Hung-yi Lee李宏毅的课,没有废话,重难点都讲了,可以说是非常棒了
视频地址https://www.youtube.com/watch?v=ugWDIIOHtPA&ab_channel=Hung-yiLee
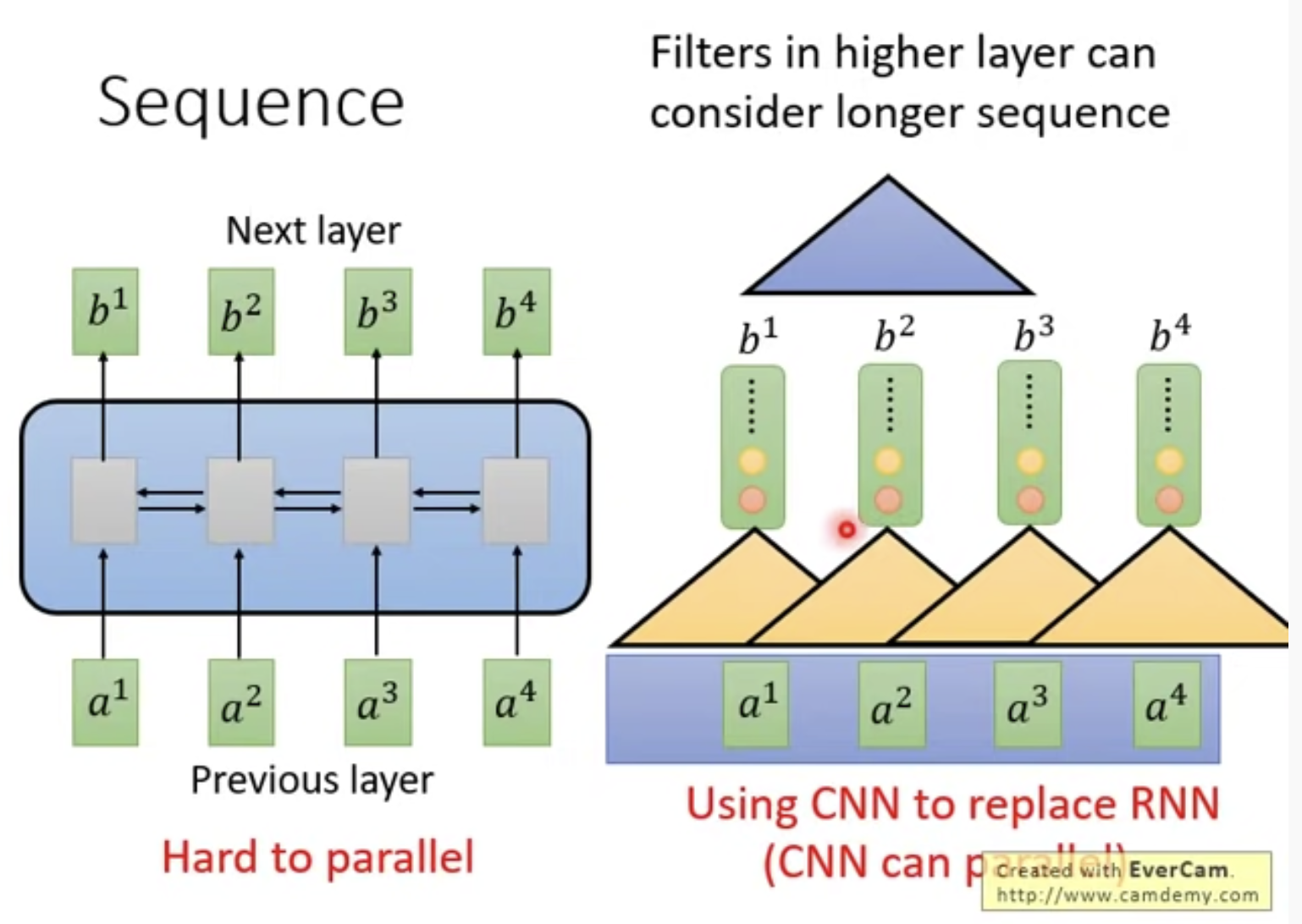
1. Seq2Seq采用RNN不能并行化,使用CNN代替RNN
例如CNN三角形选取旁边3个ai, 每个三角形(RNN)不需要等其他三角形计算完再计算,因此可以并行化
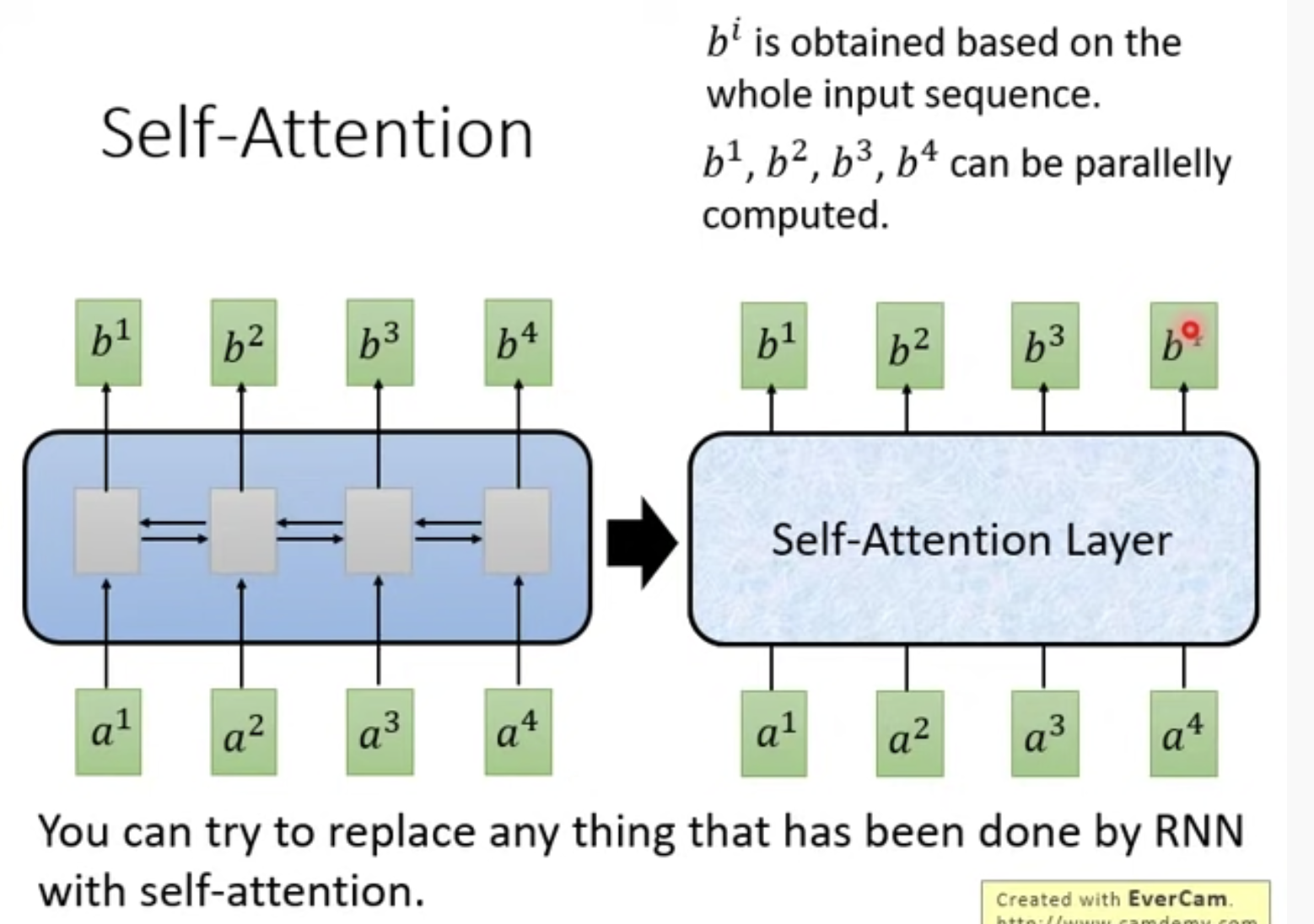
2. 记住有一种新的layer,叫做Self-Attention Layer,可以代替RNN
输入输出也与RNN一样,都是Sequence
biRNN虽然也可以获得全部输入信息,但是Self-Attention可以并行化啊
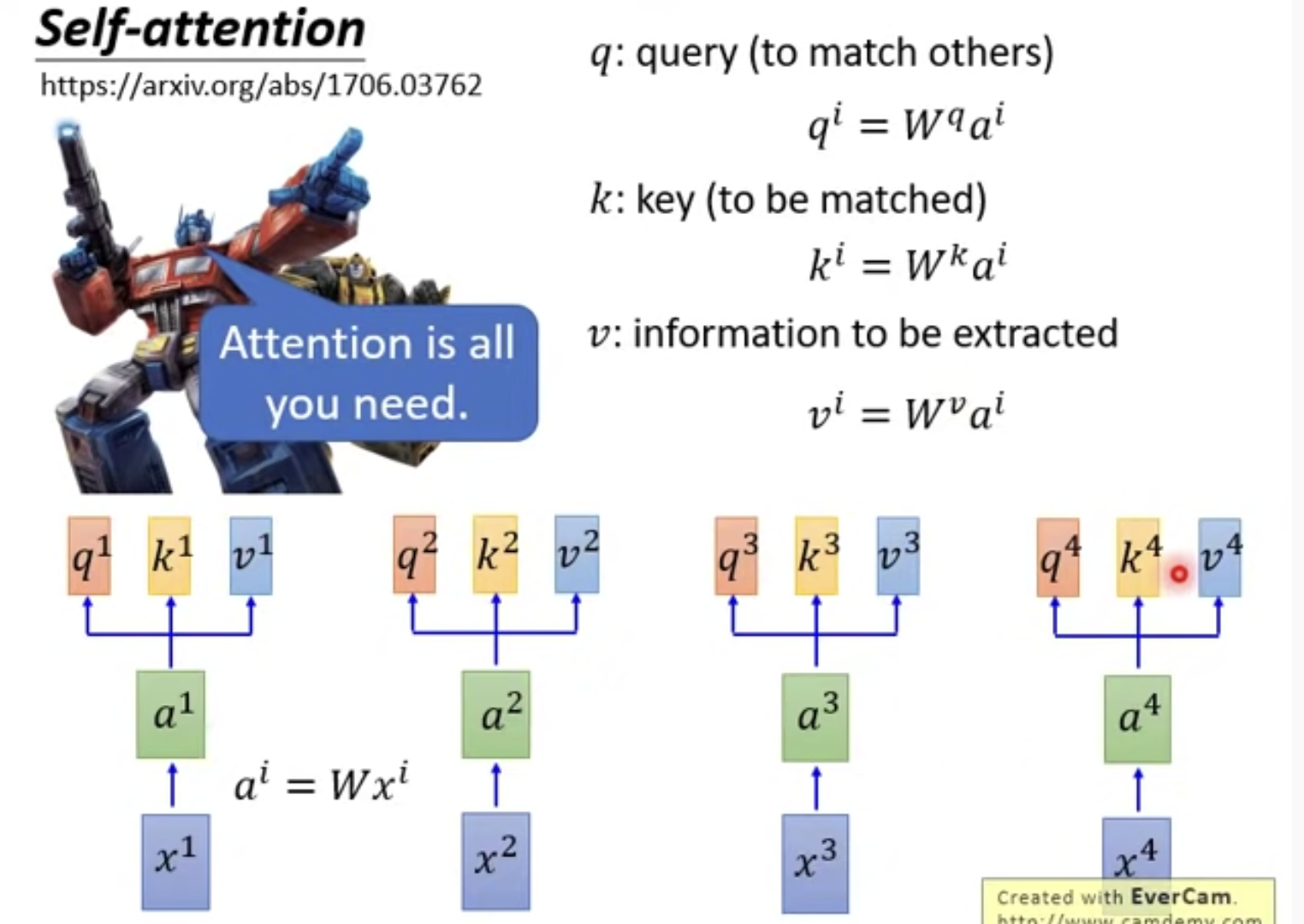
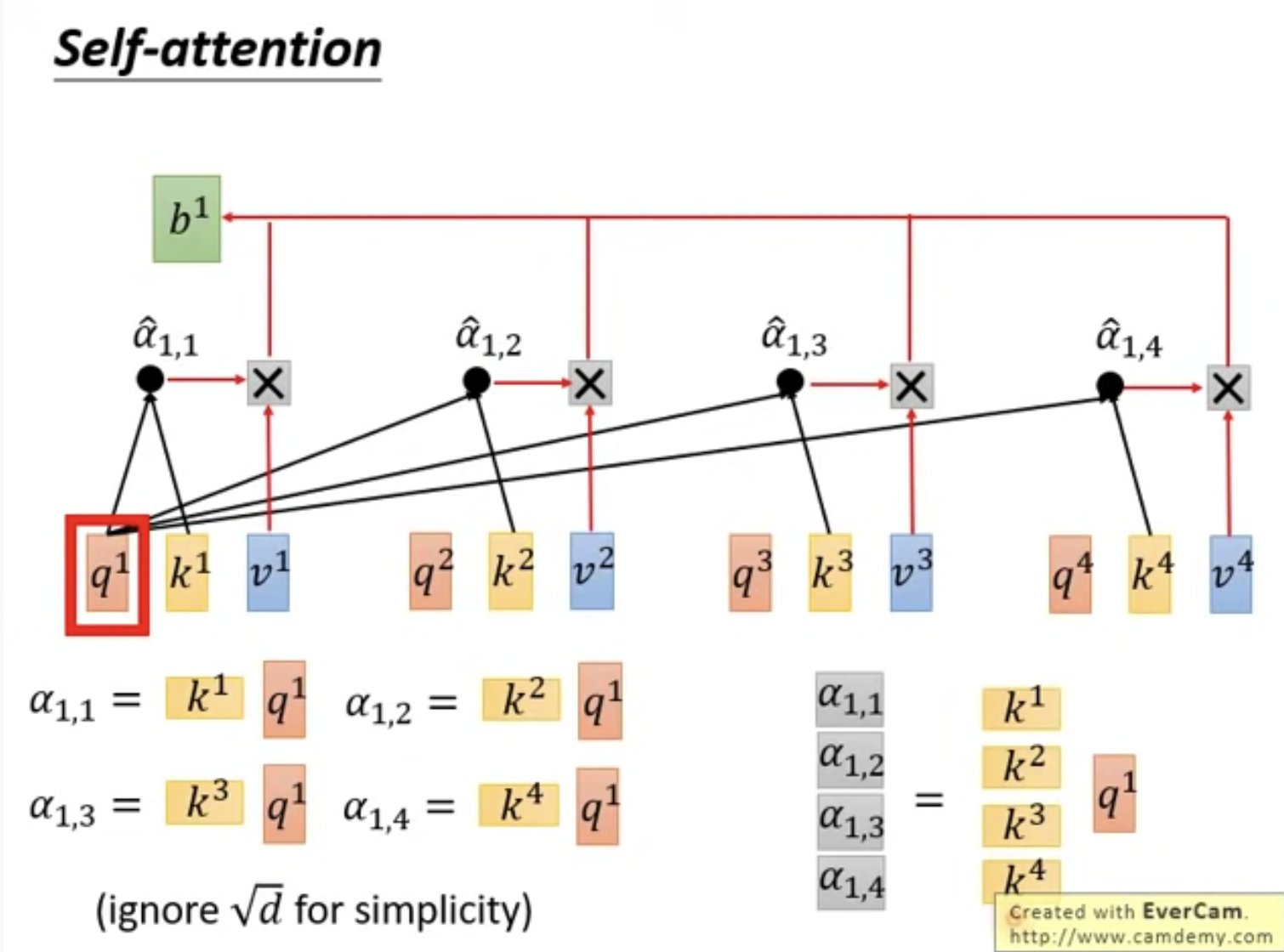
3. Self-Attention是怎么做的呢?
q, k其实都是a乘以一个矩阵
q, k是怎么用的呢?
q去与每一个k做点乘得到权重,除以sqrt(d)是为了消除点乘带来的常数放大
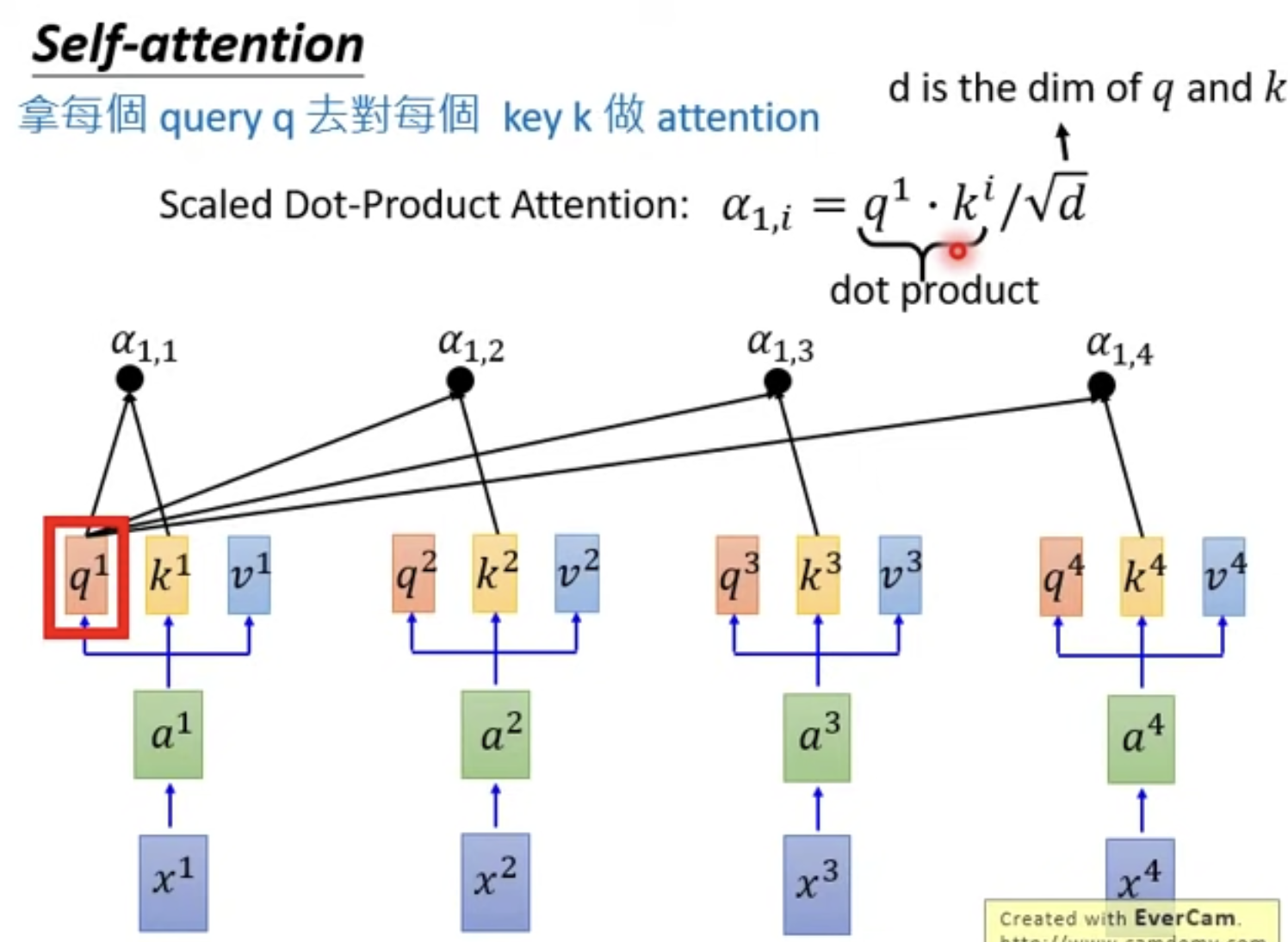
拿到权重系数alpha有什么用呢?
首先进行一个softmax
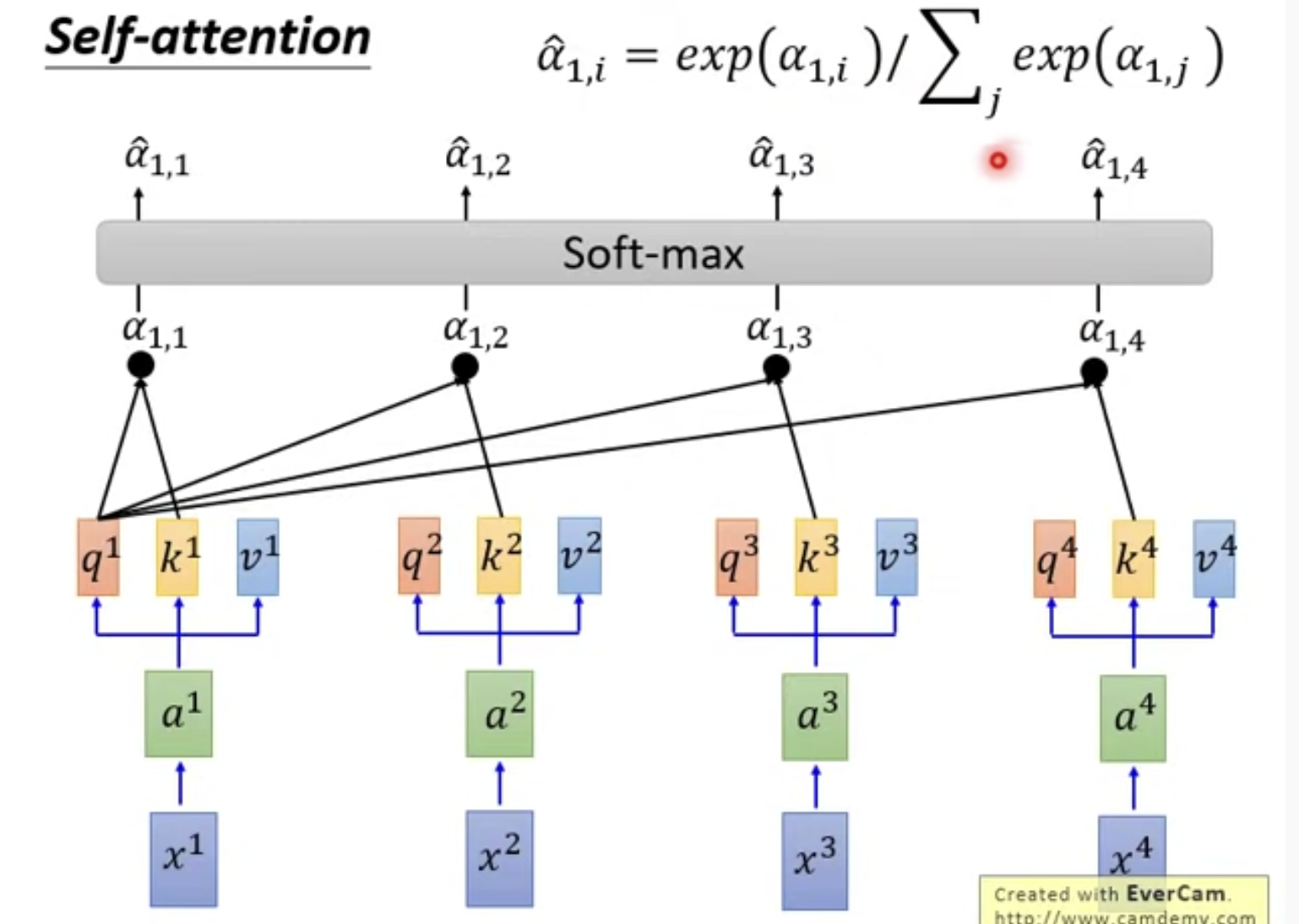
然后与每个v相乘,再相加,得到bi

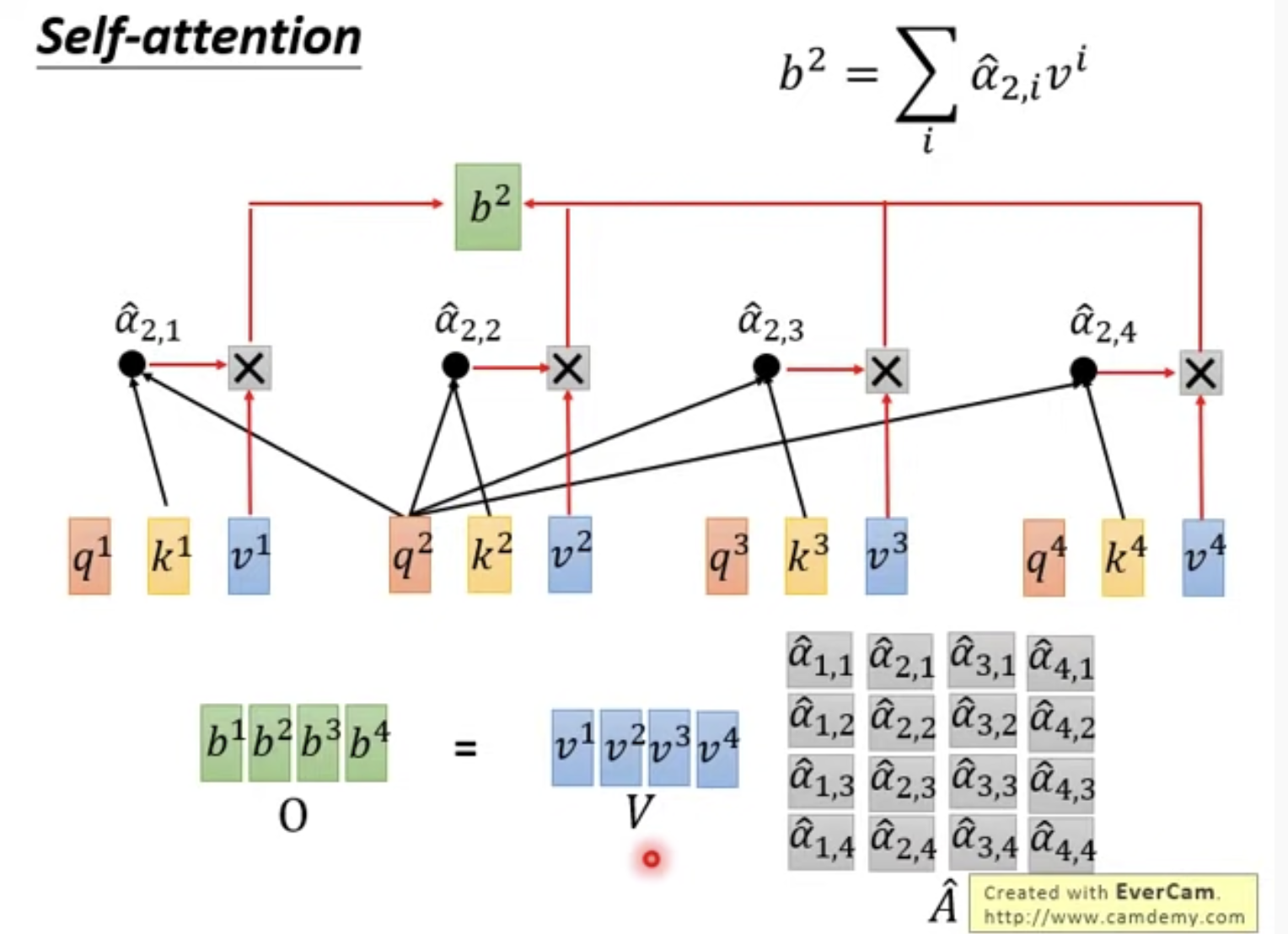
同样的方法可以得到b2

这样b1, b2, b3, b4都能被并行的算出来
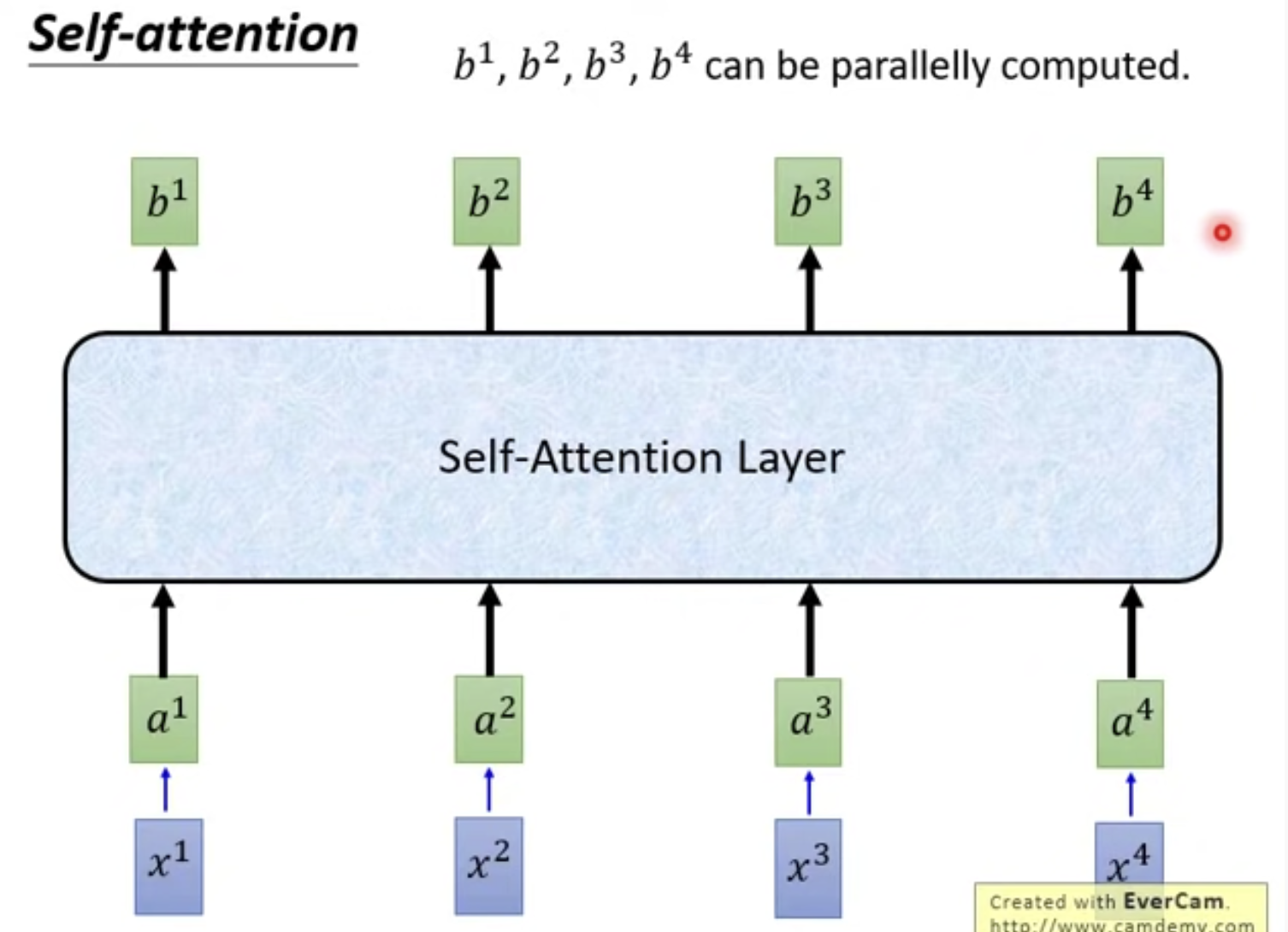
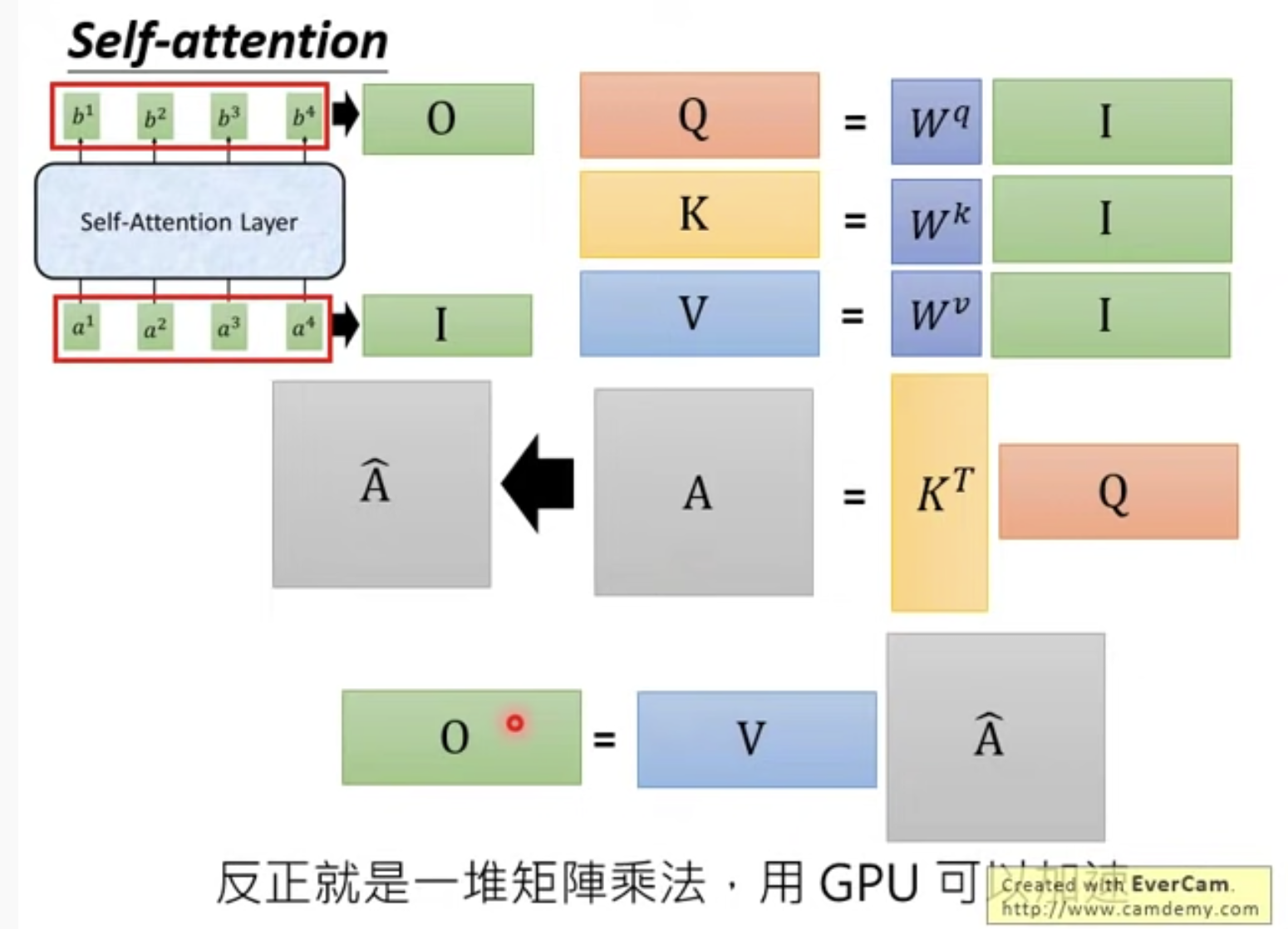
4. 将b1, b2, b3, b4的计算合成为矩阵计算
首先得到K, V, Q
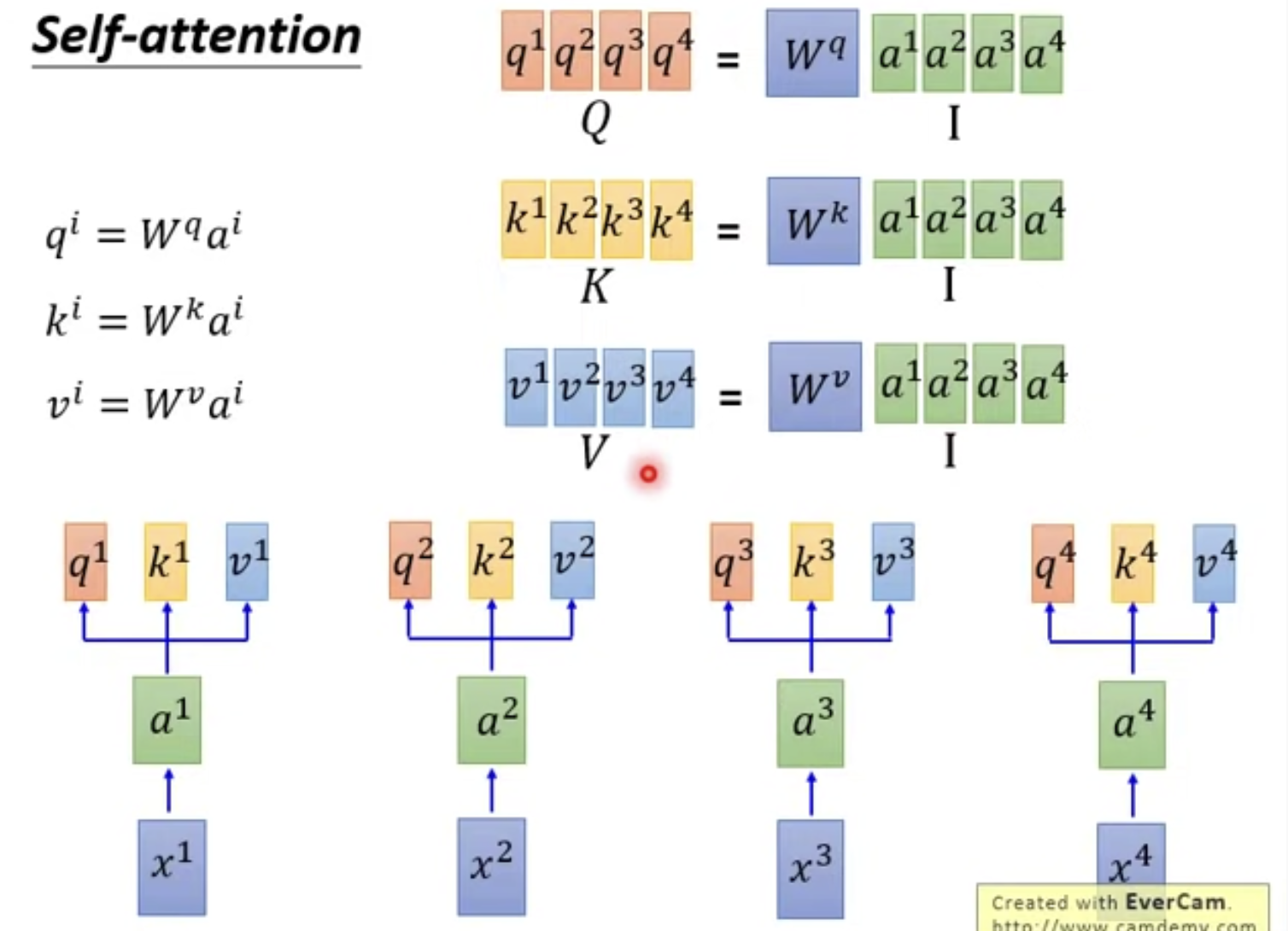
计算alpha1系列:
同理可计算alpha2, alpha3,alpha4

A经过softmax得到bar(a),
再将得到的系数矩阵与V相乘,得到bi,bi组成的矩阵记为O
整个过程如图:
反正最后就是几个矩阵乘法
5. Self-Attention的一个变形: Multi-head Self-Attention
n头机制就是n个W矩阵,得到n个q, k, v
这里以n=2为例

这样的话对于ai能得到两个bi,bi_1和bi_2

我们可以将两个bi concatenate(连接)起来 ,但是如果维度你不喜欢,乘以一个矩阵使它变成你想要的维度
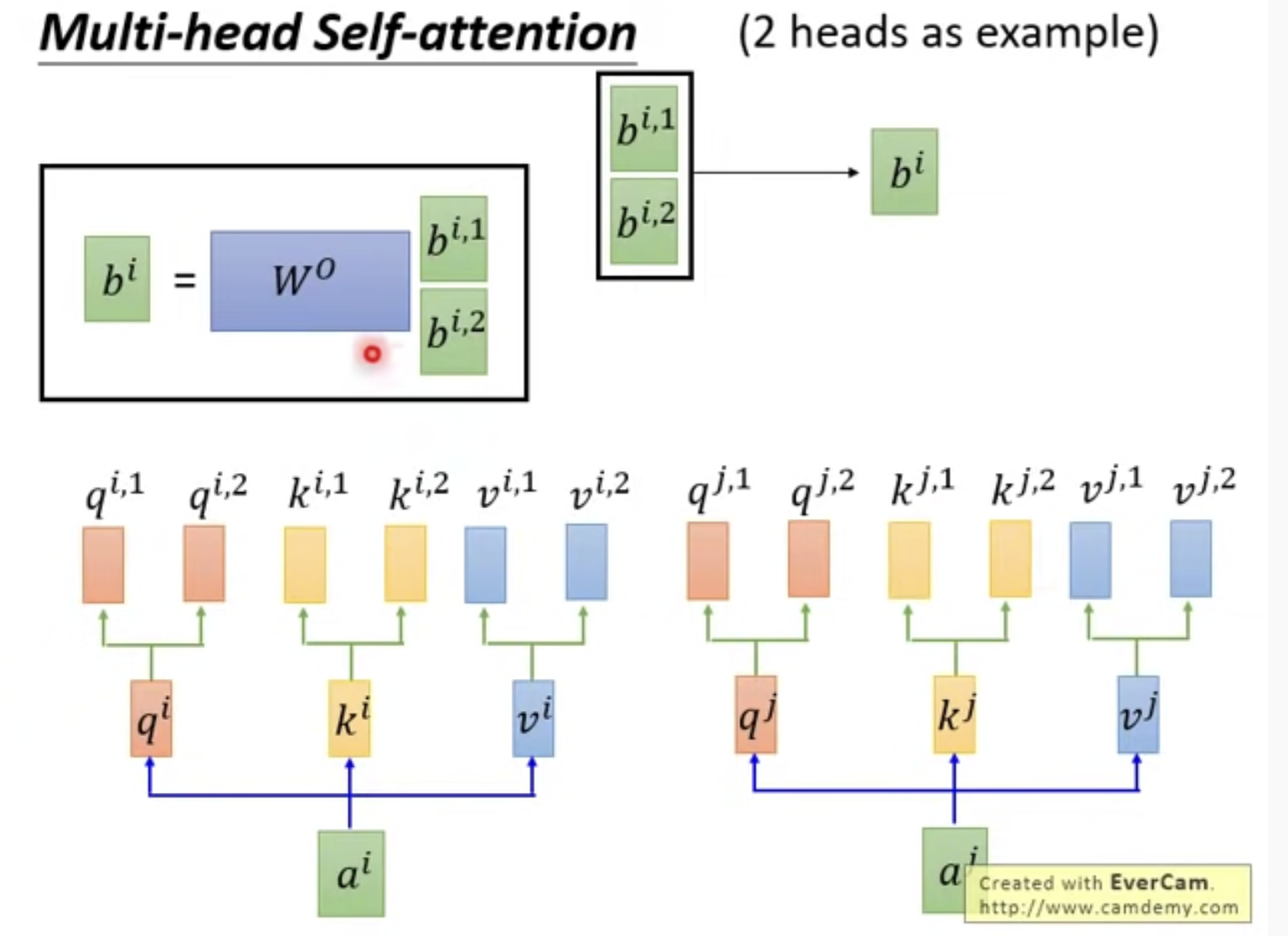
Multi-head有什么好处呢?也就是为什么要做Multi-head?
有些head是看距离比较远的信息,有些head是看周围的信息,这样的话每个head都能学到一些信息
6. Position embedding为什么是与ai直接相加?
首先为什么需要position embedding?因为在做attention的时候不管是远处还是邻近都是同样的对待,同样的做attention,这样就失去了原有的位置信息
其次,位置和值相加,代表着什么?为什么能这么做?李宏毅提供了一个与原paper不一样的理解角度,最终得到的运算是一样的,但讲法不一样
如果对xi append 一个one-hot的位置编码,与矩阵W相乘,根据矩阵的分块乘法,这等于两者分开相乘再相加
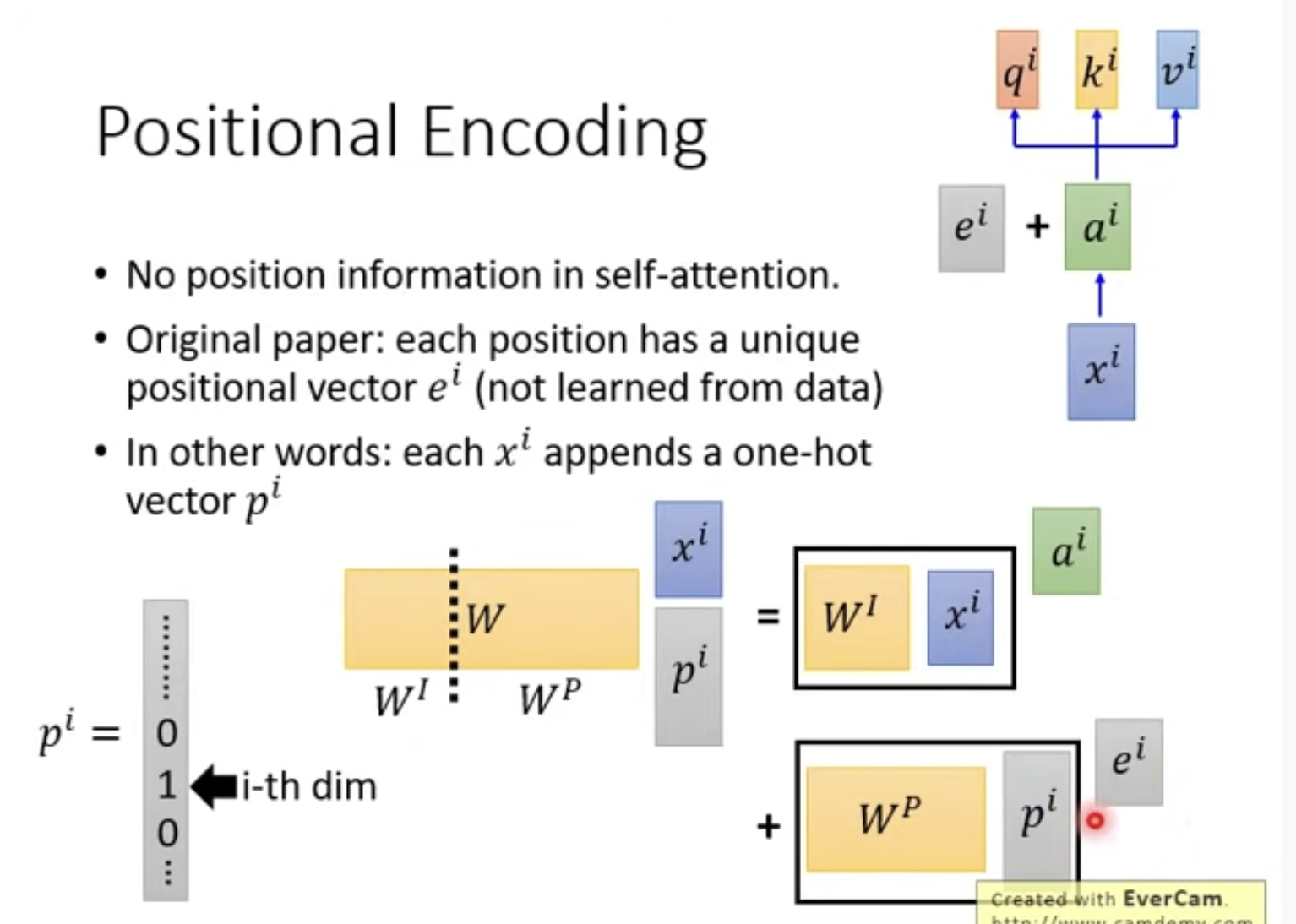
这两部分其实就相当于ai和ei,所以在可以相加
下面是看不懂的W_p的可视化hhh
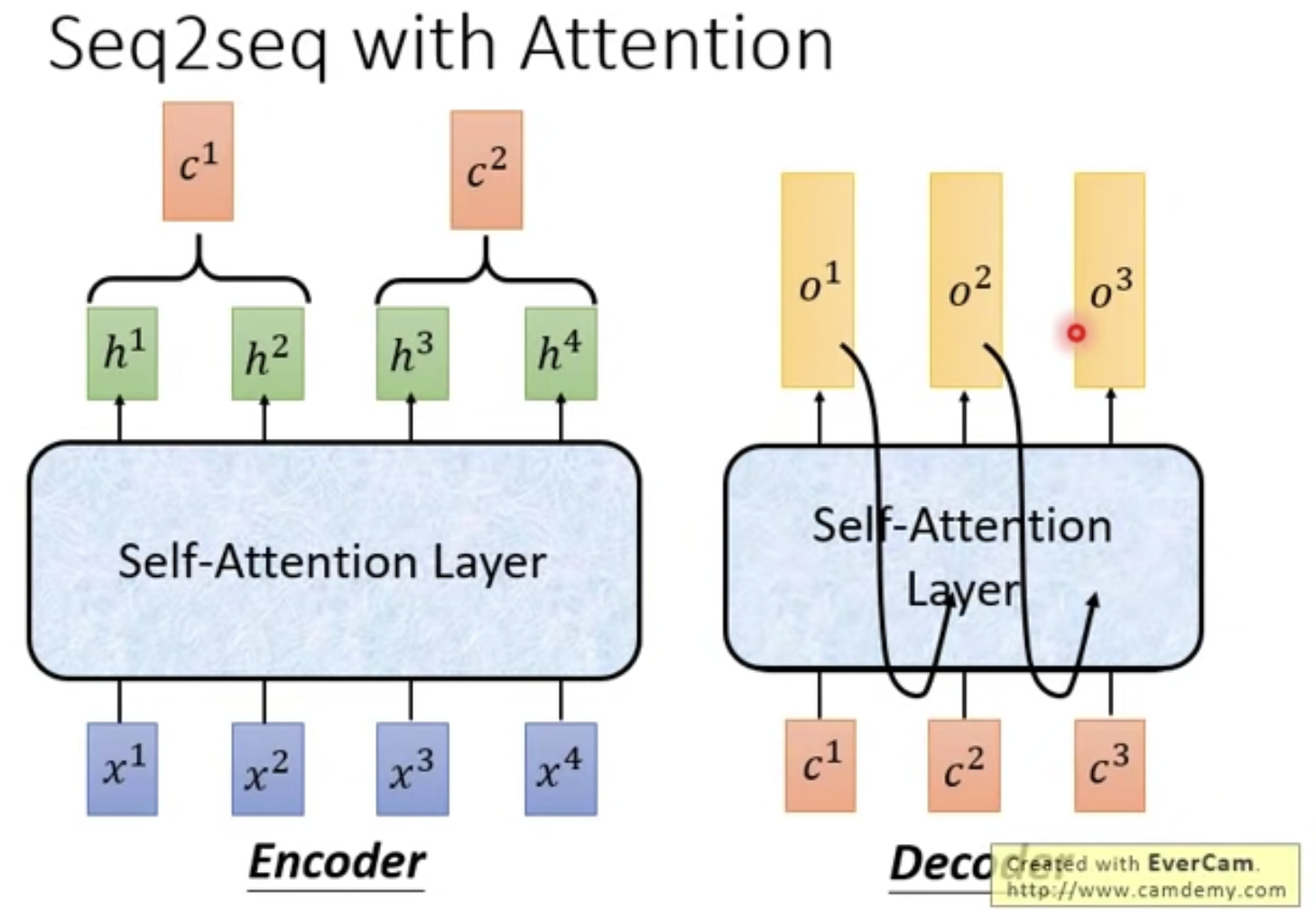
7. Self-Attention用于Seq2Seq是什么样子的..
传统的Seq2Seq:内部使用的RNN

使用Self-Attention后:就是用Self-Attention layer代替RNN layer
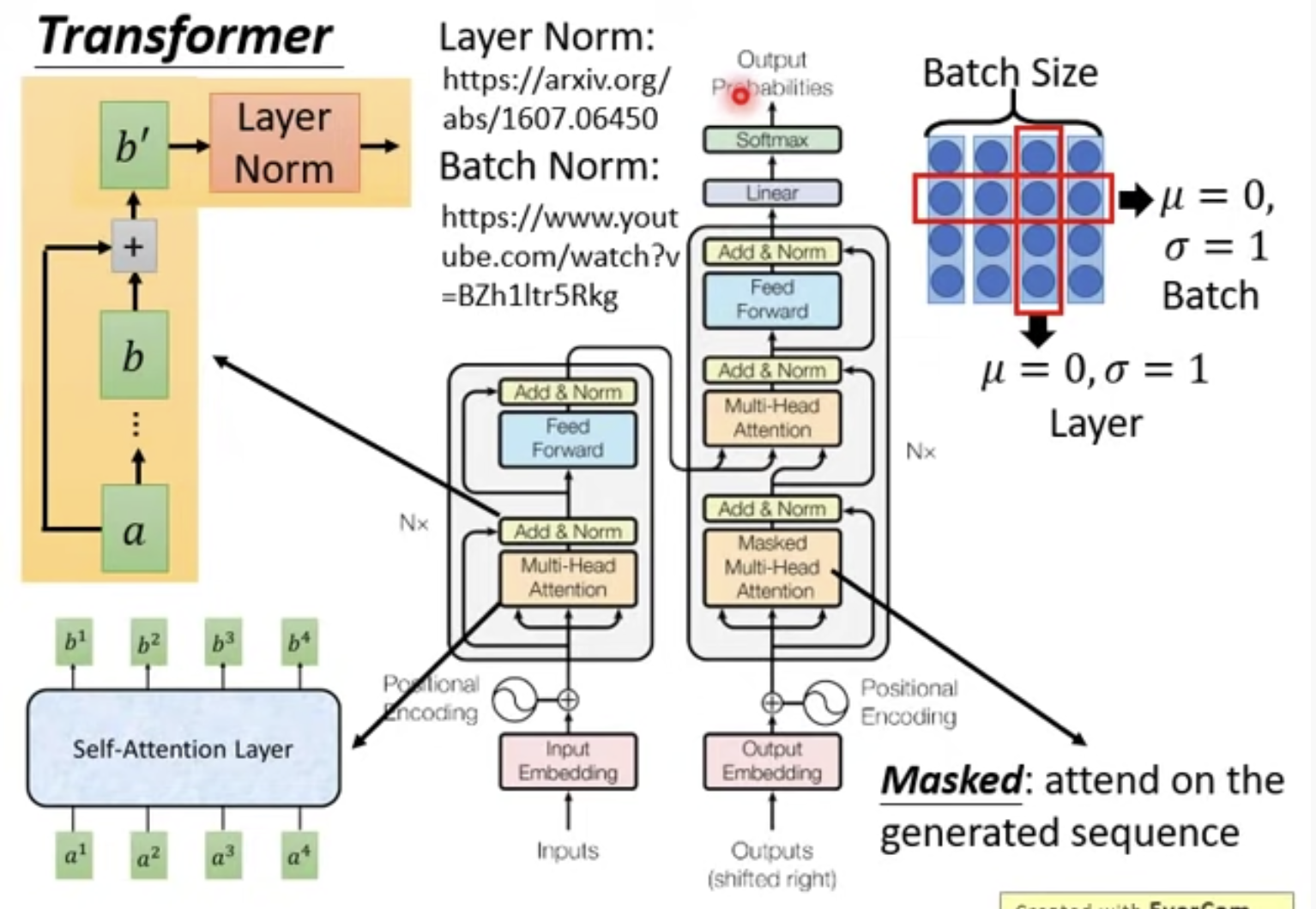
8. Transformer中的encoder和decoder详解
encoder: 包括Multi-head Attention层、Add层、Norm层
Multi-head Attention层得到的bi的维度,经过映射,和self-Attention是一样的;
Add层是有一个残差加入;
Norm层不是用的Batch norm而是Layer norm,Layer norm经常用于RNN中;
Feed forward层会对每个bi进行一些处理;

decoder: 与encoder相比,多的新结构是Mask multi-head attention,其实就是只用到前面已经生成的output来参与attention,这也很显然啊,还没有产生出来的东西怎么拿来用啊...
9. Attention visualization
在原始paper的最终版本附有一些可视化
两个word之间都会计算权重,weight越大线条越粗
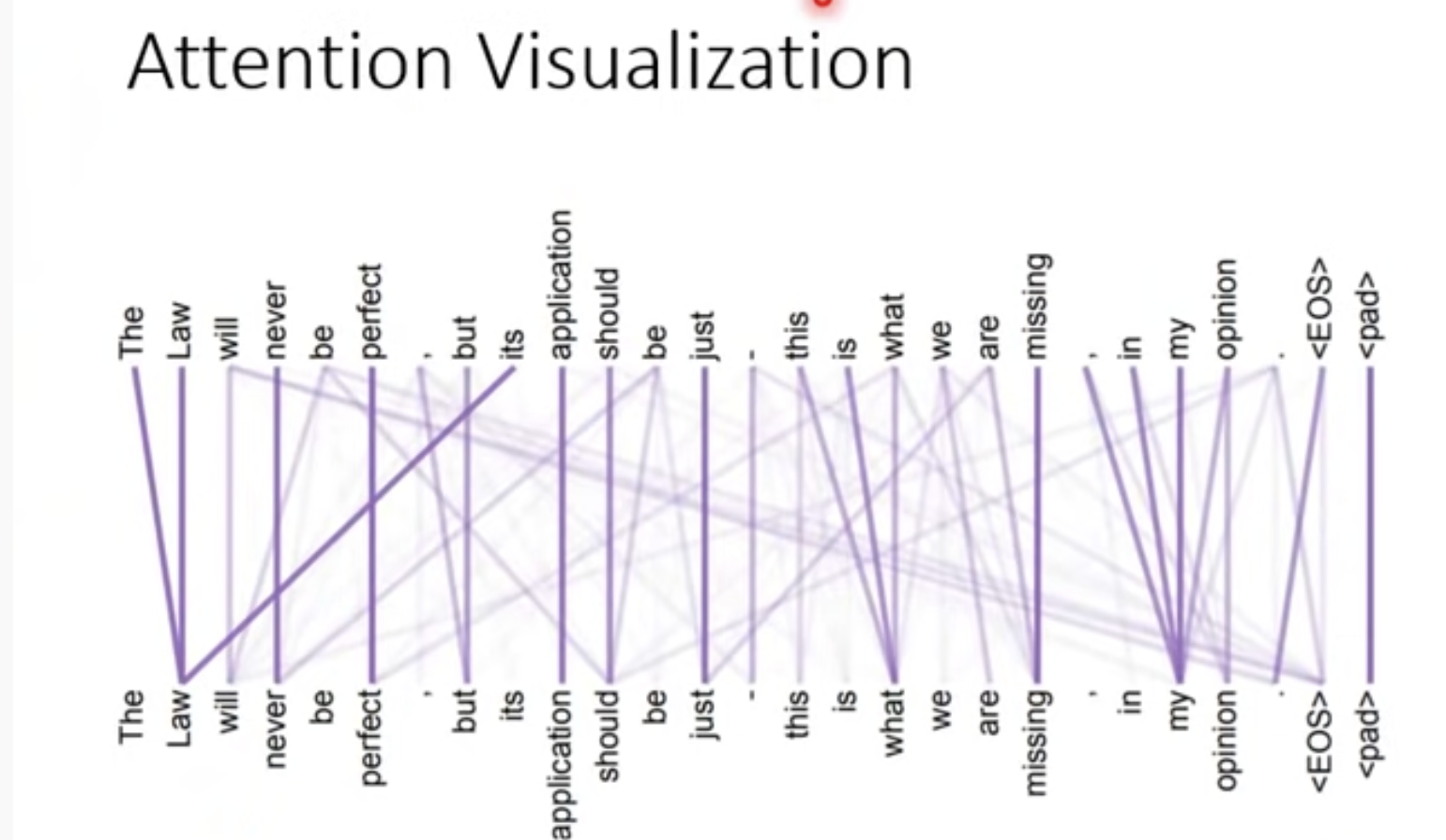
有一个非常神奇的现象:Attention能准确的理解"it",tired的时候it指向animal,wide的时候it指向了street,nb!!

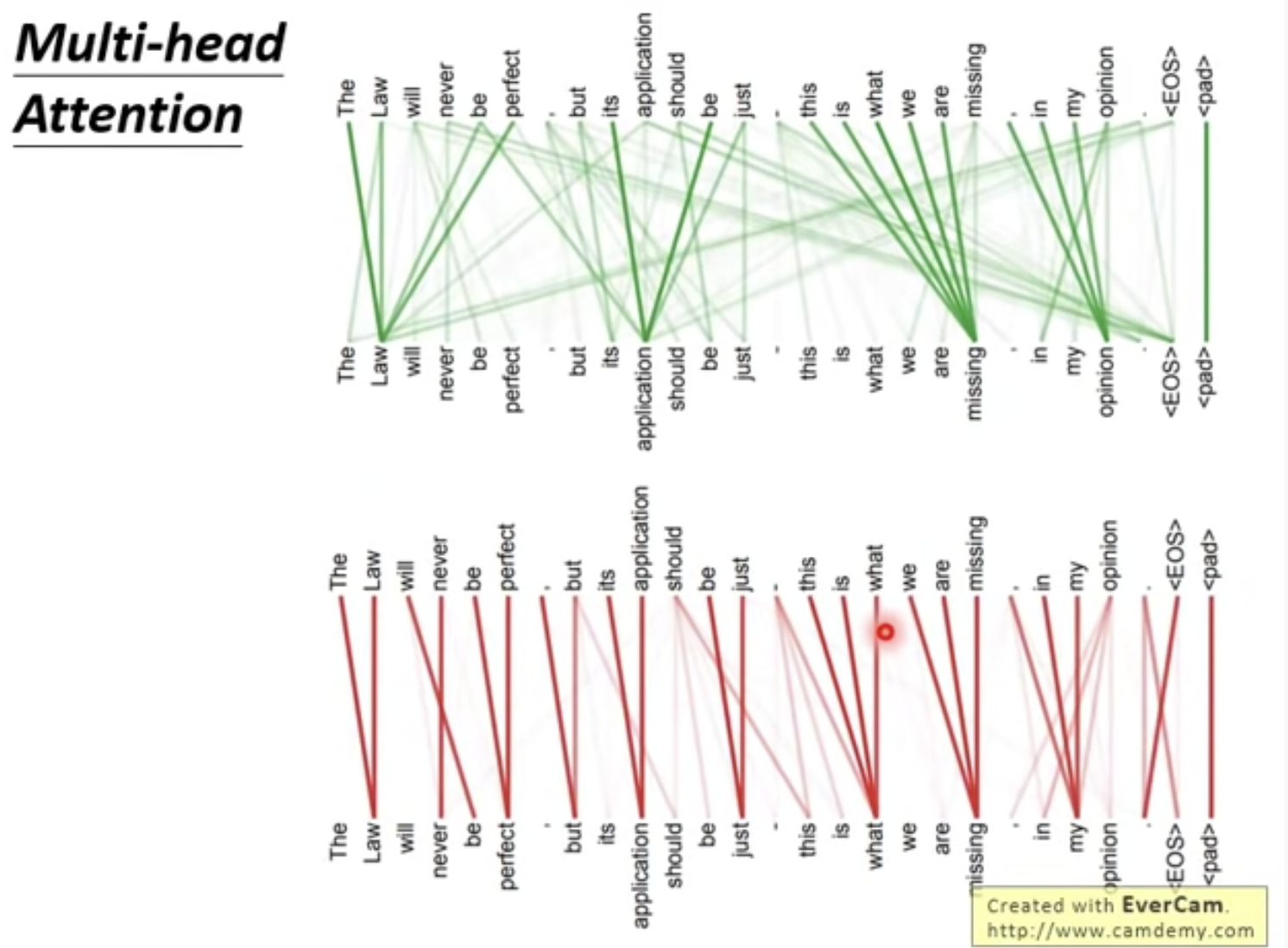
再看看Multi-head Attention的可视化:展现不同的head的确关注到了不同的信息
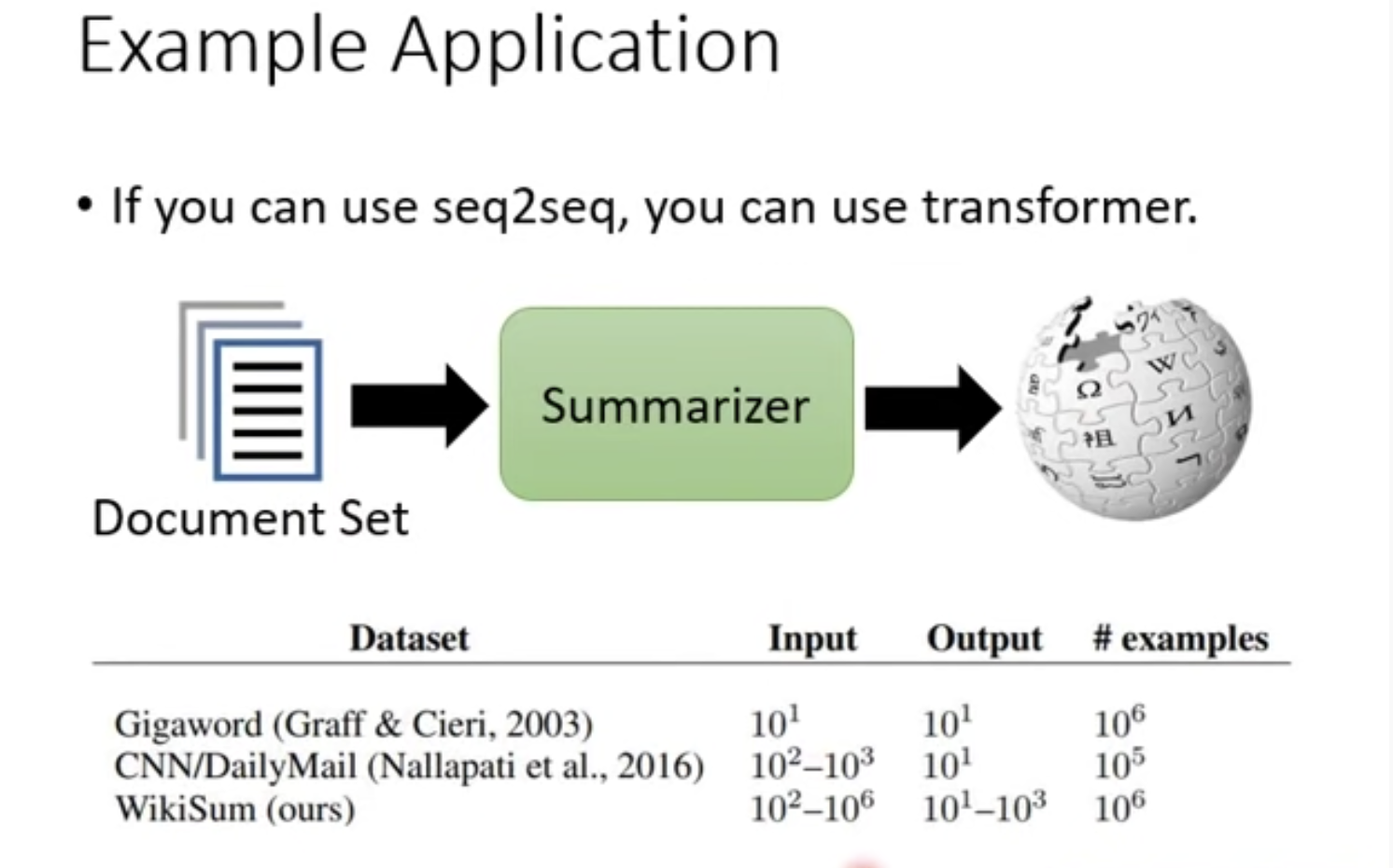
10. Some Example Application
1) page2page: wiki文章生成wiki文章
没有transformer的做不了,因为Input有长达1e6个单词,RNN不能并行,训练起来太慢了
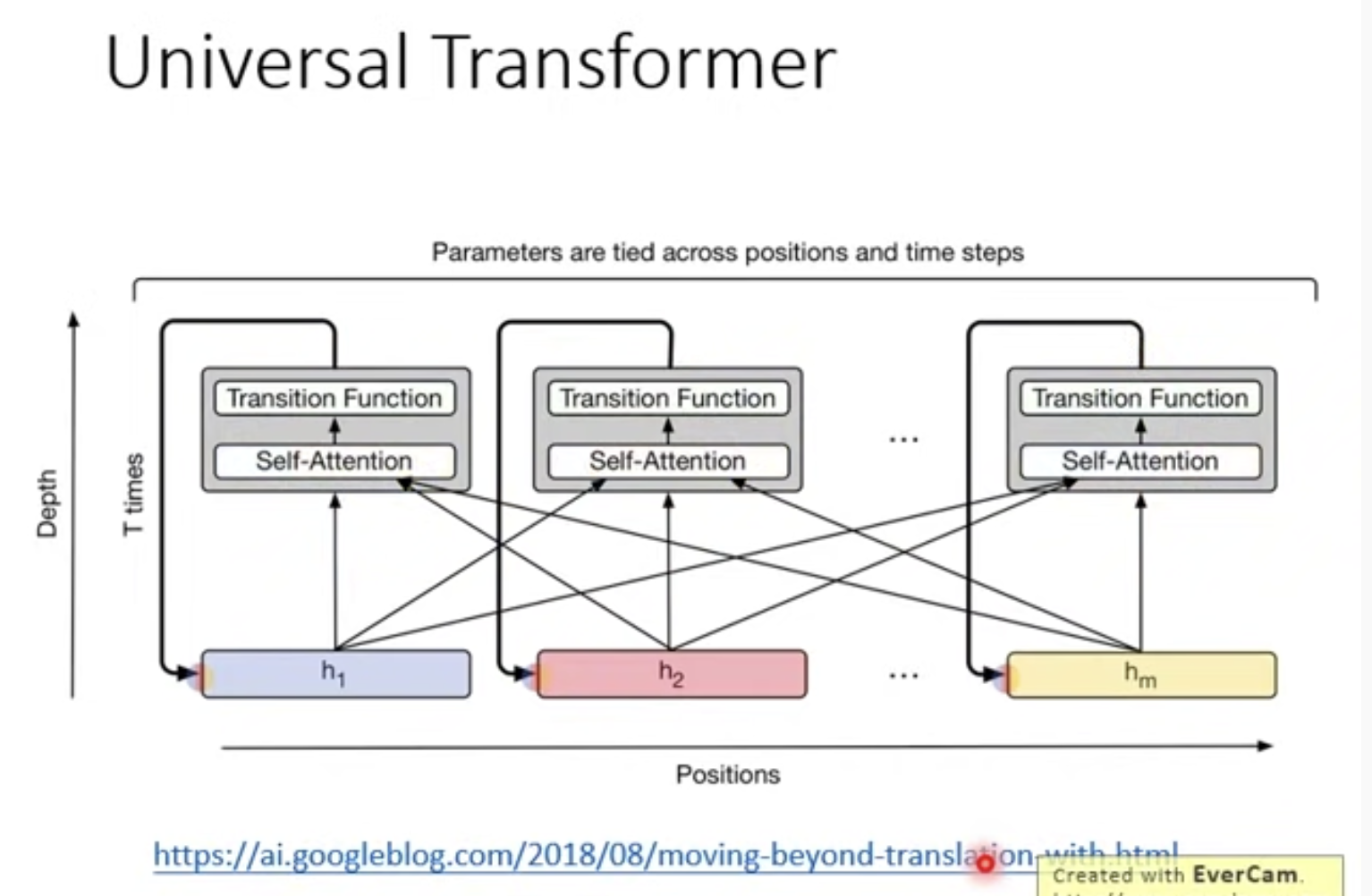
2)Universal transformer:将之前横轴是RNN,换成深度上是RNN