基本概念
字符:表示数据和信息的字母、数字或其他符号。在电子计算机中,每一个字符与一个二进制编码相对应。
字符的标识(码位):是0-1114111的数字,在Unicode标准中以4-6个十六进制数字表示,而且加前缀“U+”。例如,字母A的码位是U+0041,欧元符号的码位是U+20AC.
字符的具体表述取决于所用的编码。编码是在码位和字节序列之间转换时使用的算法。在UTF-8编码中,A(U+0041)的码位编码成单个字节x41,而在UTF-16LE编码中编码成两个字节x41x00。欧元符号(U+20AC)在UFT-8编码中是三个字节xe2x82xac,而在UTF-16LE编码中编码成两个字节xacx20。
编码:把码位转换成字节序列(通俗来说:把字符串转换成用于存储或传输的字节序列,python中是.encode())
解码:把字节序列转换成码位(通俗来说:把字节序列转换成人类可读的文本字符串,python中是.decode())
>>> s = 'café' >>> len(s) # Unicode字符数量 4 >>> b = s.encode('utf8') # 编码为bytes >>> b b'cafxc3xa9' >>> len(b) # 字节数 5 >>> b.decode('utf8') # 解码 'café
字节概要
新的二进制序列类型在很多方面与 Python 2 的 str 类型不同。首先要知道,Python 内置了两种基本的二进制序列类型:Python 3 引入的不可变bytes 类型和 Python 2.6 添加的可变 bytearray 类型。(Python 2.6 也引入了 bytes 类型,但那只不过是 str 类型的别名,与 Python 3 的bytes 类型不同。)
bytes 或 bytearray 对象的各个元素是介于 0~255(含)之间的整数,而不像 Python 2 的 str 对象那样是单个的字符。然而,二进制序列的切片始终是同一类型的二进制序列,包括长度为 1 的切片,如示例:
>>> cafe = bytes('café', encoding='utf_8') >>> cafe b'cafxc3xa9' >>> cafe[0] >>> cafe[:1] b'c' >>> cafe_arr = bytearray(cafe) >>> cafe_arr bytearray(b'cafxc3xa9') >>> cafe_arr[-1:] bytearray(b'xa9')
二进制序列有个类方法是 str 没有的,名为 fromhex,它的作用是解析十六进制数字对(数字对之间的空格是可选的),构建二进制序列:
>>> bytes.fromhex('31 4B CE A9') b'1Kxcexa9'
python基本编码解码器
python自带了超过100种编码解码器,用于在文本和字节中转换。每个编码解码器有一个名称,如'utf-8',通常有几个别名如'utf-8'别名有'utf8'、''utf_8、'U8'。
ISO-8859-1(latin1):该编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
cp1252:ISO-8859-1的超集,添加了一些有用的符号。
cp437:IBM PC最初的字符集,包含框图符号,于ISO-8859-1不兼容。
gb2312:简体中文陈旧标准,亚洲语言使用较广泛的多字节编码。
utf-8:目前Web中最常见的8位编码;与ASCII兼容。
utf-16le:UTF-16的16位编码方案的一种形式;所有UTF-16支持转义序列表示超过U+FFFF的码位。
编码存在的问题
处理UnicodeError
多数非 UTF 编解码器只能处理 Unicode 字符的一小部分子集。把文本转换成字节序列时,如果目标编码中没有定义某个字符,那就会抛出UnicodeEncodeError 异常,除非把 errors 参数传给编码方法或函数,对错误进行特殊处理。
city = 'São Paulo' u8 = city.encode('utf_8') print('utf-8:', u8) #结果: utf-8: b'Sxc3xa3o Paulo' 'utf_?' 编码能处理任何字符串
u16 = city.encode('utf_16') print('utf-16:', u16) #结果: utf-16: b'xffxfeSx00xe3x00ox00 x00Px00ax00ux00lx00ox00'
iso = city.encode('iso8859_1') print('iso:', iso) #结果: iso: b'Sxe3o Paulo' 'iso8859_1' 编码也能处理字符串 'São Paulo
cpr37 = city.encode('cp437') #结果: 报错 'cp437' 无法编码 'ã'(带波形符的“a”)
cp_ig = city.encode('cp437', errors='ignore') print('cp ignore:', cp_ig) #结果: cp ignore: b'So Paulo'
cp_rp = city.encode('cp437', errors='replace') print('cp replace:', cp_rp) #结果: cp replace: b'S?o Paulo'
如上处理策略:
1.error='ignore' 处理方式悄无声息地跳过无法编码的字符;这样做通常很是不妥
2.编码时指定error='replace',把无法编码的字符替换成'?';数据损坏了,但是用户知道出现了问题
3.把errors参数注册额外字符串,方法是把一个名称和一个错误处理函数传递给codes.register_error函数。(参考python标准库)
处理UnicodeDecodeError
不是每个字节都包含有效的ASCALL字符,也不是每个字符序列都是有效的UTF-8或UTF16。因此,把二进制序列转换为文本时,如果假设是这两个编码中的一个,遇到无法转换的字节序列时会抛出UnicodeDecodeError。
octets = b'Montrxe9al' #iso8859_1编码 cp1252 = octets.decode('cp1252') print(cp1252) #结果:Montréal 正确解码 cp1252是iso8859_1的超集 iso = octets.decode('iso8859_7') print(iso) #结果:Montrιal 错误解码 koi8_r = octets.decode('koi8_r') print(koi8_r) #结果:MontrИal 错误解码 #utf_8 = octets.decode('utf-8') print(utf_8) #结果:异常 不是有效的utf-8字符串 new_utf_8 = octets.decode('utf-8', errors='replace') print(new_utf_8) #结果:Montr�al 官方指定的错误处理方式
处理SyntaxError
python3默认使用utf-8编码源码,如果加载的模块中包含utf-8之外的数据,而且没有声明编码,则会抛出SyntaxError异常。linux和OS X系统大都使用utf-8,因此在打开windows系统中使用cp1252编码的.py文件可能发生这种情况。
为了修正这个问题,可以在文件顶部添加一个神奇的coding注释, coding:cp1252
判断文件字节序列编码
使用命令行工具chardetect(python库Chardet提供的)
处理文本文件
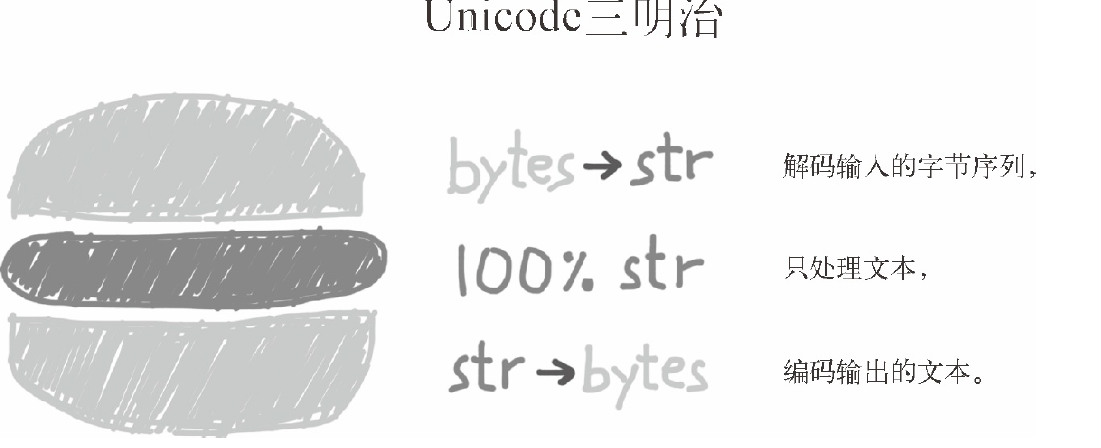
处理文本的最佳实践是“Unicode 三明治”(如图下图所示)。 意思是,要尽早把输入(例如读取文件时)的字节序列解码成字符串。这种三明治中的“肉片”是程序的业务逻辑,在这里只能处理字符串对象。在其他处理过程中,一定不能编码或解码。对输出来说,则要尽量晚地把字符串编码成字节序列。多数 Web 框架都是这样做的,使用框架时很少接触字节序列。例如,在 Django 中,视图应该输出 Unicode 字符串;Django 会负责把响应编码成字节序列,而且默认使用 UTF-8 编码。
#打开一个文件cafe.txt并写入内容,w是对文件的模式操作(写操作), encoding是对文件操作的编码 fp = open('cafe.txt', 'w', encoding='utf_8') fp_len = fp.write('café') print('fp的io信息:', fp) print('写入到文件中内容的长度:', fp_len) fp.close() #获取文件的内容 fp2 = open('cafe.txt') print('fp2的io信息:', fp2) ''' 因为和上面的写入的编码不同,所以直接以默认的编码打开,无法处理é而引发异常 ''' #print(fp2.read()) fp2.close() #解决fp2无法或许文件内容的方法指定打开的时候编码 fp3 = open('cafe.txt', encoding='utf-8') print('fp3的io信息:', fp3) print('fp3中的文件内容:', fp3.read()) fp3.close() fp4 = open('cafe.txt', 'rb') print('fp4的io信息:', fp4) print('fp4的文件内容:', fp4.read().decode('utf-8')) fp4.close() #另外一种不太可取的解决方案, errors可以设置成replace或者ignore fp5 = open('cafe.txt', 'r', errors='ignore') print('fp5的io信息:', fp5) print('fp5的文件内容:', fp5.read())
以上代码结果:
fp的io信息: <_io.TextIOWrapper name='cafe.txt' mode='w' encoding='utf_8'> 写入到文件中内容的长度: 4 fp2的io信息: <_io.TextIOWrapper name='cafe.txt' mode='r' encoding='US-ASCII'> fp3的io信息: <_io.TextIOWrapper name='cafe.txt' mode='r' encoding='utf-8'> fp3中的文件内容: café fp4的io信息: <_io.BufferedReader name='cafe.txt'> fp4的文件内容: café fp5的io信息: <_io.TextIOWrapper name='cafe.txt' mode='r' encoding='US-ASCII'> fp5的文件内容: caf
Unicode规范化
使用unicodedata.normalize提供的nuicode规范化
NFC使用最少码位构成等价的字符串,而NFD把组合字符分解成基字符和单独的组合字符。
>>> s1 = 'café' >>> s2 = 'cafeu0301' >>> s1, s2 ('café', 'café') >>> len(s1), len(s2) (4, 5) >>> s1 == s2 False
实际 é === 'eu0301' 是成立的,而Python 看到的是不同的码位序列,因此判定二者不相等,则需要使用NFC或NFD。
from unicodedata import normalize s1 = 'café' # 把"e"和重音符组合在一起 s2 = 'cafeu0301' # 分解成"e"和重音符 print('s1和s2的长度:', len(s1), len(s2)) print('NFC标准化处理以后的s1,s2的长度:', len(normalize('NFC', s1)), len(normalize('NFC', s2))) print('NFD标准化处理以后的s1,s2的长度:', len(normalize('NFD', s1)), len(normalize('NFD', s2))) print(normalize('NFC', s1), normalize('NFC', s2))
#结果:
s1和s2的长度: 4 5 NFC标准化处理以后的s1,s2的长度: 4 4 NFD标准化处理以后的s1,s2的长度: 5 5 café café