文章目录
什么是RDD
RDD(Resilient Distributed Datasets),弹性分布式数据集,是Spark的基本数据结构。
它是一个不可变的分布式对象集合。
RDD中的每个数据集被划分为逻辑分区,其可以在集群的不同节点上计算。
RDD可以包含任何类型的Python,Java或Scala对象,包括用户定义的类。
形式上,RDD是只读的 分区 记录集合。 可以通过读取外部存储系统中的数据集(如HDFS,HBase或提供Hadoop输入格式的任何数据源等)、转换现有数据集合或对其他RDD的数据进行转换来创建RDD。
RDD是一个支持容错集合,可以并行操作。
RDD的主要属性
从RDD的内部定义来看,每个RDD拥有以下五个主要属性:
- 分区列表
- 与其他RDD的依赖关系列表
- 计算分片(split)的函数
- (可选) 键值RDD中的分区器Partitioner (例如,hash-partitioner)
- (可选) 用于计算每个分片的的优选位置列表 (例如,HDFS文件的block位置)
RDD的组成
RDD主要由以下四部分组成
- 分区(Partitions):数据集的原子片段。 每个计算节点含有一个或多个分区。
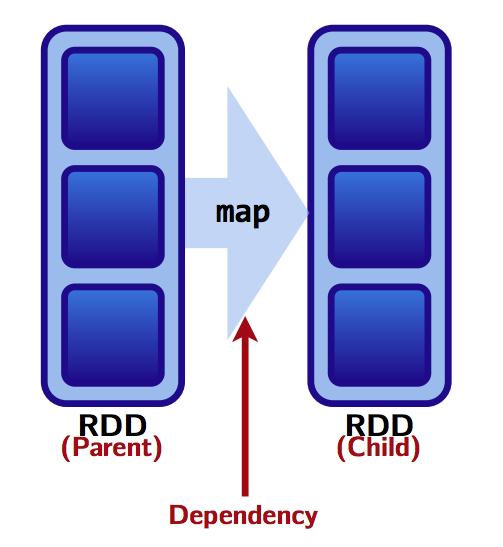
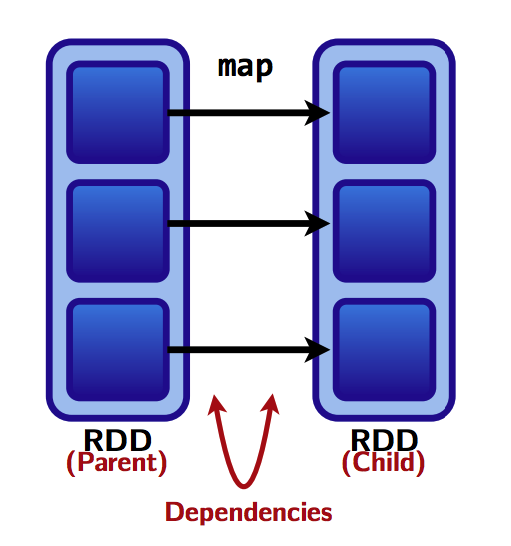
- 依赖关系(Dependencies):RDD的每个分区计算时依赖哪些父RDD的分区(如下图)
- 函数/算子(Functions): 基于其父RDD的用于计算数据集的函数。
- 元数据(Metadata): RDD的分区方案和数据的存储放置。
|
|
RDD的分区(Partition)
RDD中的数据被存储在多个分区中。
RDD分区的特征
- 分区永远不会跨越多台机器,即同一分区中的数据始终保证在同一台机器上。
- 群集中的每个节点包含一个或多个分区。
- 分区的数目是可以设置的。 默认情况下,它等于所有执行程序节点上的核心总数。 例如。 6个工作节点,每个具有4个核心,RDD将被划分为24个分区。
RDD分区与任务执行的关系
在Map阶段partition数目保持不变。
在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
RDD分区数的调整可以通过以下两个函数完成:
- repartition
repartition函数相当于coalesce(numPartitions, shuffle = True), 不仅可以调整分区数目(增加或减少),也可以将partitioner调整为hash-partitioner,产生shuffle操作 - coalesce
coalesce函数可以控制是否shuffle,但是shuffle为False时,只能减少分区数,无法增大。
RDD在计算的时候,每个分区都会启动一个task,RDD的分区数目决定了总的task数目。
申请的Executor数和Executor的CPU核数,决定了你同一时刻可以并行执行的task数量。
这里我们举个例子来加深对RDD分区数量与task执行的关系的理解
比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
partition数量太少会造成资源利用不够充分。
例如,在资源不变的情况,你的RDD只有10个分区,那么同一时刻只有10个task运行,其余10个核将空转。
通常在spark调优中,可以增大RDD分区数目来增大任务并行度。
但是partition数量太多则会造成task过多,task的传输/序列化开销增大,也可能会造成输出过多的(小)文件。
spark.default.parallelism 和 spark.sql.shuffle.partitions 这两个参数很重要
RDD的分区器(Partitioner)
Spark中提供两种分区器:
- 散列分区 Hash partitioning
- 范围分区 Range partitioning
只有PairRDD支持自定义分区器。
RDD的逻辑执行计划(Lineage)
RDD Lineage,又叫做RDD运算符图或RDD依赖图,是包含一个子RDD的所有父RDD的图。每当我们执行RDD转换(transformation)操作,就会产生RDD Lineage并用于创建 逻辑执行计划。
Spark stages的DAG的执行称作 物理执行计划
逻辑执行计划从最初始的RDD (不依赖于其他RDD或引用缓存数据的RDD)开始,以调用可以产生RDD结果的action算子结束。
使用toDebugString函数可以显示RDD Lineage
RDD Lineage是Spark中容错的关键
我们可以通过RDD Lineage,追溯到丢失分区的父RDD,然后根据父RDD重新计算丢失分区,使其从故障中恢复。
RDD的依赖关系(Dependencies)
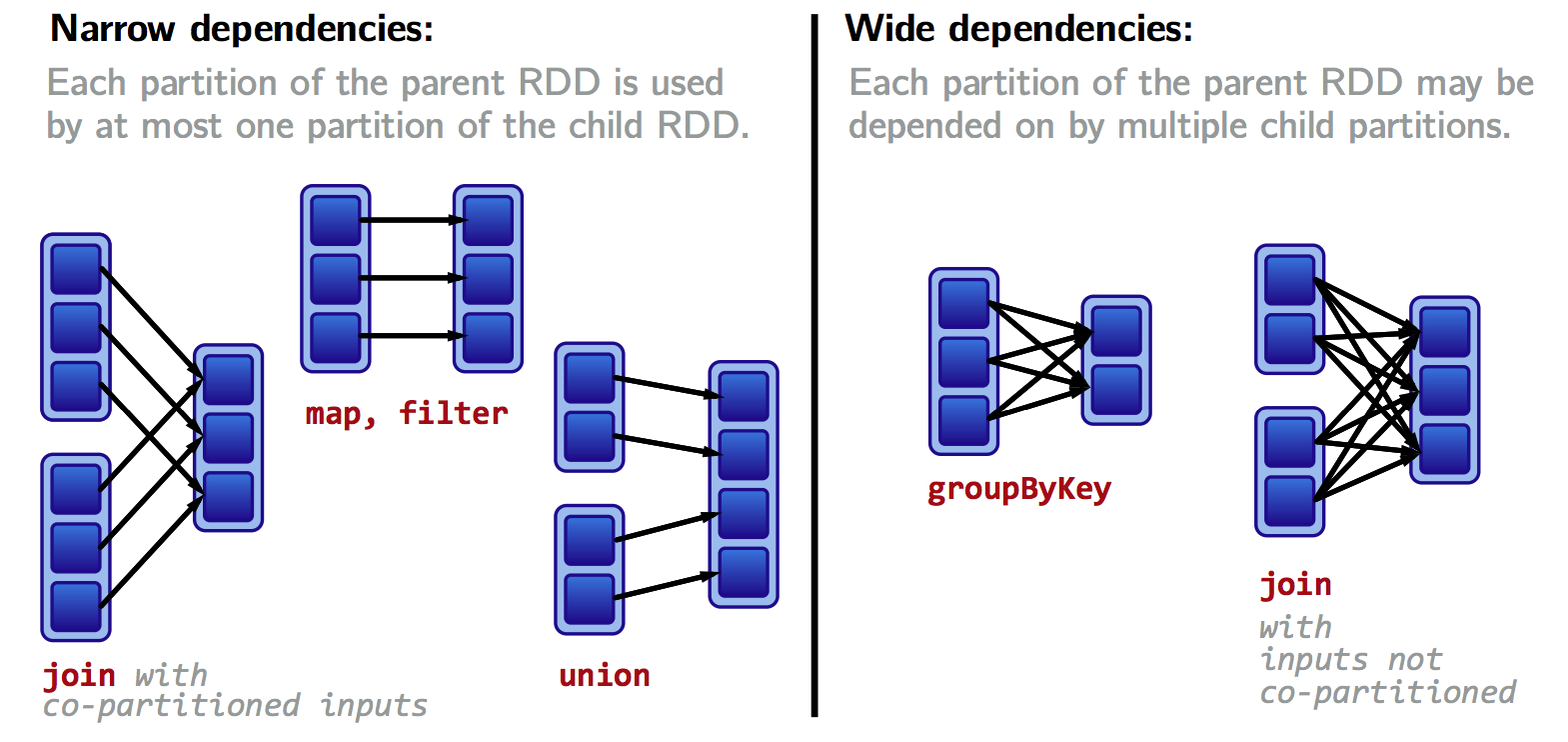
RDD的每一个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;在Spark中,RDD之间存在两种类型的依赖关系:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency);
|
窄依赖(Narrow Dependency)
窄依赖是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;
对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,这种转换不会引起shuffle操作,速度快!
宽依赖(Wide Dependency)
宽依赖是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;
这种转换会引起shuffle操作,速度慢!
Shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
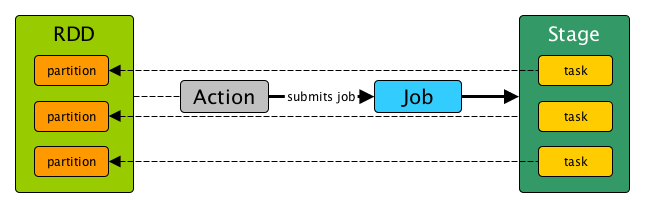
RDD与Task/Stage的关系
Task
Task是Spark中最小的任务执行单元,每个RDD的transformation操作都会被翻译成相应的task,分配到相应的executor节点上对相应的partition执行。
|
RDD在计算的时候,每个分区都会启动一个task,RDD的分区数目决定了总的task数目。
Task的类型分为2种:ShuffleMapTask和ResultTask;
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。
Stage
Stage是程序执行时的物理,是物理执行计划中的一个步骤。
Stage由一组有narrow transformation(无要shuffle)构成的task组成, 不需要在节点间传输数据,可以被高效的执行。
一个Stage只能在单个RDD的分区上工作。
Stage的类型分为2种:
- ShuffleMapStage
- ResultStage
参考来源:
Wide vs Narrow Dependencies
Mastering Apache Spark
Partitioning
spark学习之RDD来源解密