的start_consuming() # 即connection.process_data_events() # 当没收到相应时,返回并继续循环。 # 当有响应时会调用on_response,在on_response中将self.response设置为body,跳出循环 while self.response is None: self.connection.process_data_events() # 每隔一秒检查一下是否有响应到达 time.sleep(1) # 返回响应结果 return int(self.response) fibonacci_rpc = FibonacciRpcClient() response = fibonacci_rpc.call(3) print('[.] Got %r' % response)
服务端代码:(处理命令,返回调用结果)
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fibonacci(n): if n == 0: return 0 elif n == 1: return 1 else: return fibonacci(n-1) + fibonacci(n-2) # 定义一个回调函数,用来处理命令 def on_request(ch, method, props, body): n = int(body) print('[.] fib(%s)' % n) # 执行调用的函数,或去响应内容 response = fibonacci(n) # 将响应内容发送回去,队列为客户端发过来的props.reply_to ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id=props.correlation_id), body=str(response) ) # 通知客户端,这个命令已经执行完毕 ch.basic_ack(delivery_tag=method.delivery_tag) # 从rpc_queue中接收消息 channel.basic_consume(on_request, queue='rpc_queue') print('[x] Awaiting RPC requests') # 开始接收消息 channel.start_consuming()
上述代码主要完成了RPC调用的基本功能,其中函数一个客户端(发起RPC调用)和一个服务端(处理RPC调用)。
在客户端代码中,关键点在于在发送消息的同时,将响应返回需要使用的队列也一并定义并将名称发送给了服务端(还包含区分消息和相应批次的uuid)。在发送完消息后,进入循环获取响应的阶段。
在服务端代码中,关键点在于接收到消息后,在回调函数中调用处理函数fibonacci(),并将运行结果发送到客户端告知的响应队列中。
七、Redis概述
Redis是一个缓存系统,即第三方实现数据共享,例如QQ和微信要共享一个数据name。QQ和微信都分别使用socket链接到redis,然后实现访问该name数据。
Redis是单线程的,底层应该是使用epoll实现异步处理(不确定)。
Redis安装:
在Linux下采用yum等工具安装,或者源码安装。
1.安装redis前需要安装epel源,yum install epel-release -y
2.安装redis,yum install redis -y
3.启动redis,systemctl start redis.service
4.查看redis是否启动,systemctl status redis.service 或者 ps -ef | grep redis

Redis命令行使用:
使用redis-cli运行redis命令行:

存数据:

读数据:

在Python中调用redis:
首先需要在python中安装redis库,可以使用pycharm安装。或者使用pip install redis,easy_install redis等方法安装。
redis默认使用端口号:6379。
import redis # 链接远程redis服务 r = redis.Redis(host='192.168.1.66', port=6379) r.set('age', '25') # 存入数据 print(r.get('age')) # 读出数据
使用上述代码进行redis链接和操作,如果报错说redis拒绝链接,解决方案如下:
1.修改redis配置文件/etc/redis.conf,将其中的bind 127.0.0.1注释掉。
2.将protected-mode yes修改为protected-mode no。
3.再次链接,即可成功。
Redis连接池:
import redis pool = redis.ConnectionPool(host='192.168.1.66', port=6379) r = redis.Redis(connection_pool=pool) r.set('sex', 'male') print(r.get('sex'))
redis-py使用connection pool来管理一个redis server的所有链接,避免每次建立、释放链接的资源开销。默认,每个redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个链接池。
使用Redis帮助:
在redis-cli中使用命令 help的形式可以查看命令帮助。
八、Redis的String操作
主要有以下一些常用方法:
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis的set函数中,默认不存在则创建,存在则修改。
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,才执行set操作
xx,如果设置为True,则只有name存在时,才执行set操作
setnx(key, value) = set()+nx 一般不使用,直接用set
setex(key, value, time) = set()+ex 一般不使用,直接用set
psetex(key, value, time) = set()+px 一般不使用,直接用set
mset(k1='v1', k2='v2') 批量设置键值 或者 mset({'k1':'v1', 'k2':'v2' })使用字段传入键值对。
mget(k1, k2) 批量获取值 或者 mget([k1, k2]) 使用列表传入keys
getset(key, value) 获取旧值,设置新值
getrange(key, start, end) 获取某个值的其中几个字符,例如值为‘jack’,getrange(key, 0, 2)返回'jac'。
setrange(key, offset, value) 将值从某个位置开始覆盖字符为value,例如值为‘jack’,setrange(key, 1, 'AL'),返回'jALk'。
setbit(key, offset, value) 将某个值的某个二进制位进行修改。例如n1对应的值为foo,foo对应的二进制为01100110 01101111 01101111第7位设置为1,setbit('n1', 7, 1),返回的值变为01100111 01101111 01101111,foo变为goo。
setbit一个使用的场景:例如,新浪微博有10亿用户,我们想统计有哪些用户在线,使用数据库修改状态的方式效率太低。我们可以使用每个用户对应一个编号index,编号对应的二进制位0代表不在线,1代表在线。用户上线就使用setbit(key, index, 1)设置key对应值中的index位为1,下线就setbit(key,index,0)。然后使用bitcount(key)就可以统计值里有多少位为1,就可以知道有多少用户在线。 例如,设置第1亿个用户为在线,setbit(user,100000000,1)。
getbit(key, offset) 获取某个位置的二进制值,例如1为用户在线,0为不在线。
strlen(key) 返回key对应value的字节长度(一个汉字三个字节)。
incr(key, amount=1) 自增,运行一次,key对应的value+1,可以用来处理用户上线统计(incr login_user)

decr(key, amount=1) 自减,运行一次,key对应的value-1,可以用来处理用户下线统计(decr login_user),注意会减为负数。

incrbyfloat(key, amount=1.2) 浮点数自加,类似incr。
decrbyfloat(key, amount=1.2) 浮点数自减,类似decr。
append(key, value) 在key对应的值后面添加value。例如name='alex',append(name,'leo'),返回alexleo。
九、Redis的hash操作
hset(name, key, value) 相当于name中存在多个键值对,例如hset('n2', 'k9', 'v99'),hset('n2', 'kx', 'vx')。

hgetall(name) 返回所有的键值对。
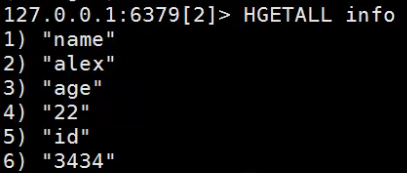
hget(name, key) 获取info中某个key的值,例如 hget('info', 'age')。

hkeys(name) 获取所有name中的key。
hvals(name) 获取所有name中的value。
hmset(name,mapping) 批量设置,例如hmset('info', {'k1':'v1', 'k2':'v2'})
hmget(name, key ...) 批量获取,例如hmget('info', 'k1', 'k2')
hlen(name) 获取name中有几个key-value。例如hlen('info'),返回(integer)2
hexist(name, key) 判断name中是否存在某个键值。
hincrby(name, key, amount=1) 使name中key对应的value自增。
hdecrby(name, key, amount=1) 使name中key对应的value自减。
hincebyfloat(name, key, amount=1.2) 浮点自增。
hscan(name, cursor=0, match=None, count=None) 由于hset可以保存200多亿个key-value,所以使用hkeys来查询很耗性能,所以可以使用hscan进行过滤。例如hscan('info',0,'*e*'),过滤key中带'e'的key-value。
hscan_iter(name, match=None, count=None) 返回一个迭代器,然后使用循环获取key-value。
例如:
for item in r.hscan_iter('info'): print item
十、Redis的list操作

lpush(names, val1, val2...) 往列表中插入数据,如果不存在则创建。lpush是从数据的最前面插入(最左边)。
lrange(names, start, end) 去列表中的一个范围的数据,例如lrange(names, 0, -1)即取names中的所有数据。
rpush(names, val1, val2..) 与lpush相反,rpush是从最后面插入(最右边)。
lpushx(names, value) 只有当names存在时才插入,否则无效。
rpushx(names, value) 类似lpushx。
llen(names) 返回names对应list元素个数。
linsert(names, where, refvalue, value) 在names列表中,refvalue值的前面还是后面插入value。例如linsert(names, BEFORE, 'alex', 'leo'),在names列表的'alex'前插入'leo'。where填写BEFORE和AFTER。
lset(names, index, value) 在names列表中某个index处重新设置值。
lrem(names, value, num) 删除names列表中指定的值,num表示删除的数量(正数为从前到后,负数为从后到前)。例如lrem(names, 'leo', 2)即从前到后删除2个'leo'。
lpop(names) 从names的最前面删除一个元素,并返回。
rpop(names) 从names的最后面删除一个元素,并返回。
lindex(names, index) 从names中根据index获取相应位置的元素。
ltrim(name, start, end) 移除names中start-end下标范围的元素。
rpoplpush(src, dst) 从一个列表的最右边取元素,添加到另一个列表的最左边。
十一、Redis的set(集合)操作
集合就是不允许重复的列表。
sadd(names, val1, val2...) 向names中添加元素,但是不能重复,如果与集合中某个元素重复,则不会插入该元素。
smembers(names) 获取names集合中的所有元素,这些元素都是不重复的。
sdiff(names1, names2...) 获取差集,names1-names2
sdiffstore(res, names1, names2...) 获取names1-names2的结果,并存放到res集合中。
sinter(names1, names2...) 获取多个集合之间的交集。
sinterstore(res, names1, names2...) 获取集合之间的交集,并存放到res集合中。
sismember(names, value) 判断value是否是names集合中的成员。
smove(src, dst, value) 将某个成员从一个集合移动到另外一个集合中。
spop(names) 从集合的右侧移除一个成员,并将其返回。
srandmember(names, num) 从names集合中随机获取num个元素。
srem(names, value...) 在names集合中删除某些值。
sunion(names1, names2...) 多个集合的并集。
sunionstore(res, names1, names2...) 多个集合的并集,并存放res集合中。
sscan(names, cursor=0, match=None, count=None) 和hscan很像,即过滤。
sscan_iter(names, match=None, count=None) 和hscan_iter很像,即返回一个迭代器,然后使用循环获取值。
有序集合:
在集合的基础上,为每个元素排序。元素的排序需要根据另一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(names, s1, val1, s2, val2...) 向有序集合中插入数据,每个数据都有一个分数,用于排序。例如zadd(names,10,'leo',20,'alex')。
zrange(names, start, end, desc=False, withscores=False, score_cast_func=float) 查看有序集合的部分元素,例如zrange(names, 0, -1, withscores=True)查看全部元素(带分数)。
zcard(names) 获取names对应有序集合元素的数量。
zcount(names, min, max) 获取有序集合中分数在[min, max]之间元素的个数。
zincrby(names, value, amount) 自增names有序集合中对应value值元素的分数。
zrank(names, value) 获取有序集合中value对应元素的排行(从0开始,从小到大)。
zrerang(name, value) 与zrank相反,从大到小。
zrem(names, value) 删除names中值为value的元素。
zremrangebyrank(names, min, max) 根据排行范围(相当于index)删除。
zremrangebyscore(names, min, max) 根据分数范围删除。
zscore(names, value) 获取names有序集合中value对应元素的分数。
zinterstore(res, keys, aggregate=None) 获取两个有序集合的交集,如果其中有值相同分数不同的元素,则对其分数进行SUM,MIN,MAX三种操作。
zunionstore(res, keys, aggregate=None) 获取两个有序集合的并集,如果其中有值相同的元素,则对其分数进行SUM,MIN,MAX三种操作。
zscan(name, cursor=0, match=None, count=None,score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作。
十二、其他常用操作
delete(key) 任意删除一个key对应的元素。
exist(key) 查看是否存在key对应的元素。
keys(pattern='*') 根据pattern匹配获取redis中所有的key。
expire(key, time) 为某个元素设置超时时间(秒)。到时间自动删除。
rename(src, dst) 重命名。
move(name, db) 将某个值移动到指定的db下。redis中默认有16个db(相当于表),编号为0-15。每个db中数据都是新的。使用select db_id来切换。
type(key) 获取key对应值的类型。
scan(cursor=0, match=None, count=None) 同字符串操作
scan_iter(match=None, count=None) 同字符串操作
十三、Redis管道(pipline)
使用pipe可以将多个操作黏在一起,变成一个原子操作。
import redis pool = redis.ConnectionPool(host='192.168.1.66', port=6379) r = redis.Redis(host='192.168.1.66', port=6379) pipe = r.pipeline(transaction=True) # 定义一个pipe pipe.set('haha1', 'good') # 加入动作 pipe.set('haha2', 'UP') # 加入动作 pipe.execute() # 开始执行pipe,其中的两个动作是黏在一起的原子操作
十四、发布订阅
使用Redis也可以做到和RabbitMQ类似的广播效果。
首先封装一个RedisHelper:
import redis class RedisHelper(object): def __init__(self): self.__conn = redis.Redis(host='192.168.1.66', port=6379) self.channel_pub = 'fm104.5' # 发布的频道 self.channel_sub = 'fm104.5' # 接收的频道 def publishing(self, msg): self.__conn.publish(self.channel_pub, msg) return True def subscribe(self): sub = self.__conn.pubsub() # 相当于打开收音机 sub.subscribe(self.channel_sub) # 选择频道 sub.parse_response() # 准备接收(再次调用才是正式接收) return sub
创建一个订阅者:
from redishelper import RedisHelper rh = RedisHelper() rh_sub = rh.subscribe() print('打开收音机,调频104.5,开始接收消息:') while True: msg = rh_sub.parse_response() print(msg)
创建一个发布者:
from redishelper import RedisHelper rh = RedisHelper() rh.publishing('Hello World!')
也可以通过redis-cli来发布,使用PUBLISH fm104.5 'Hello World'即可。