#VLDB20# F1 Lightning: HTAP as a Service 阅读笔记
Google 有两个主要的OLTP关系型数据库:Spanner和F1,其中F1数据库主要服务于包括但不限于Google AdWords, Payments, and Shopping等产品线。本论文提出的F1 Lightning是一个已实现并服务于Google的松耦合的HTAP解决方案。从最终期望的目标形态来看,F1 Lightning实际强需求的是F1 Query (A federated query engine)以及F1 Lightning自身,OLTP引擎并不局限与F1 DB。按照文中所说,只要对应DB的连接组件ChangePump实现了,F1 DB、Spanner、Mesa、BigTable甚至ColumnIO偏列存的数据库引擎都可以支持。所以论文表示自己propose的是一个solution,而不是一个product。这就是上文所说的松耦合(loose-coupled)的含义,这样的好处是在实现HTAP的方案中对OLTP引擎的侵入修改尽可能的少。
简单借助《Hybrid transactional/analytical processing: A survey.》这篇survey性质论文review了下HTAP的方案。很多新型关注HTAP论文的数据库,都尝试想要用一个系统来同时解决TP和AP问题,包括某些行列混合存储方案。事实上从这篇survey中我们可以看到,基本能商业化的完整DB解决方案,都很难采取the same layout for both OLTP&OLAP。Hekaton、SAP HANA等都是采用了 in-memory的不同layout的store去支持TP或AP需求。可能现在借助数据湖的一些大数据方案从概念上能同时支持AP和TP需求,但背后是高延时或非实时的代价。因此,反正都要冗余数据,分离OLTP和OLAP,在两者之间同步数据也是一种HTAP方案,相比起提供一个HTAP的Database,正如本论文所定义,F1 Lightning提供的是HTAP-as-a-service。Related works列举了SAP HANA (AP实现与TP紧耦合)、TiFlash(与查询层紧耦合)、LinkedIn Databus(方案不完整)、Spark dependented systems(Spark和SparkSQL天然提供HTAP支持,但Spark不管数据存储,作者认为这些系统仍免不了用户级别的数据迁移)。通过以上几个例子,作者再次说明F1 Lightning的价值:松耦合、对OLTP引擎入侵少甚至可替换、与查询层也是较松耦合。
整个系统解决方案由三个大部分构成:
- F1 Query 查询层,联邦的分布式查询引擎,SQL方言为GoogleSQL(ZetaSQL),目前每天服务千亿查询。
- OLTP引擎如 F1 DB。论文中说是方案对OLTP引擎 no modification,实际上是建立在OLTP数据库已经暴露了一个较完备的change replay的API的基础上。
- F1 Lightning 维护查询需要的数据的存储
- Lightning Server以Partitions加LSM的方式来维护数据存储和分区,并且会将ChangePump的数据行村转列存存储。它运行在一个分布式文件系统之上,并与OLTP引擎保持事务快照一致。
- ChangePump是处于Lightning Server之外的服务,这个针对不同OLTP引擎定制化实现的服务可以帮助将OLTP log同步到Lightning server。
F1 Lightning的加入达成了如下目标:
- 提升了查询的资源利用率和延时。资源利用率这点有点牵强,毕竟冗余了列存。
- 简单配置和去除重复工作。松耦合的实现使得Lightning的开启与否的配置非常简单,同时标准化的HTAP框架也避免了不同OLTP引擎的HTAP开发重复工作。
- 透明用户体验。用户无需感知HTAP的存在,透过同样的F1 Query查询即可。
- 数据一致性和新鲜度。Freshness在HTAP里表示OLAP能看到的数据与OLTP的数据的差异。F1 Lightning承诺能以low latency同步数据。
- 数据安全性。由于跨系统带来的数据安全问题,F1 Lightning表示是会基于所接入的OLTP引擎的权限系统来定。这里实际上带来的另外一个耦合问题就是权限系统,但文中未细说。
- 团队和项目独立性。F1 Lightning由专门团队专职维护,不属于任一F1 DB或Spanner团队。
- 扩展性。Lightning can be extended to support new transactional databases with little effort.
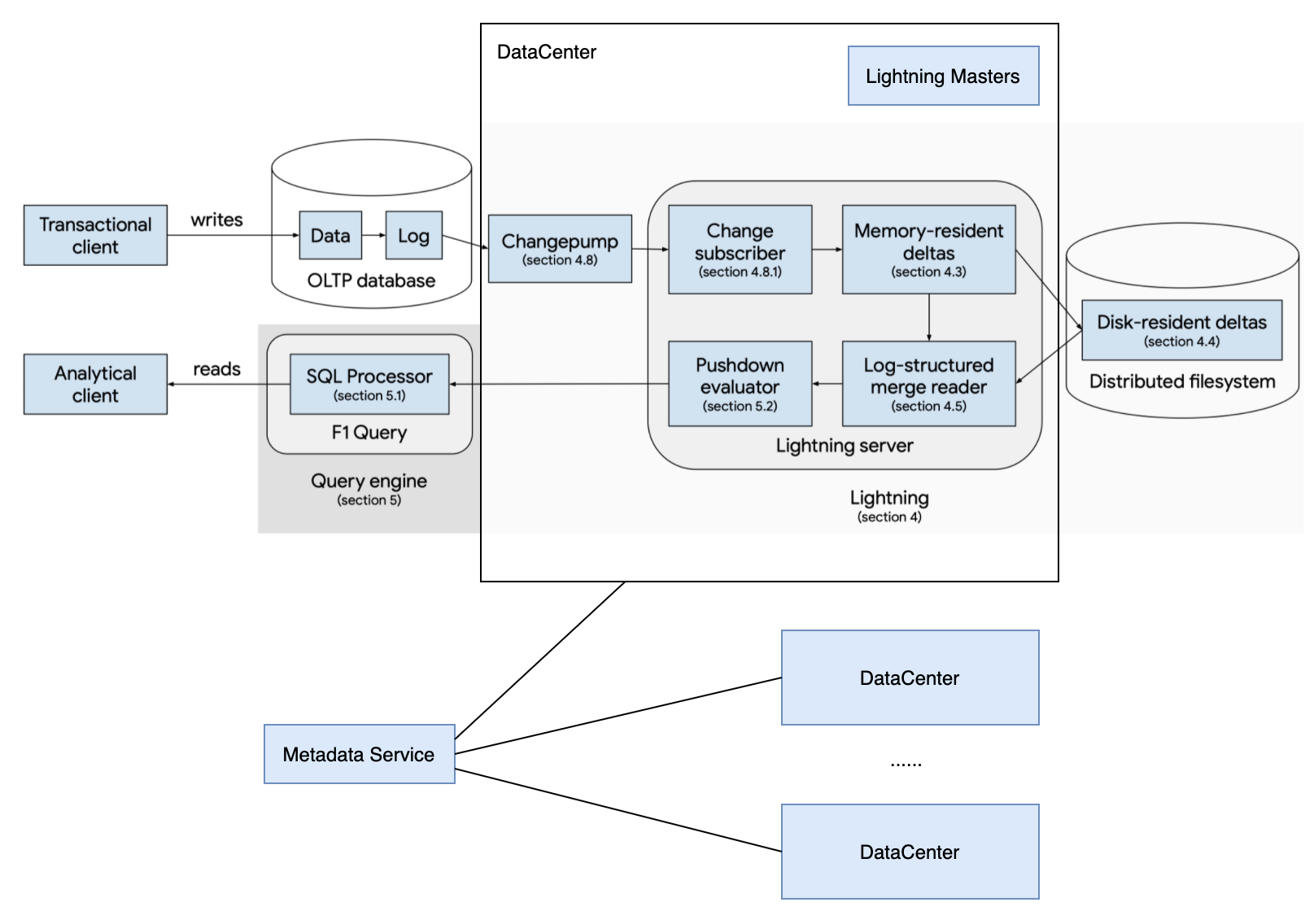
Lightning 架构
Lightning的整体服务架构文中没有很清晰地呈现,在一些后文介绍和Architecher一节中,可以发现,Lightning包括如下几个组件:
- Data Center: 一个DC包括如下几个子组件。每个DC维护一份独立完整的data(含Table schema和partition信息),也就是说DC之间互为备份。
- Changepump:定制化实现,负责监听OLTP的同步日志,负责OLTP数据到Lightning的同步。
- Lightning server: 可以认为文中Data storage的角色就是Lightning server,它相当于一个存储引擎,负责维护DFS上的数据。功能包括将Changepump同步过来的log apply成data、data compaction、read semantics(事务快照读的检查、事务版本管理)等。
- Lightning masters: 由于每个Lightning server负责只是一部分分区,对于一个分布式服务来说,需要一个协调角色来去协调分区信息、Changepump状态信息、Lightning server状态信息等各种问题,这个角色就是Lightning masters。文中没有介绍Lightning masters的单点问题,但从masters复数形式以及Metadata servers的类似介绍看,大概率也是masters内部自己解决了HA问题。
- task workers: 文中只介绍说是负责一些后台运行的任务,比如创建一个初始的快照状态等任务。逻辑上看可能是从属于Lightning server的,负责Lightning server一些可后台执行的任务。
- Metadata Servers: 存储DC组件的状态信息,DC之间share同一个Metadata service。Metadata service自己会解决HA问题,因此对DC来说,可以认为Metadata service是永远在线、不存在单点故障的。
此处我将不按照论文顺序去介绍,而是从几个数据库视角的关注点去切入看Lightning是怎么运作的。
一、Changepump是如何从OLTP到Lightning同步数据的。
Changepump提供了一套通用的机制和API去定义OLTP到AP结点的change replication。换言之,对于Lightning来说,Lightning不再需要关心OLTP结点是什么引擎、实现细节等,Changepump都会将其隐藏起来。为了达成这个目标,Changepump就必须包含以下功能:
- adapts from a transaction-oriented change log into a partition-oriented change log 。对于Lightning这样的partitioned system,一个事务日志背后可能影响多个独立的partitions,因此CHangepump要具备这种翻译拆分日志的能力。
- 参与到OLTP to OLAP的事务一致性的维护中。因为解耦,Lightning看不到OLTP引擎了,可以说Changepump成了他们唯一的通信方式,因此Changepump还得参与到事务一致性维护中去。也因此,某些在Lightning侧的事务数据管理(如文中提到的tracks the timestamps of all changes)功能被拆分到了Changepump中(效率更高),而不是放到一个单独维护的TransactionManager中。
论文没有描写Changepump如何去从OLTP获取数据以及相应API。Lightning server则通过一种订阅机制与Changepump交互,每个partitioned server会将start timestamp,key range, table等限定信息提前注册到Changepump,Changepump一旦发现满足条件的数据就会发给对应server。
Changepump同时会利用小批次checkpoint的技术,来避免维护per-key timestamp的开销。这导致Changepump的下游Lightning server也只能按checkpoint粒度去推进或回滚。但实际实现中,因为某些实现上的性能考虑,Changepump并未在每次发送changed数据的时候发送checkpoint timestamp,这里相当于一定程度牺牲了freshness,总之这里是个trade-off。
论文目前的OLTP到Lightning的数据timestamp delay大约在8ms左右。
二、Read semantics。
Lightning使用的是MVCC with snapshot isolation机制。每个查询都必须要带着一个指定的read timestamp(这里的timestamp就是版本),Lightning保证同样的read timestamp,看到的数据和OLTP结点的一致。和很多分布式数据库系统一样,Lightning有一个max safe timestamp表示最大的可读的一致点,在这个点所有数据已经写入完成;有一个min safe timestamp表示最早的可以读的点,小于此的read timestamp为不合法。min和max之间称为query window,按照Google实际业务经验,这个query window一般相差在10小时左右。
三、Lightning server内数据是如何维护的。
Lightning会把tables、indexes、views都看作是独立的table维护,称为Lightning table。Lightning table会按照key range去做分区,每个partition内部维护着多颗LSM树,每颗这样的LSM树称为Delta。顾名思义,Delta只包括着部分待完全固化的数据,包括Insert、Update、Delete及它们对应的timestamp。
Delta会分为两部分,内存delta和disk delta。内存delta是用面向行存的B-tree实现的,依旧选择行存的原因是对插入友好。一旦数据写到行存就可以被访问了,但此时数据未持久化(没有WAL),一旦失败,recover就得从OLTP那边replay日志。这里隐含的一个实现相关没有提及的问题是,OLTP删除过期数据可能会受到Lightning实现反馈限制。memory的flush是周期性的,而且由于期望flush的性能,所以memory delta的持久化不会有数据格式转换,依然是按照行存b-tree关系下刷。因此,memory delta的持久化不可读,每次recover需要整个delta load回内存才能访问。因此这里要区分memory delta的持久化与disk delta的区别。memory delta持久化达到空间阈值的时候会触发compaction,将其行转列,压成真正的disk delta格式。disk delta是列存存储的格式,Lightning的定义中并未定义disk delta具体实现,而是定义了抽象的接口去支持不同的列存格式实现。但现在线上仅支持一种内置实现,这种实现并不是完全面向AP查询,而是针对hybrid的workload做了tradeoff,对range scan和点查询也比较友好。
Delta的compaction被分为四种:
- active compaction: 指将memory delta 压成disk delta的过程,cheap and fast。
- minor compaction:作用于版本和操作压缩,但只会处理一些小或较新的数据。
- major compaction:和minor类似,但面向大或旧的数据。
- base compaction:purge功能,将小于min safe timestamp的压成一个快照,使得小于这个版本的多版本数据可以被清除。
四、DDL与Schema。
Lightning引入了逻辑Schema和物理Schema的概念,逻辑Schema就是我们熟知的SQL schema,物理Schema则是表达逻辑Scheme的types的存储格式,比如date、time会映射成整型等。物理Schema保证只有原子类型(int、float、string等)。这么做的好处一个是存储类型变得简单,第二个是可以灵活支持不同的上层逻辑layout并赋予列存能力(如果是行存,比如protobuf,可能直接序列化bytes即可),第三个则是解耦。
比如常见的DDL是add column或drop column,此时逻辑Schema会跟着发生变化,但是物理Schema可以暂时不用变(因为数据变动开销、更早的版本还在被读等原因)。Lightning会构建一个叫schema-adapted logical mappings 的映射,它可以告诉Lightning怎样将一个处于旧逻辑Schema下的物理Schema去在需要时转换成新逻辑Schema下的数据,反过来亦然。但像create new table这类DDL是没办法用这个映射解决的,Lightning需要创建一个initial snapshot来初始化一个新表的状态。
当然,DDL可能会持续发生变化,mappings只是解过渡数据,最终物理数据的变化会依靠compaction去将旧的物理Schema转成新的物理Schema的数据。这里的前提是,compaction会在未来involve所有的数据。所以相比leveled的策略,类似HBase分minor和major的方式会更容易触发旧数据的合并。
ChangePump在从OLTP同步数据的时候会要求每次数据同步带上一个schema version,每个schema version表示OLTP的table发生了一次schema DDL变化。Lightning有两种方式去检测schema变化:lazy detection and eager detection。
- lazy detection: lazy就是仅检查change,当change里的schema vesion变化了,才去阻塞同步(partition级别)并更新schema。这种方式的堵塞会对refreshness造成较大影响。
- eager detection: 起一个后台线程去polling OLTP的schema变化情况。
Lightning的策略是lazy和eager结合。
其他一些细节点:
-
Transparent query rewrites
查询都是走F1 Query进入的,RO queries会需要指定read timestamp,一般应用会选择F1 Query默认pick的一个recent timestamp (query safe timestamp),但也可支持query window内的多版本读。F1 Query选择开启Lightning后,并非一定就会将查询转发给Lightning,而是在优化器将Logical plan转成Physical plan的过程中作为新的access path加入代价评估。
-
Subplan pushdown
如果F1 Query优化器选择了Lightning的path,则同时会进一步做subplan下推等执行引擎相关的特殊优化。和其他大多数数据库的下推一样,这里所谓的subplan依然是一个不涉及data shuffle的pipeline,仅有filter、projection、partial aggregation等。但由于Lightning是个列存存储引擎,F1 Query需要加入一个面向向量化和列存的evaluator,才能最大化列存下推的效果。