STL的sort()算法,数据量大时采用Quick Sort,分段递归排序,一旦分段后的数据量小于某个门槛,为避免Quick Sort的递归调用带来过大的额外负荷,就改用Insertion Sort。如果递归层次过深,还会改用Heap Sort。本文先分别介绍这个三个Sort,再整合分析STL sort算法(以上三种算法的综合) -- Introspective Sorting(内省式排序)。
一、Insertion Sort
Insertion Sort是《算法导论》一开始就讨论的算法。它的基本原理是:将初始序列的第一个元素作为一个有序序列,然后将剩下的N-1个元素按关键字大小依次插入序列,并一直保持有序。这个算法的复杂度为O(N^2),最好情况下时间复杂度为O(N)。在数据量很少时,尤其还是在序列“几近排序但尚未完成”时,有着很不错的效果。
Insertion Sort
// 默认以渐增方式排序
template <class RandomAccessIterator>
void __insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (first == last) return;
// --- insertion sort 外循环 ---
for (RandomAccessIterator i = first + 1; i != last; ++i)
__linear_insert(first, i, value_type(first));
// 以上,[first,i) 形成一个子区间
}
template <class RandomAccessIterator, class T>
inline void __linear_insert(RandomAccessIterator first,
RandomAccessIterator last, T*)
{
T value = *last; // 记录尾元素
if (value < *first){ // 尾比头还小 (注意,头端必为最小元素)
copy_backward(first, last, last + 1); // 将整个区间向右移一个位置
*first = value; // 令头元素等于原先的尾元素值
}
else // 尾不小于头
__unguarded_linear_insert(last, value);
}
template <class RandomAccessIterator, class T>
void __unguarded_linear_insert(RandomAccessIterator last, T value)
{
RandomAccessIterator next = last;
--next;
// --- insertion sort 内循环 ---
// 注意,一旦不再出现逆转对(inversion),循环就可以结束了
while (value < *next){ // 逆转对(inversion)存在
*last = *next; // 调整
last = next; // 调整迭代器
--next; // 左移一个位置
}
*last = value; // value 的正确落脚处
}
上述函数之所以命名为unguarded_x是因为,一般的Insertion Sort在内循环原本需要做两次判断,判断是否相邻两元素是”逆转对“,同时也判断循环的行进是否超过边界。但由于上述所示的源代码会导致最小值必然在内循环子区间的边缘,所以两个判断可合为一个判断,所以称为unguarded_。省下一个判断操作,在大数据量的情况下,影响还是可观的。
二、Quick Sort
Quick Sort是目前已知最快的排序法,平均复杂度为O(NlogN),可是最坏情况下将达O(N^2)。
Quick Sort算法可以叙述如下。假设S代表将被处理的序列:
1、如果S的元素个数为0或1,结束。
2、取S中的任何一个元素,当做枢轴(pivot) v。
3、将S分割为L、R两段,使L内的每一个元素都小于或等于v,R内的每一个元素都大于或等于v。
4、对L、R递归执行Quick Sort。
Median-of-Three(三点中值)
因为任何元素都可以当做枢轴(pivot),为了避免元素输入时不够随机带来的恶化效应,最理想最稳当的方式就是取整个序列的投、尾、中央三个元素的中值(median)作为枢轴。这种做法称为median-of-three partitioning。
Quick Sort
// 返回 a,b,c之居中者
template <class T>
inline const T& __median(const T& a, const T& b, const T& c)
{
if (a < b)
if (b < c) // a < b < c
return b;
else if (a < c) // a < b, b >= c, a < c --> a < b <= c
return c;
else // a < b, b >= c, a >= c --> c <= a < b
return a;
else if (a < c) // c > a >= b
return a;
else if (b < c) // a >= b, a >= c, b < c --> b < c <= a
return c;
else // a >= b, a >= c, b >= c --> c<= b <= a
return b;
}
Partitioning(分割)
分割方法有很多,以下叙述既简单又有良好成效的做法。令first向尾移动,last向头移动。当*first大于或等于pivot时停下来,当*last小于或等于pivot时也停下来,然后检验两个迭代器是否交错。未交错则元素互相,然后各自调整一个位置,再继续相同行为。若交错,则以此时first为轴将序列分为左右两半,左边值都小于或等于pivot,右边都大于等于pivot
Partitioning
template <class RandomAccessIterator, class T>
RandomAccessIterator __unguarded_partition(
RandomAccessIterator first,
RandomAccessIterator last,
T pivot)
{
while(true){
while (*first < pivot) ++first; // first 找到 >= pivot的元素就停
--last;
while (pivot < *last) --last; // last 找到 <=pivot
if (!(first < last)) return first; // 交错,结束循环
// else
iter_swap(first,last); // 大小值交换
++first; // 调整
}
}
三、Heap Sort
STL中有一个partial_sort()算法。
Heap Sort
// paitial_sort的任务是找出middle - first个最小元素。
template <class RandomAccessIterator>
inline void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last)
{
__partial_sort(first, middle, last, value_type(first));
}
template <class RandomAccessIterator,class T>
inline void __partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last, T*)
{
make_heap(first, middle); // 默认是max-heap,即root是最大的
for (RandomAccessIterator i = middle; i < last; ++i)
if (*i < *first)
__pop_heap(first, middle, i, T(*i), distance_type(first));
sort_heap(first,middle);
}
partial_sort的任务是找出middle-first个最小元素,因此,首先界定出区间[first,middle),并利用make_heap()将它组织成一个max-heap,然后就可以讲[middle,last)中的每一个元素拿来与max-heap的最大值比较(max-heap的最大值就在第一个元素);如果小于该最大值,就互换位置并重新保持max-heap的状态。如此一来,当我们走遍整个[middle,last)时,较大的元素都已经被抽离出[first,middle),这时候再以sort_heap()将[first,middle)做一次排序。
由于篇幅有限,本文不再阐述堆的具体实现,建议海量Google。
四、IntroSort
不当的枢轴选择,导致不当的分割,导致Quick Sort恶化为O(N^2)。David R. Musser于1996年提出一种混合式排序算法,Introspective Sorting。其行为在大部分情况下几乎与 median-of-3 Quick Sort完全相同。但是当分割行为(partitioning)有恶化为二次行为倾向时,能自我侦测,转而改用Heap Sort,使效率维持在O(NlogN),又比一开始就使用Heap Sort来得好。大部分STL的sort内部其实就是用的IntroSort。
Intro Sort
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (first != last){
__introsort_loop(first, last, value_type(first), __lg(last-first)*2);
__final_insertion_sort(first,last);
}
}
// __lg()用来控制分割恶化的情况
// 找出2^k <= n 的最大值,例:n=7得k=2; n=20得k=4
template<class Size>
inline Size __lg(Size n)
{
Size k;
for (k = 0; n > 1; n >>= 1)
++k;
return k;
}
// 当元素个数为40时,__introsort_loop的最后一个参数
// 即__lg(last-first)*2是5*2,意思是最多允许分割10层。
const int __stl_threshold = 16;
template <class RandomAccessIterator, class T, class Size>
void __introsort_loop(RandomAccessIterator first,
RandomAccessIterator last, T*,
Size depth_limit)
{
while (last - first > __stl_threshold){ // > 16
if (depth_limit == 0){ // 至此,分割恶化
partial_sort(first, last, last); // 改用 heapsort
return;
}
--depth_limit;
// 以下是 median-of-3 partition,选择一个够好的枢轴并决定分割点
// 分割点将落在迭代器cut身上
RandomAccessIterator cut = __unguarded_partition
(first, last, T(__median(*first,
*(first + (last - first)/2),
*(last - 1))));
// 对右半段递归进行sort
__introsort_loop(cut,last,value_type(first), depth_limit);
last = cut;
// 现在回到while循环中,准备对左半段递归进行sort
// 这种写法可读性较差,效率也并没有比较好
}
}
函数一开始就判断序列大小,通过个数检验之后,再检测分割层次,若分割层次超过指定值,就改用partial_sort(),即Heap sort。都通过了这些校验之后,便进入与Quick Sort完全相同的程序。
当__introsort_loop()结束,[first,last)内有多个“元素个数少于或等于”16的子序列,每个序列有相当程序的排序,但尚未完全排序(因为元素个数一旦小于 __stl_threshold,就被中止了)。回到母函数,再进入__final_insertion_sort():
template <class RandomAccessIterator>
void __final_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (last - first > __stl_threshold){
// > 16
// 一、[first,first+16)进行插入排序
// 二、调用__unguarded_insertion_sort,实质是直接进入插入排序内循环,
// *参见Insertion sort 源码
__insertion_sort(first,first + __stl_threshold);
__unguarded_insertion_sort(first + __stl_threshold, last);
}
else
__insertion_sort(first, last);
}
template <class RandomAccessIterator>
inline void __unguarded_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
__unguarded_insertion_sort_aux(first, last, value_type(first));
}
template <class RandomAccessIterator, class T>
void __unguarded_insertion_sort_aux(RandomAccessIterator first,
RandomAccessIterator last,
T*)
{
for (RandomAccessIterator i = first; i != last; ++i)
__unguarded_linear_insert(i, T(*i));
}
必须要看清楚的是,__final_insertion_sort()之前,经过__introsort_loop()的整个序列可以看成是一个个元素个数小于或等于16的子序列(注意子序列长度是不等的),且这些子序列不但内部有相当程度排序,且更重要的是以子序列与子序列之间也是“递增”的,意思是前一个子序列中的元素都是小于后一个子序列中的元素的,所以这个时候运用insertion_sort(),效率可是相当高的。
/---------------------------------------华丽的分割线--------------------------------------/
关于IntroSort的测试。
细看__introsort_loop(),是不是觉得他的快排的写法很怪,为什么不能直接这样写呢?
if (last - first > __stl_threshold){ // > 16
...
...
__introsort_loop(cut,last,value_type(first), depth_limit);
__introsort_loop(first,cut,value_type(first), depth_limit);
结果如下图:
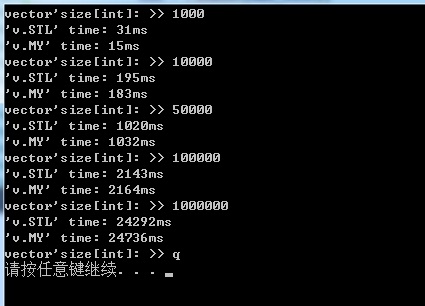
测试结果发现,如果不像STL中那么写,其实在数组还比较小时,还快那么一丁点,
并且即使数组变大,在一百万条记录时也只快0.3秒,唔。。也许STL更注重于大型数据吧,
不过像他那么写,实在是牺牲了代码的可读性。
为什么是Insertion Sort,而不是Bubble Sort。
选择排序(Selection sort),插入排序(Insertion Sort),冒泡排序(Bubble Sort)。这三个排序是初学者必须知道的三个基本排序方式,且他们速度都不快 -- O(N^2)。选择排序就不说了,最好情况复杂度也得O(N^2),且还是个不稳定的排序算法,直接淘汰。
可冒泡排序和插入排序相比较呢?
首先,他们都是稳定的排序算法,且最好情况下都是O(N^2)。那么我就来对他们的比较次数和移动元素次数做一次对比(最好情况下),如下:
插入排序:比较次数N-1,移动元素次数2N-1。
冒泡排序:比较次数N-1,无需移动元素。(注:我所说的冒泡排序在最基本的冒泡排序基础上还利用了一下旗帜的方式,即寻访完序列未发生数据交换时则表示排序已完成,无需再进行之后的比较与交换动作)
那么,这样看来冒泡岂不是是更快,我可以把上述的__final_insertion_sort()函数改成一个__final_bubble_sort(),把每个子序列分别进行冒泡排序,岂不是更好?
事实上,具体实现时,我才发现这个想法错了,因为写这么一个__final_bubble_sort(),我没有办法确定每个子序列的大小,可我还是不甘心呐,就把bubble_sort()插在__introsort_loop()最后,这样确实是每个子序列都用bubble_sort()又排序了一次,可是测试结果太惨了,由此可以看书Bubble Sort在“几近排序但尚未完成”的情况下是没多少改进作用的。
为什么不直接用Heap Sort
堆排序将所有的数据建成一个堆,最大的数据在堆顶,它不需要递归或者多维的暂存数组。算法最优最差都是O(NlogN),不像快排,如果你人品够差还能恶化到O(N^2)。当数据量非常大时(百万数据),因为快排是使用递归设计算法的,还可能发出堆栈溢出错误呢。
那么为什么不直接用Heap Sort?或者说给一个最低元素阈值(__stl_threshold)时也给一个最大元素阈值(100W),即当元素数目超过这个值时,直接用Heap Sort,避免堆栈溢出呢?
对于第一个问题,我测试了一下,发现直接用Heap Sort,有时还没有Quick Sort快呢,查阅《算法导论》发现,原来虽然Quick和Heap的时间复杂性是一样的,但堆排序的常熟因子还是大些的,并且堆排序过程中重组堆其实也不是个省时的事。