ref:
https://towardsdatascience.com/how-to-use-datasets-and-dataloader-in-pytorch-for-custom-text-data-270eed7f7c00
https://pytorch.org/tutorials/beginner/data_loading_tutorial.html
https://sparrow.dev/pytorch-dataloader/
Creating a PyTorch Dataset and managing it with Dataloader keeps your data manageable and helps to simplify your machine learning pipeline. a Dataset stores all your data, and Dataloader is can be used to iterate through the data, manage batches, transform the data, and much more.
Import libraries
import pandas as pd import torch from torch.utils.data import Dataset, DataLoader
Pandas is not essential to create a Dataset object. However, it’s a powerful tool for managing data so i’m going to use it.
torch.utils.data imports the required functions we need to create and use Dataset and DataLoader.
Create a custom Dataset class
If the original data are as follows:
in numbers.cvs:
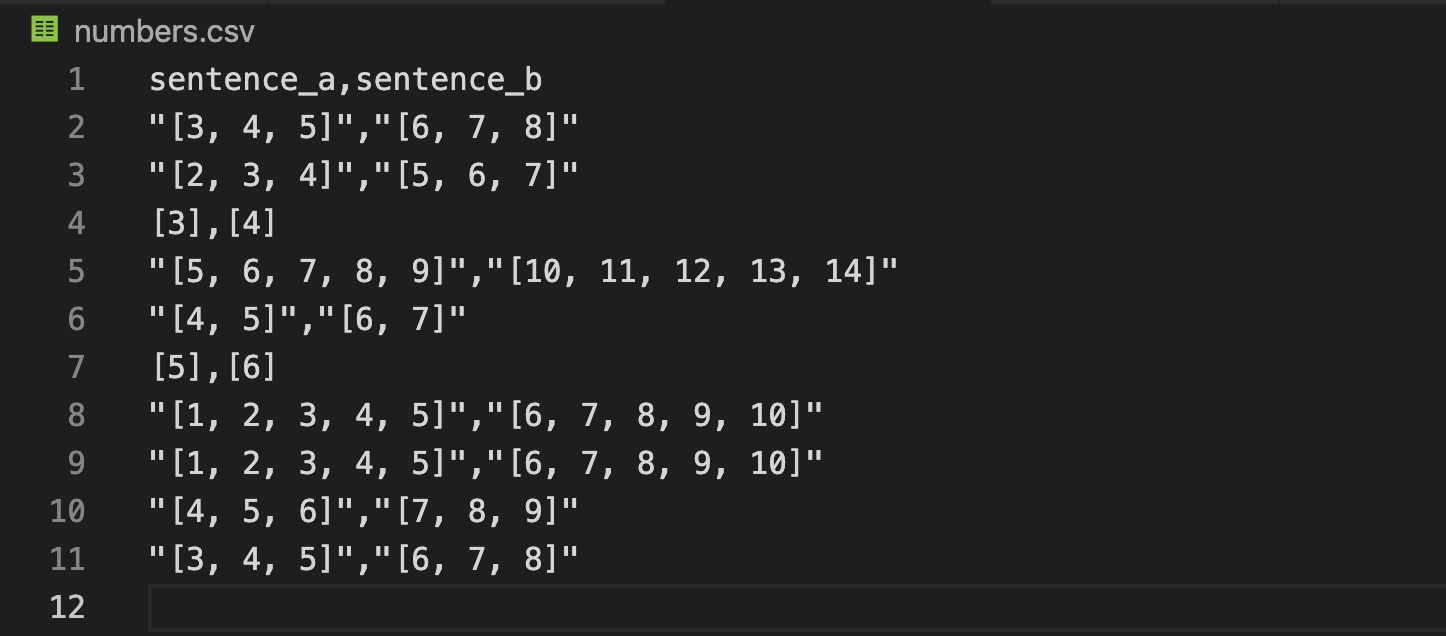
torch.utils.data.Dataset is an abstract class representing a dataset. Your custom dataset should inherit Dataset and override the following methods:
__len__so thatlen(dataset)returns the size of the dataset.__getitem__to support the indexing such thatdataset[i]can be used to get iith sample.
We will read the csv in __init__ but leave the reading of images to __getitem__. This is memory efficient because all the images are not stored in the memory at once but read as required.
class SeqDataset(Dataset): def __init__(self, file_root, max_length) -> None: super(SeqDataset).__init__() self.sentences = pd.read_csv(file_root) self.max_length = max_length def __len__(self): return len(self.sentences) def __getitem__(self, index): # 字符串处理 sentence_a = self.sentences.sentence_a[index][1:-1].split(",") sentence_b = self.sentences.sentence_b[index][1:-1].split(",") # ['3', '4', '5'] # ['6', '7', '8'] # listz转array sentence_a = np.array([int(x) for x in sentence_a]) sentence_b = np.array([int(x) for x in sentence_b]) # array([3, 4, 5]) # array([6, 7, 8]) # 补齐 sentence_a = np.pad(sentence_a, (0, self.max_length-sentence_a.shape[0]), 'constant', constant_values=(0,0)) sentence_b = np.pad(sentence_b, (0, self.max_length-sentence_b.shape[0]), 'constant', constant_values=(0,0)) # array([3, 4, 5, 0, 0, 0, 0, 0, 0, 0]) # array([6, 7, 8, 0, 0, 0, 0, 0, 0, 0]) return sentence_a, sentence_b
Iterating through the dataset
We can iterate over the created dataset with a for i in range loop as before.
However, we are losing a lot of features by using a simple for loop to iterate over the data. In particular, we are missing out on:
- Batching the data
- Shuffling the data
- Load the data in parallel using
multiprocessingworkers.
torch.utils.data.DataLoader is an iterator which provides all these features. Parameters used below should be clear. One parameter of interest is collate_fn. You can specify how exactly the samples need to be batched using collate_fn. However, default collate should work fine for most use cases.
dataloader = DataLoader(dataset, batch_size=4, shuffle=False, num_workers=0, collate_fn=None) for batch_idx, batch in enumerate(dataloader): src, trg = batch print(src.shape) print(trg.shape)
Output:
(deeplearning) ➜ TransformerScratch python generate_data.py torch.Size([4, 10]) torch.Size([4, 10]) tensor([[3, 4, 5, 0, 0, 0, 0, 0, 0, 0], [2, 3, 4, 0, 0, 0, 0, 0, 0, 0], [3, 0, 0, 0, 0, 0, 0, 0, 0, 0], [5, 6, 7, 8, 9, 0, 0, 0, 0, 0]]) tensor([[ 6, 7, 8, 0, 0, 0, 0, 0, 0, 0], [ 5, 6, 7, 0, 0, 0, 0, 0, 0, 0], [ 4, 0, 0, 0, 0, 0, 0, 0, 0, 0], [10, 11, 12, 13, 14, 0, 0, 0, 0, 0]]) torch.Size([4, 10]) torch.Size([4, 10]) tensor([[4, 5, 0, 0, 0, 0, 0, 0, 0, 0], [5, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 2, 3, 4, 5, 0, 0, 0, 0, 0], [1, 2, 3, 4, 5, 0, 0, 0, 0, 0]]) tensor([[ 6, 7, 0, 0, 0, 0, 0, 0, 0, 0], [ 6, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 6, 7, 8, 9, 10, 0, 0, 0, 0, 0], [ 6, 7, 8, 9, 10, 0, 0, 0, 0, 0]]) torch.Size([2, 10]) torch.Size([2, 10]) tensor([[4, 5, 6, 0, 0, 0, 0, 0, 0, 0], [3, 4, 5, 0, 0, 0, 0, 0, 0, 0]]) tensor([[7, 8, 9, 0, 0, 0, 0, 0, 0, 0], [6, 7, 8, 0, 0, 0, 0, 0, 0, 0]])
Full Code
import torch from torch.utils.data import Dataset, DataLoader import pandas as pd import numpy as np import ipdb class SeqDataset(Dataset): def __init__(self, file_root, max_length) -> None: super(SeqDataset).__init__() self.sentences = pd.read_csv(file_root) self.max_length = max_length def __len__(self): return len(self.sentences) def __getitem__(self, index): # 字符串处理 sentence_a = self.sentences.sentence_a[index][1:-1].split(",") sentence_b = self.sentences.sentence_b[index][1:-1].split(",") # ['3', '4', '5'] # ['6', '7', '8'] # listz转array sentence_a = np.array([int(x) for x in sentence_a]) sentence_b = np.array([int(x) for x in sentence_b]) # array([3, 4, 5]) # array([6, 7, 8]) # 补齐 sentence_a = np.pad(sentence_a, (0, self.max_length-sentence_a.shape[0]), 'constant', constant_values=(0,0)) sentence_b = np.pad(sentence_b, (0, self.max_length-sentence_b.shape[0]), 'constant', constant_values=(0,0)) # array([3, 4, 5, 0, 0, 0, 0, 0, 0, 0]) # array([6, 7, 8, 0, 0, 0, 0, 0, 0, 0]) return sentence_a, sentence_b if __name__ == "__main__": dataset = SeqDataset("./numbers.csv", 10) # print(dataset.__len__()) # print(dataset.__getitem__(0)) # print(dataset.__getitem__(6)) dataloader = DataLoader(dataset, batch_size=4, shuffle=False, num_workers=0, collate_fn=None) for batch_idx, batch in enumerate(dataloader): src, trg = batch print(src.shape, trg.shape) print(src) print(trg) # ipdb.set_trace()