变量名的命名规范:
驼峰法:
AgeOfTank
下划线法:
age_of_tank
变量不要使用中文命名
首字母要用英文或者下划线,不能用数字开头
变量的三个特征:
id:变量的地址
type:变量的类型
value:变量的值

常量要用大写字母命名:
SCHOOL='合肥学院'
单行注释:
单行注释:#,
快捷键:ctrl+/
多行注释:
‘’‘ ’‘’或者""" """
三引号可以定义不在同一行的字符串
str1=''''安徽省
最牛的学院
合肥学院'''
优先掌握的操作
1,按索引取值(正向取,反向取):注只能取
2,切片(顾头不顾尾,步长)
3,长度len
4,成员运算in和not in
5,移除空白strip
6,切分split
7,循环
1,正向取
str1='hello tank!'
print(str1[0]) #h
print(str1[9]) #k
反向取:
print(str1[-2]) #k
2,切片(顾头不顾尾,步长)
print(str1[0:5]),按常理来说应该是6个字符,但是不顾尾原则,导致只能有五个了。#hello
print(str1[0:11]) #hello tank!
print(str1[0:11:2]) #hlotn!
3长度
print(len(str1)) #11
4,成员运算
print('h' in str1) #True
print('h' not in str1) #False
5,移除空白strip,
功能1:会移除字符串左右两边的空白
str1=' hello tank!'
print(str1.strip()) #hello tank!
功能2:
去除最左右两边指定的字符串(如果指定字符左边有空格或者其它字符都不能去除掉指定字符了)
str1='!tank!,,,'
print(str1.strip('!')) #tank!,,,
str1=' !tank!,,,!!!'
print(str1.strip('!'))
#!tank!,,,
lstrip去掉左边的指定字符(空格也是字符串)
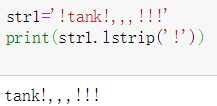
rstrip去掉右边的指定字符(空格也是字符串)

6,切分split
根据str1内的split内的进行切分
切分出来的值会存放在【】列表中
print(str1.split(' ')) #['hello', 'tank!']
str1='''安徽省
最牛的学院
是
合肥学院'''
str1
print(str1.split('
'))
#['安徽省','最牛的学院','是','合肥学院']
7,循环
for i in str1
格式化输出
尊敬的用户,你好!您本月的话费扣除99元,还剩0元。
# 通过某种占位符,用于替换字符串中某个位置的字符。
占位符:
%s: 可以替换任意类型
%d: 可以替换数字类型
示例:
尊敬的用户,你好!您本月的话费扣除%s元,还剩%d元。
str1='尊敬的用户,你好!您本月的话费扣除%s元,还剩%d元'%('一百',50)
字符串类型中的lower和upper
lower:转换成小写
upper: 转换成大写
str1='Wu YueFeng'
print(str1.lower())
print(str1.upper())
字符串类型中的startswith和endswith:
str1='hello wuyuefeng'
print(str1.startswith('hello')) #True
print(str1.endswith('g')) #True
字符串类型中的format:
str1=' my name is %s,my age is %s'%('wu',18)
print(str1)
1根据位置顺序格式化
str1=' my name is {},my age is {}'.format('wu',18)
2根据索引序号格式化
str1=' my name is {0},my age is {1}'.format('wu',18)
3指名道姓的格式化
str1=' my name is {name},my age is {age}'.format(name='wu',age=18)
join 字符串的拼接
仅仅只允许字符串的拼接,不能有整型数字之类的
print(' '.join(['tank',18]))这样写会报错
print('_'.join(['tank','18','from GZ'])) #tank_18_from GZ
replace :字符串的替换
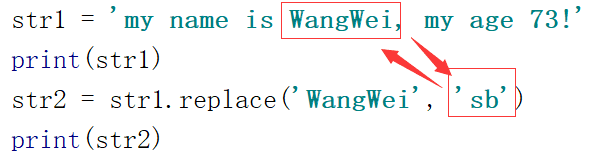

变量名.isdigit()的返回值是布尔值。