turbine源码分析
1、turbine架构设计
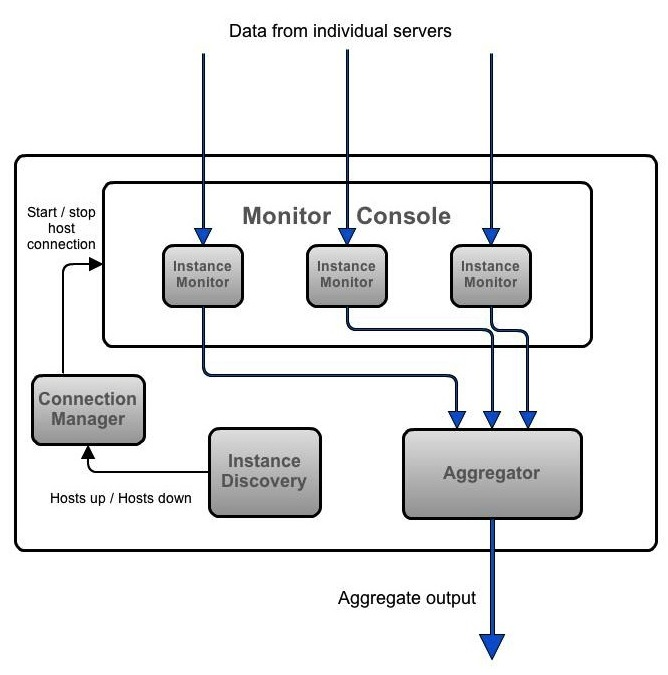
一切从InstanceDiscovery模块开始,该模块提供所有的主机信息。它会定期的发送更新,ConnectionManager 负责创建连接到主机。一旦建立起连接,数据流将源源不断的发送给Aggregator既聚合器。聚合器将数据汇聚后的数据输出到客户端或者下游监听者。
汇聚示例:
{type:'weather-data-temp', name:'New York', temp:74}
{type:'weather-data-temp', name:'Los Angeles', temp:85}
{type:'weather-data-temp', name:'New York', temp:76}
{type:'weather-data-wind-velocity', name:'New York', temp:12}
{type:'weather-data-wind-velocity', name:'Los Angeles', temp:10}
比如有一组这样的数据,经过汇聚后得到下面的结果
{type:'weather-data-temp', name:'Los Angeles', temp:85}
{type:'weather-data-temp', name:'New York', temp:75}
{type:'weather-data-wind-velocity', name:'New York', temp:12}
{type:'weather-data-wind-velocity', name:'Los Angeles', temp:10}
说明:它是使用type和name做为关键字,进行数据汇聚的
2、实例发现
我们先来看看的架构图
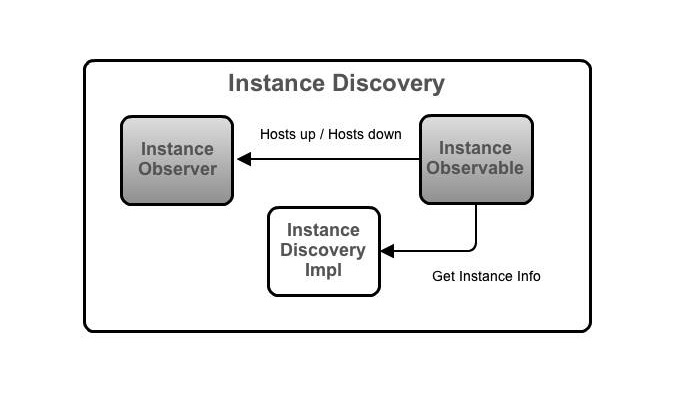
turbine通过配置文件,配置需要收集指标的应用。InstanceObservable定期的拉取实例信息,通知InstanceObserver进行主机信息的更新。turbine只有在主机是UP的状态的时候,才会去连接主机获取指标。这么做的原因是很多复杂的系统在他们将自己标记为可用之前,需要通过长时间的启动引导做一些预处理,比如查询缓存、建立主机连接、运行预计算逻辑等。我们通过分析代码的结构也可以看到
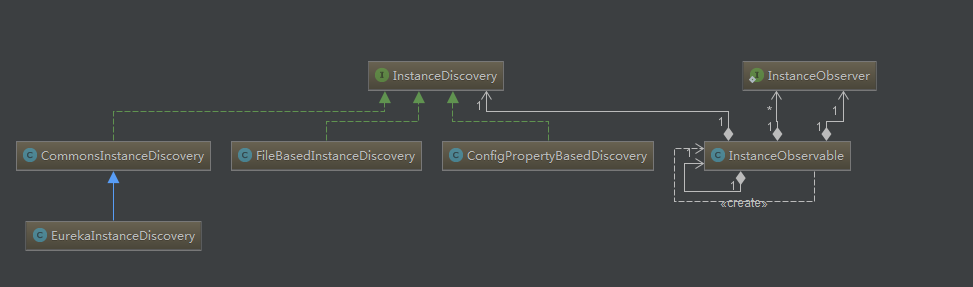
turbine启动的时候会调用TurbineInit的init()方法进行初始化
public static void init() {
ClusterMonitorFactory clusterMonitorFactory = PluginsFactory.getClusterMonitorFactory();
if(clusterMonitorFactory == null) {
PluginsFactory.setClusterMonitorFactory(new DefaultAggregatorFactory());
}
PluginsFactory.getClusterMonitorFactory().initClusterMonitors();
InstanceDiscovery instanceDiscovery = PluginsFactory.getInstanceDiscovery();
if (instanceDiscovery == null) {
PluginsFactory.setInstanceDiscovery(getInstanceDiscoveryImpl());
}
//调用start()方式,初始化实例发现
InstanceObservable.getInstance().start(PluginsFactory.getInstanceDiscovery());
}
start()方法如下:
public void start(InstanceDiscovery iDiscovery) {
if (started.get()) {
throw new RuntimeException("InstanceDiscovery already started");
}
if (iDiscovery == null) {
throw new RuntimeException("InstanceDiscovery is null");
}
instanceDiscovery = iDiscovery;
logger.info("Starting InstanceObservable at frequency: " + pollDelayMillis.get() + " millis");
//每隔pollDelayMillis去拉取一次主机的信息
//通过producer
timer.schedule(producer, 0, pollDelayMillis.get());
started.set(true);
}
producer的定义如下:
private final TimerTask producer = new TimerTask() {
@Override
public void run() {
//主要代码...
for(InstanceObserver watcher: observers.values()) {
if(currentState.get().hostsUp.size() > 0) {
try {
//通知InstanceObserver主机是UP状态
//watcher是个InstanceObserver接口的实例化对象
watcher.hostsUp(currentState.get().hostsUp);
} catch(Throwable t) {
logger.error("Could not call hostUp on watcher: " + watcher.getName(), t);
}
}
}
}
};
通过IDEA工具,找到InstanceObserver接口只有一个实现类ClusterMonitorInstanceManager,该类中实现了hostsUp()方法,而hostsUp()方法又循环去调用hostUp方法,hostUp()方法如下:
public void hostUp(Instance host) {
if (!(getObservationCriteria().observeHost(host))) {
return;
}
TurbineDataMonitor<DataFromSingleInstance> monitor = getMonitor(host);
try {
if(hostDispatcher.findHandlerForHost(host, getEventHandler().getName()) == null) {
// this handler is not already present for this host, then add it
hostDispatcher.registerEventHandler(host, getEventHandler());
}
//启动实例的监听
monitor.startMonitor();
} catch(Throwable t) {
logger.info("Failed to start monitor: " + monitor.getName() + ", ex message: ", t);
monitor.stopMonitor();
logger.info("Removing monitor from stats event console");
TurbineDataMonitor<DataFromSingleInstance> oldMonitor = hostConsole.removeMonitor(monitor.getName());
if (oldMonitor != null) {
hostCount.decrementAndGet();
}
}
}
monitor是InstanceMonitor,既实例监控对象,如下图:

实例监听,主要工作就是从实例获取指标信息,下面会分析到
3、数据聚合
数据聚合的架构图如下
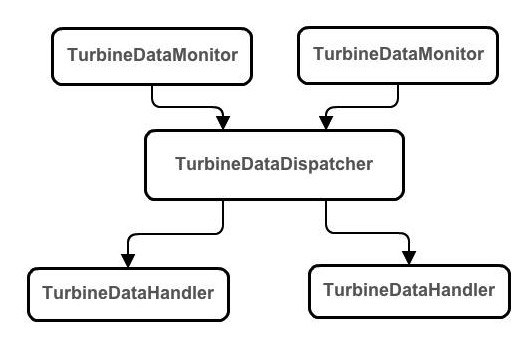
TurbineDataMonitor:数据监听,从实例处获取指标
TurbineDataDispatcher:派发器,将数据聚合后输出到客户端或者下游的数据监听
TurbineDataHandler:数据处理,其实就是客户端或者下游的数据监听
该架构有它的好处,可以实现数据的生产和消费的解耦,隔离客户端之间的处理。TurbineDataMonitor收到指标数据后,发送给TurbineDataDispatcher进行处理,它将指标信息聚合后写到一个队列中,TurbineDataHandler负责从队列取消息,如果TurbineDataHandler消费来不及,队列中的指标信息会增长,如果增长指定的大小的时候,只有消息被消费了,才会继续填充新的消息进去,否则消息将被丢弃。
4、TurbineDataMonitor
通过源码我们可以整理出TurbineDataMonitor类的上下结构图,如下:
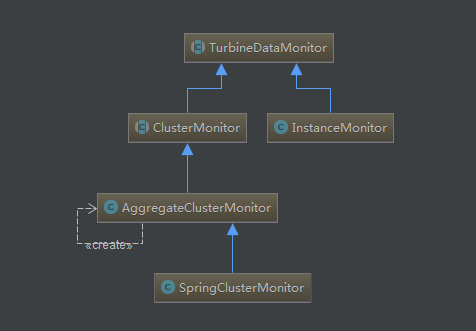
TurbineDataMonitor是一个抽象类,里面的主要方法都是抽象的,其功能实现还是依赖它的子类。
在文中第二部分的最后,我们说到,InstanceObserver会启动实例的监听,我们继续看实例的监听到底做了什么。InstanceMonitor实例监听类中的startMonitor()方法如下
public void startMonitor() throws Exception {
// This is the only state that we allow startMonitor to proceed in
if (monitorState.get() != State.NotStarted) {
return;
}
taskFuture = ThreadPool.submit(new Callable<Void>() {
@Override
public Void call() throws Exception {
try {
//初始化
init();
monitorState.set(State.Running);
while(monitorState.get() == State.Running) {
//真正干活的地方
doWork();
}
} catch(Throwable t) {
logger.warn("Stopping InstanceMonitor for: " + getStatsInstance().getHostname() + " " + getStatsInstance().getCluster(), t);
} finally {
if (monitorState.get() == State.Running) {
monitorState.set(State.StopRequested);
}
cleanup();
monitorState.set(State.CleanedUp);
}
return null;
}
});
}
先看看init()方法,初始化做了什么
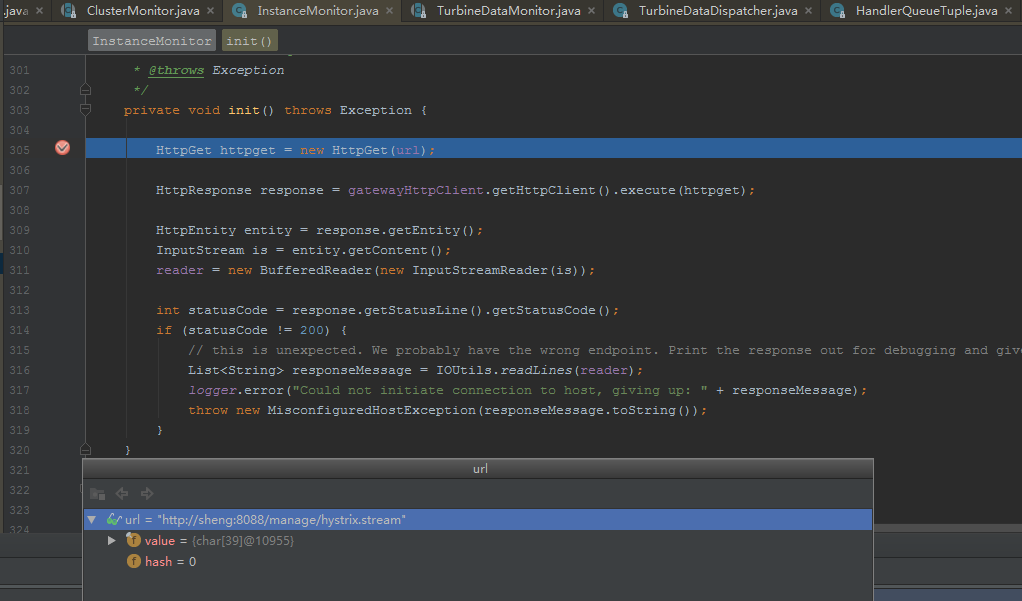
通过调试我们发现,init()方法会根据实例的指标地址http://sheng:8088/manage/hystrix.stream去获取指标信息,这个正是指标真正的来源。
继续看doWork()方法
private void doWork() throws Exception {
DataFromSingleInstance instanceData = null;
//获取实例的指标信息
instanceData = getNextStatsData();
if(instanceData == null) {
return;
} else {
lastEventUpdateTime.set(System.currentTimeMillis());
}
List<DataFromSingleInstance> list = new ArrayList<DataFromSingleInstance>();
list.add(instanceData);
/* send to all handlers */
//向派发器中发送数据
boolean continueRunning = dispatcher.pushData(getStatsInstance(), list);
if(!continueRunning) {
logger.info("No more listeners to the host monitor, stopping monitor for: " + host.getHostname() + " " + host.getCluster());
monitorState.set(State.StopRequested);
return;
}
}
派发器的说明见第5部分
5、TurbineDataDispatcher
通过查看派发器TurbineDataDispatcher中的源码可以找到pushData()方法如下:
public boolean pushData(final Instance host, final Collection<K> statsData) {
if(stopped) {
return false;
}
// get a copy of the list so we don't have ConcurrentModification errors when it changes while we're iterating
Map<String, HandlerQueueTuple<K>> eventHandlers = eventHandlersForHosts.get(host);
if (eventHandlers == null) {
return false; // stop the monitor, this should generally not happen, since we generally manage a set of static listeners for all hosts in discovery
}
for (final HandlerQueueTuple<K> tuple : eventHandlers.values()) {
//HandlerQueueTuple管道中添加数据
tuple.pushData(statsData);
}
// keep track of listeners registered, and if there are none, then notify the publisher of the events
AtomicInteger count = getIterationWithoutHandlerCount(host);
if (eventHandlers.size() == 0) {
count.incrementAndGet();
if (count.get() > 5) {
logger.info("We no longer have handlers to dispatch to");
return false;
}
} else {
count.set(0);
}
return true;
}
HandlerQueueTuple管道中的方法pushData()方法如下
public void pushData(K data) {
if (stopped) {
return;
}
//往队列中写数据
boolean success = queue.writeEvent(data);
if (isCritical()) {
// track stats
if (success) {
counter.increment(Type.EVENT_PROCESSED);
} else {
counter.increment(Type.EVENT_DISCARDED);
}
}
}
HandlerQueueTuple管道中除了writeEvent()写事件外,还有一个readEvent()读事件的操作。将在第6部分分析
6、TurbineDataHandler
我们在HandlerQueueTuple中找到doWork()方法如下
public void doWork() throws Exception {
List<K> statsData = new ArrayList<K>();
int numMisses = 0;
boolean stopPolling = false;
do {
//从队列中读取事件
K data = queue.readEvent();
if (data == null) {
numMisses++;
if (numMisses > 100) {
Thread.sleep(100);
numMisses = 0; // reset count so we can try polling again.
}
} else {
statsData.add(data);
numMisses = 0;
stopPolling = true;
}
}
while(!stopPolling);
try {
//通过事件处理器将数据输出到客户端
eventHandler.handleData(statsData);
} catch (Exception e) {
if(eventHandler.getCriteria().isCritical()) {
logger.warn("Could not publish event to event handler for " + eventHandler.getName(), e);
}
}
}
通过事件处理器将数据输出到客户端,这个操作主要是由TurbineDataHandler完成的,我们通过源码的整理,可以得到如下的代码类的图。
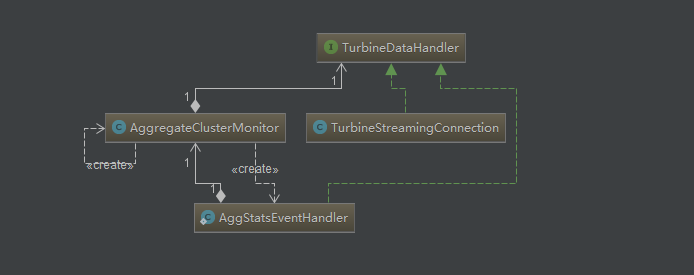
AggregateClusterMonitor的内部类AggStatsEventHandler实现数据的汇聚,TurbineStreamingConnection类是浏览器客户端连接时,数据的输出。
AggStatsEventHandler的handleData()方法如下:
public void handleData(Collection<DataFromSingleInstance> statsData) {
//整理出关键代码
for (DataFromSingleInstance data : statsData) {
TurbineData.Key dataKey = data.getKey();
// 汇聚数据
AggDataFromCluster clusterData = monitor.aggregateData.get(dataKey);
if (clusterData == null) {
monitor.aggregateData.putIfAbsent(dataKey, new AggDataFromCluster(monitor, data.getType(), data.getName()));
}
clusterData.addStatsDataFromSingleServer(data);
AggDataFromCluster dataToSend = monitor.aggregateData.get(dataKey);
if (dataToSend != null && (!throttleCheck.throttle(data))) {
dataToSend.performPostProcessing();
//将数据添加到集群派发器的队列中
monitor.clusterDispatcher.pushData(monitor.getStatsInstance(), dataToSend);
}
}
}
而TurbineStreamingConnection的handleData()方法很简单,就是将数据直接响应给浏览器。如下:
public void handleData(Collection<T> data) {
if (stopMonitoring) {
// we have been stopped so don't try handling data
return;
}
//写到stream中
writeToStream(data);
}
writeToStream()方法最终将指标数据响应给浏览器