概述
迭代是数据处理的基石,扫描内存中放不下的数据时,我们需要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式。
在python中,所有集合都可以迭代。在python语言内部,迭代器用于支持:
(1)for循环
(2)构建和扩展集合类型
(3)逐行遍历文本文件
(4)列表推导,字典推导和集合推导
(5)元组拆包
(6)调用函数时,用*拆包
python没有宏,因此为了抽象出迭代器模式,需要改动语言本身,为此加入了yield用于构建生成器。所有生成器都是迭代器,反之则不是。迭代器用于从集合中取出元素,而生成器用于凭空产生元素。
iter函数
解释器需要迭代对象x时,会主动调用iter(x)。内置iter函数有以下作用:
(1)检查对象是否实现了__iter__方法,如果实现了就调用它,获取一个迭代器。
(2)如果没有实现__iter__方法,但是实现了_getitem__方法,python会创建一个迭代器,尝试按顺序(从索引0开始)获取元素。
(3)如果尝试失败,python抛出TypeError异常,通常会提示对象不可迭代。
任何序列都可以迭代,其原因是,它们都实现了__getitem__方法。其实,标准的序列也都实现了__iter__方法。
实现了__iter__方法,就认为对象是可以迭代的,此时,不需要创建子类,也不用注册,因为abc.Iterable类实现了__subclasshook__方法。
class Foo: def __iter__(self): pass from collections import abc print(issubclass(Foo, abc.Iterable)) f = Foo() print(isinstance(f, abc.Iterable)) #结果 True True
而只实现了__getitem__方法的类,虽然可以迭代,但是无法通过issubclass测验。
迭代对象之前显示检查对象是否可以迭代或许没有必要,毕竟尝试迭代不可迭代的对象时,会抛出对象不可迭代的异常。如果除了抛出异常还有进一步处理,可以使用try/catch块。
iter函数还可以传入两个参数,使用常规函数或任何可调用对象创建迭代器。这样使用时,第一个参数必须是可调用对象,用于不断调用,产出各个值,另一个值是哨符,这个是标记值,当可调用对象返回这个值时会抛出StopIteration异常,而不产生哨符。
使用iter函数掷筛子,指代掷出1点:
from random import randint def d6(): return randint(1, 6) d6_iter = iter(d6, 1) print(d6_iter) for roll in d6_iter: print(roll) #结果 <callable_iterator object at 0x00000264FD3C54A8> 4 4 2 5 5 5
可迭代对象
可迭代的对象:使用iter内置函数可以获取迭代器的对象。如果对象实现了能返回迭代器的__iter__函数,那么对象就是可以迭代的。序列都可以迭代;实现了__getitem__方法,而且参数是从零开始的索引,这种对象也可以迭代。
可迭代对象与迭代器的关系是:python从可迭代对象中获取迭代器。
迭代一个字符串,'ABC'是可迭代对象,for循环背后是有迭代器的:
s = 'ABC' for char in s: print(char)
如果不用for循环:
s = 'ABC' it = iter(s) #使用可迭代对象构建迭代器it while True: try: print(next(it)) #不断在迭代器上调用next函数,获取下一个字符 except StopIteration: #没有字符会抛出StopIteration del it #废弃迭代器对象 break
StopIteration异常表明迭代器到头了。python语言内部处理for循环和其他迭代上下文(概述中的那些)中的StopIteration异常。
标准迭代器接口有两个方法:
__next__ //返回下一个可用元素,如果没有下一个了,抛出StopIteration异常
__iter__ //返回self,以便在应该使用可迭代对象的地方使用迭代器。
这个接口在collections.abc.Iterator抽象基类中制定。这个类定义了__next__抽象方法,而且继承自Iterable类;__iter__抽象方法则在Iterable类中定义:
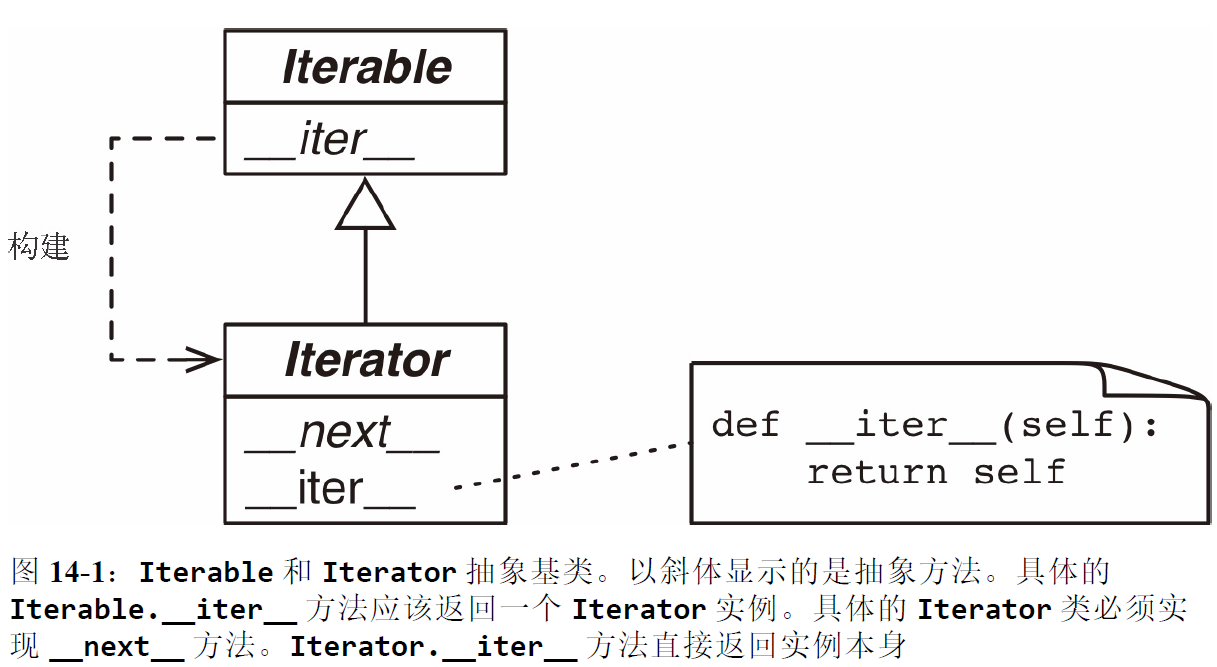
因为迭代器只需 __next__ 和 __iter__ 两个方法,所以除了调用 next() 方法,以及捕获 StopIteration 异常之外,没有办法检查是否还有遗留的元素。此外,也没有办法“还原”迭代器。如果想再次迭代,那就要调用 iter(...),传入之前构建迭代器的可迭代对象。传入迭代器本身没用,因为前面说过 Iterator.__iter__ 方法的实现方式是返回实例本身,所以传入迭代器无法还原已经耗尽的迭代器。
再次给出迭代器定义:
迭代器:实现了无参数的 __next__ 方法,返回序列中的下一个元素;如果没有元素了,那么抛出 StopIteration 异常。Python 中的迭代器还实现了 __iter__ 方法,因此迭代器也可以迭代。
典型的迭代器
使用迭代器模式实现一个类(往类的构造方法中传入包含一些文本的字符串,然后可以逐个单词迭代):
import re import reprlib RE_WORD = re.compile('w+') class Sentence: def __init__(self, text): self.text = text self.words = RE_WORD.findall(text) def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): return SentenceIterator(self.words) #返回一个迭代器 class SentenceIterator: def __init__(self, words): self.words = words #SentenceIterator实例引用单词列表 self.index = 0 #确定下一个要获取的单词 def __next__(self): try: word = self.words[self.index] except IndexError: raise StopIteration() #索引位没有单词,抛出异常 self.index += 1 return word def __iter__(self): return self
对这个示例来说,其实没必要在SentenceIterator类中实现__iter__方法,不过迭代器实现了__iter__和__next__方法后可以通过issubclass(SentenceInterator,abc.Interator)测试。如果让它继承abc.Iterator类,那么它会继承abc.Iterator.__iter__方法。
一定不能将可迭代对象和迭代器混淆,可迭代对象有一个__iter__方法,每次都实例化一个新的迭代器,而迭代器要实现__next__方法返回单个元素,此外还要实现__iter__方法,返回迭代器本身。因此,迭代器可以迭代,可迭代对象不是迭代器。
生成器函数
使用生成器函数代替SentenceIterator类:
import re import reprlib RE_WORD = re.compile('w+') class Sentence: def __init__(self, text): self.text = text self.words = RE_WORD.findall(text) def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): for word in self.words: yield word #产出当前word return #不是必要的
这比前一个迭代器模式少了一个SentenceIterator类。
生成器工作原理
python函数定义体中有yield关键字,即该函数是生成器函数(上面的__iter__函数就是生成器函数),调用生成器函数时,会返回一个生成器对象。简单例子:
def gen_abc(): #函数体中包含yield关键字,就是生成器函数 yield 'a' yield 'b' yield 'c' print(gen_abc) print(gen_abc()) for i in gen_abc(): #调用时,会生成传递给yield关键字的表达式的值 print(i) #结果 <function gen_abc at 0x0000015D77F57F28> #gen_abc是函数对象 <generator object gen_abc at 0x0000015D7F513A98> #调用函数返回一个生成器对象 a b c
调用next()查看:
g = gen_abc() print(next(g)) #g是迭代器,调用next(g)获取yield生成的下一个元素 print(next(g)) print(next(g)) print(next(g)) #结果 a b c StopIteration #元素已生成完毕,抛出异常
惰性实现Sentence类
惰性求值和及早求值是编程语言理论方面的技术术语。无论是上述使用迭代器模式或者生成器函数实现的Sentence类都不具有惰性,因为__init__方法急迫得构建好了文本单词列表,然后将其绑定到self.words属性上。列表耗费了大量内存,如果只需要迭代前几个单词,那么大多数工作都是白费力气。
re.finditer是re.findall的惰性版本,返回的不是列表,而是一个生成器,在一些情况下能够节省大量内存,只在需要的时候产生元素:
import re import reprlib RE_WORD = re.compile('w+') class Sentence: def __init__(self, text): self.text = text def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): for match in RE_WORD.finditer(self.text): yield match.group()
生成器表达式
生成器表达式可以理解为列表推导式的惰性版本,不会急迫得构建列表,而是返回一个生成器,按需惰性生成元素。
对比列表推导式与生成器表达式:
def gen_AB(): print('start') yield 'A' print('continue') yield 'B' print('end') res1 = [x*3 for x in gen_AB()] #列表推导式 for i in res1: print('-->', i) #列表推导式结果 start continue end #列表推导式迫切得迭代生成器对象产生的元素,因此直接先输出了start,continue,end --> AAA --> BBB #for循环迭代输出生成的列表 res2 = (x*3 for x in gen_AB()) #生成器表达式 for i in res2: print('-->', i) #生成器表达式结果 start --> AAA continue --> BBB end #for循环迭代res2时,gen_AB函数体才执行,for循环每次迭代会隐式调用next(),前进到下一个yield语句
同样可以用生成器表达式实现Sentence类(改动__iter__函数):
def __iter__(self): return (match.group() for match in RE_WORD.finditer(self.text))
这里没有生成器函数了(没有yield语句),而是用生成表达式构建生成器,然后将其返回。
生成器函数与生成器表达式各有好处,一般语句复杂时使用生成器函数,简单时使用生成器表达式。
标准库中的生成器函数
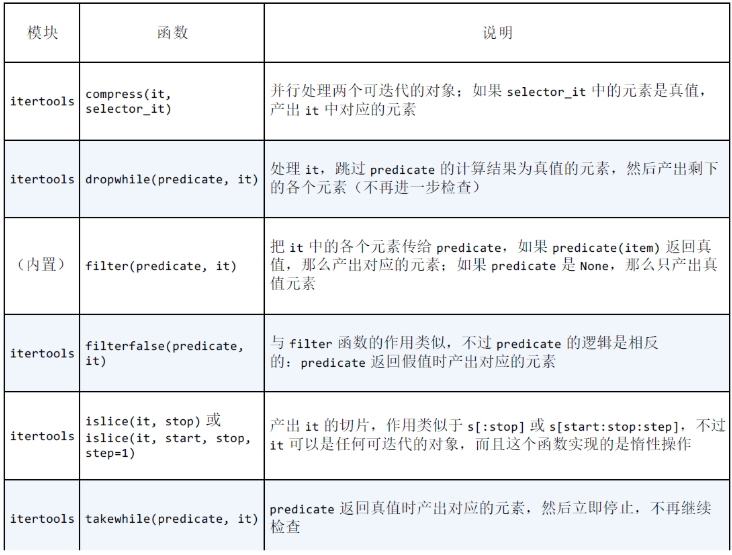
用于过滤的生成器函数:
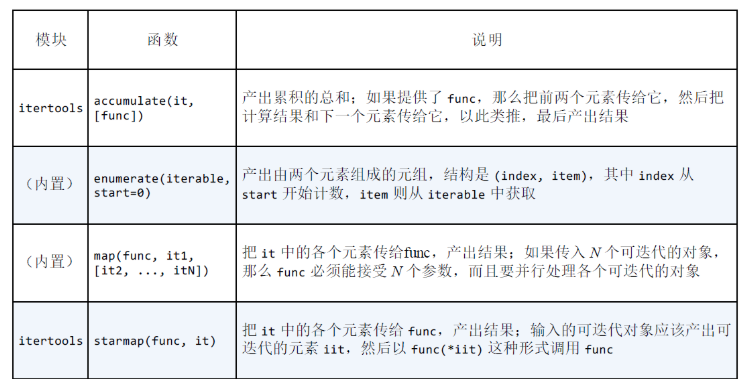
用于映射的生成器函数:
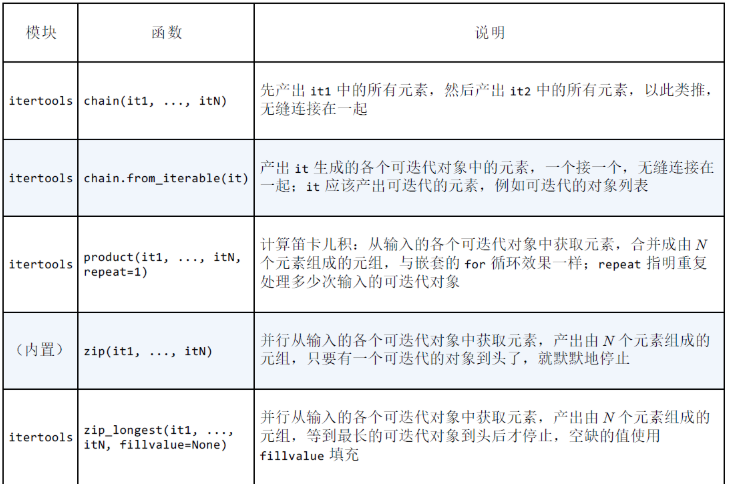
合并多个可迭代对象的生成器函数:
把输入的各个元素扩展成多个输出元素的生成器函数:

用于重新排列元素的生成器函数:
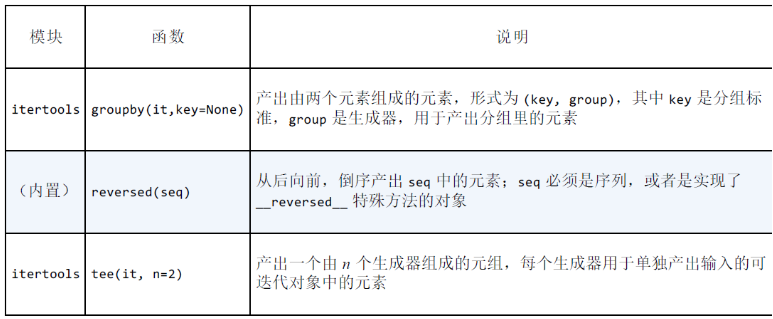
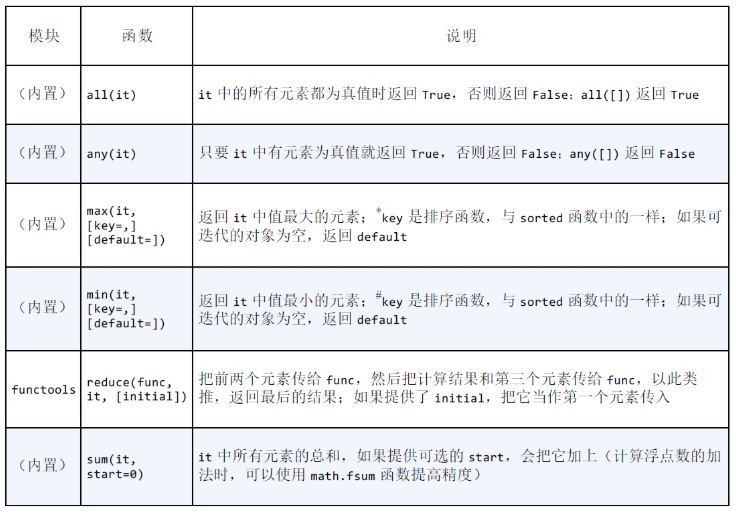
读取迭代器,返回单个值的内置函数:
生成器与迭代器的语义对比
三个方面:
1.接口
python迭代器协议定义了两个方法__next__和__iter__。生成器对象实现了这两个方法,因此,从这方面来看,所有的生成器都是迭代器。
2.实现方式
生成器这种python语言结构可以用两种方式编写:含有yield关键字的函数,或者生成器表达式。调用生成器函数或者执行生成器表达式得到的生成器对象属于语言内部的GeneratorType类型。从这方面看,所有生成器都是迭代器,因为GeneratorType类型的实例实现了迭代器接口。但是却可以编写不是生成器的迭代器,方法是实现经典的迭代器模式。
3.概念
在典型的迭代器设计模式中,迭代器用于遍历集合,从中产生元素。迭代器可能相当复杂,例如遍历树状数据结构。但是,不管典型的迭代器中有多烧逻辑,都是从现有的数据源中读取值;而且,调用next(it)时,迭代器不能修改从数据源中读取的 值,只能原封不动地产出值。
而生成器可能无需遍历集合就能生成值,例如range函数,即便依附集合,生成器不仅能产生集合中的元素,还可能产出派生自元素的其他值。从这方面讲,生成器不都是迭代器。
从概念方面来说,不使用生成器对象也能编写生成器
以上来自《流畅的python》