0x01:selenium的应用场景
有时候我们在网页的源代码里面不能找到在页面中展示的内容,比如这和新闻页面,https://www.toutiao.com/a6729041718571696653/,并不能再源代码里面找到前端展示出来的图片信息,但是右键检查元素却可以定位到元素的位置。这是因为页面展示的数据并不在源代码中,而是经过js加载的,所以并不能直接从源代码中提取出我们需要的数据,这时候,就可以使用selenium打造一个浏览器爬虫。用代码的方式去模拟浏览器操作过程(如:打开浏览器、在输入框里输入文字、回车等),在爬虫方面很有必要。
0x02:准备工作
- 安装selenium(pip install selenium)
- 安装chromedriver(一个驱动程序,用以启动chrome浏览器,具体的驱动程序需要对应的驱动,在官网上可以找到下载地址),可以参考上篇随笔。
0x03:基本使用
1 from selenium import webdriver # 导入模块 2 3 browser = webdriver.Chrome() # 创建一个webdriver实例,并选择使用的浏览器 4 browser.get('https://www.baidu.com/') # 使用get方法访问目标url 5 browser.close() # 关闭网页
使用chrome浏览器,打开百度,并进行关闭。selenium支持各种常见的浏览器,但chrome功能强大,推荐大家使用这个。
0x04:获取js渲染后的网页源代码
一些经过js渲染的页面,是无法在网页的源代码中找到在前端展示的内容的。这时候,就需要获取到js选然后的网页源代码,以上面那个新闻的url为例,右键检查一下第一张图片元素,复制它的链接,

然后右键查看网页源代码,对这个图片链接进行搜索,可以看到结果为0。
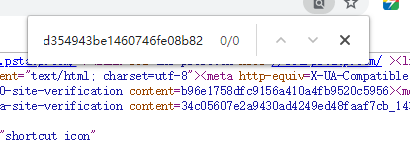
用pycharm获取js选然后的源代码在进行搜索,就能够找到这个图片的链接

代码如下:
1 from selenium import webdriver 2 3 browser = webdriver.Chrome() 4 browser.get('https://www.toutiao.com/a6729041718571696653/') 5 print(browser.page_source) 6 browser.close()
0x05:元素查找
selenium支持很多元素选取的方法,比如:
- find_element_by_id 通过标签的id属性,查找元素
- find_element_by_name 通过标签的name属性查找元素
- find_element_by_xpath 通过xpath查找元素
- find_element_by_tag_name 通过元素的标签名称来查找元素。
- find_element_by_class_name 通过元素的class名查找元素
- find_element_by_css_selector 通过css查找元素
https://www.cnblogs.com/qingchunjun/p/4208159.html,这篇文章有详细的讲解。
获取到js渲染后的源代码之后,就可以对需要的信息进行提取,比如我们想要提取出上面那个图片的链接,可以先右键检查一下元素。

发现它在一个class为pgc-img的div标签下的img标签内,可以使用下面代码对这个图片链接进行获取
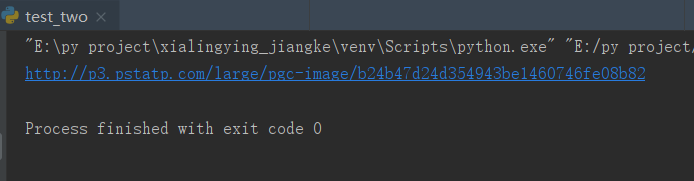
1 from selenium import webdriver 2 3 browser = webdriver.Chrome() 4 browser.get('https://www.toutiao.com/a6729041718571696653/') 5 div_image = browser.find_element_by_css_selector('.pgc-img').find_element_by_xpath('./img').get_attribute('src') 6 print(div_image) 7 browser.close()
第五行代码,先使用css查找的方法找到了包含img标签的div标签,后面接着用xpath方法找到了img标签,最后利用get_attribute获取img的src属性,这样就提取出了第一i张图片的链接。
0x06:多元素查找
上面只查找到了第一张图片的链接,但如果需要获取到所有图片的链接呢?
首先还是对图片元素进行检查,发现每张图片都在一个class为pgc-img的div标签中,那只要获取到这些div标签,就可以进一步获取到每一张图片的链接了。代码如下
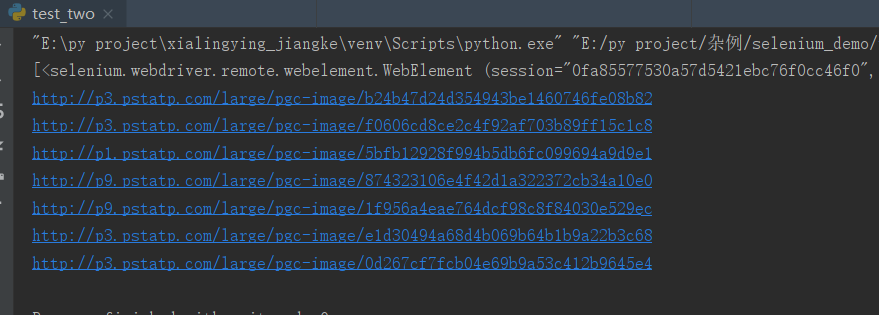
1 from selenium import webdriver 2 3 browser = webdriver.Chrome() 4 browser.get('https://www.toutiao.com/a6729041718571696653/') 5 div_image = browser.find_elements_by_css_selector('.pgc-img') 6 print(div_image) 7 for img in div_image: 8 img_url = img.find_element_by_xpath('./img').get_attribute('src') 9 print(img_url) 10 browser.close()
更改查询方法为find_elements,查找出了所有class为pgc-img的元素,返回对象是一个列表,然后依次对列表里面的元素尽心遍历,查找出每一张图片的链接,结果如图所示
0x07:页面交互
仅仅抓取页面没有多大卵用,我们真正要做的是做到和页面交互,比如点击,输入等等。那么前提就是要找到页面中的元素。可以利用上面说的那些方法,例如下面有一个表单输入框。
<input type="text" name="passwd" id="passwd-id" />
我们可以这样获取它:
1 element = driver.find_element_by_id("passwd-id") 2 element = driver.find_element_by_name("passwd") 3 element = driver.find_elements_by_tag_name("input") 4 element = driver.find_element_by_xpath("//input[@id='passwd-id']")
获取了元素之后,下一步当然就是向文本输入内容了,可以利用下面的方法:
element.send_keys("and some", Keys.ARROW_DOWN)
你可以对任何获取到到元素使用 send_keys 方法,就像你在 GMail 里面点击发送键一样。不过这样会导致的结果就是输入的文本不会自动清除。所以输入的文本都会在原来的基础上继续输入。你可以用下面的方法来清除输入文本的内容。
element.clear()
这样,输入的文本就会被清除了
0x08:页面等待
这是非常重要的一部分,现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。这会让元素定位困难而且会提高产生 ElementNotVisibleException 的概率。
所以 Selenium 提供了两种等待方式,一种是隐式等待,一种是显式等待。
隐式等待是等待特定的时间,显式等待是指定某一条件直到这个条件成立时继续执行。
显式等待
显式等待指定某个条件,然后设置最长等待时间。如果在这个时间还没有找到元素,那么便会抛出异常了。
1 from selenium import webdriver 2 from selenium.webdriver.common.by import By 3 from selenium.webdriver.support.ui import WebDriverWait 4 from selenium.webdriver.support import expected_conditions as EC 5 6 driver = webdriver.Chrome() 7 driver.get("http://somedomain/url_that_delays_loading") 8 try: 9 element = WebDriverWait(driver, 10).until( 10 EC.presence_of_element_located((By.ID, "myDynamicElement")) 11 ) 12 finally: 13 driver.quit()
程序默认会 500ms 调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。
隐式等待
隐式等待比较简单,就是简单地设置一个等待时间,单位为秒。
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) # seconds driver.get("http://somedomain/url_that_delays_loading") myDynamicElement = driver.find_element_by_id("myDynamicElement")
文章参考:https://cuiqingcai.com/2599.html
纸上得来终觉浅,绝知此事要躬行。
******************************不积跬步无以至千里。******************************