本文主要内容
序列类型分类:
(1)容器序列、扁平序列
(2)可变序列、不可变序列
列表推导式
生成器表达式
元组拆包
切片
排序(list.sort方法和sorted函数)
bisect
文中代码均放在github上:https://github.com/ampeeg/cnblogs/tree/master/python高级
序列类型分类
所谓序列,即元素有序排列,python标准库用C实现了丰富的序列类型,按照序列中是否可存放不同类型的数据分为"容器序列"和"扁平序列"。
容器序列可以存放统统类型的数据,而扁平序列只能存放一种类型
容器序列:list、tuple、collections.deque
扁平序列:str、bytes、bytearray、memoryview、array.array
按照是否能修改的标准序列又可分为"可变序列"和"不可变序列":
可变序列:list、bytearrary、array.arrary、collections.deque和memoryview
不可变序列:tuple、str和bytes
由于可变序列继承自不可变序列,所以可变序列继承的方法也较多,下面看看它们包含的方法:
| 方法名 | 不可变序列 | 可变序列 |
| __contains__ | 有 | 有 |
| __iter__ | 有 | 有 |
| __len__ | 有 | 有 |
| __getitem__ | 有 | 有 |
| __reversed__ | 有 | 有 |
| index | 有 | 有 |
| count | 有 | 有 |
| __setitem__ | 有 | |
| __delitem__ | 有 | |
| insert | 有 | |
| append | 有 | |
| reverse | 有 | |
| extend | 有 | |
| pop | 有 | |
| remove | 有 | |
| __iadd__ | 有 |
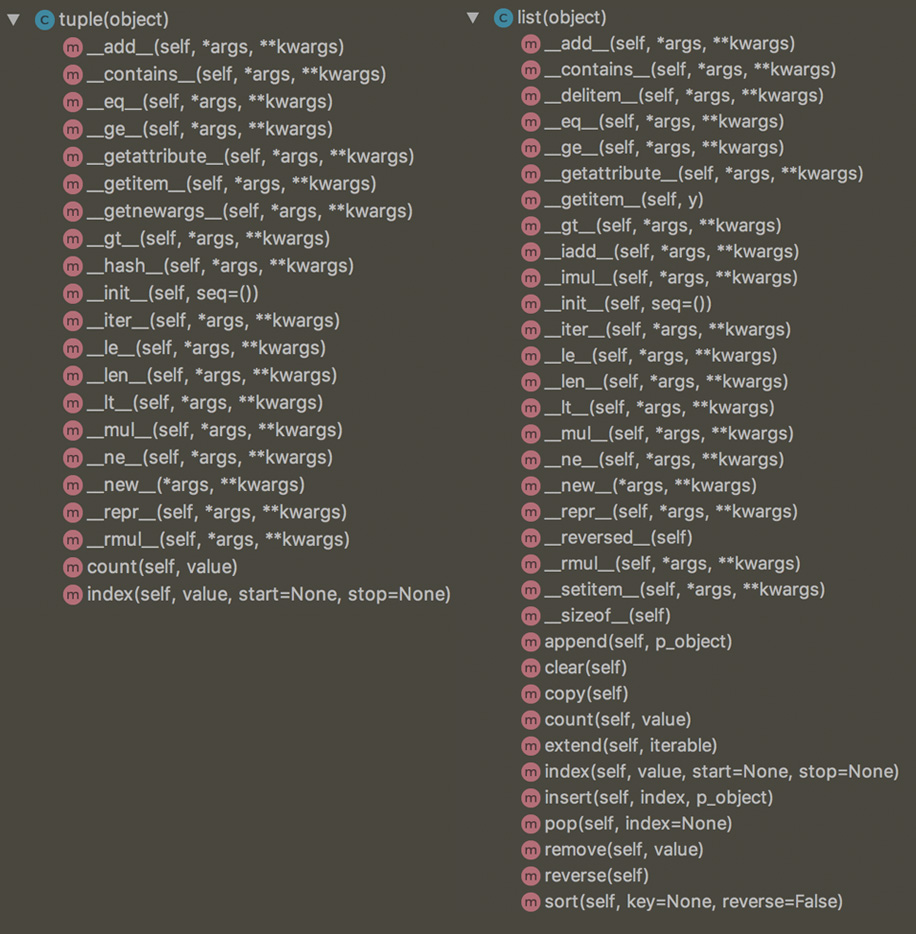
我们以tuple和list类型为例,对比源代码中的方法,可以明显发现list的方法多于tuple:
列表推导式
# 列表推导式生成的是列表,会占用系统内存 # 基本语法 list_1 = [x for x in range(1, 20)] list_2 = [x ** 2 for x in range(1, 20)] print(list_1) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] print(list_2) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361] # 笛卡尔积型的列表推导式 list_3 = [(x, y) for x in range(1, 3) # 1,2 for y in range(7, 10)] # 7、8、9 # 该表达式会先将1分别和7、8、9组合,然后再拿2和7、8、9组合,共6对 print(list_3) # [(1, 7), (1, 8), (1, 9), (2, 7), (2, 8), (2, 9)] list_4 = [x+y for x in range(1, 3) for y in range(7, 10)] print(list_4) # [8, 9, 10, 9, 10, 11] # 还可以添加if语句 l = [1, 3, 4, 33, 45, 36, 422, 34, 67, 23, -4, -7, -345, 46, -6, -45, 32, -8, -4, 67, -4] list_5 = [x for x in l if x > 0] # 只取出大于0的生成列表 print(list_5) # [1, 3, 4, 33, 45, 36, 422, 34, 67, 23, 46, 32, 67] |
生成器表达式
# 虽然列表推导式可以用来初始化元组、数组或其他序列类型,但是列表推导式会直接生成列表,占用内存 # 而生成器遵守了迭代器协议,可以逐个产出元素,而不是先建立一个完整的列表 # 生成器表达式直接将推导式的方括号换成圆括号即可 g = (x for x in range(1, 10000)) print(g) # <generator object <genexpr> at 0x105c0efc0> :生成器对象 from collections import Iterable, Iterator if isinstance(g, Iterable): print("iterable") # 输出iterable: 说明生成器g是可迭代的 if isinstance(g, Iterator): print("iterator") # 输出iterator:说明生成器g是迭代器 |
下面我们来对比一下列表推导式和生成器的效率
# 比较列表推导式和生成器 import time start_time = time.time() l = [x for x in range(1000000)] print(time.time() - start_time) # 0.1361069679260254 start_time = time.time() g = (x for x in range(1000000)) print(time.time() - start_time) # 1.1205673217773438e-05 # 可见,生成器远快于推导式 |
元组拆包
# 我们经常这样给两个变量同时赋值 a, b = 1, 2 print(a, b) # 1 2 # 还可以这样 a, b = [1, 2] print(a, b) # 1 2 # 也可以这样 a, b = (1, 2) print(a, b) # 1 2 # 甚至可以这样 a, b = "ab" print(a, b) # a b ''' 像以上这样连续的赋值方式,右边可以使用逗号隔开;也可以是序列。 当拆包赋值的是序列时,python解释器会先找该序列中的__iter__方法,如果该方法不存在,则寻找__getitem__方法。 接下来说其他用法 ''' # 赋值后优雅地交换两个变量 a, b = (1, 2) a, b = b, a print(a, b) # 2 1 # 使用*号来处理多余的数据 a, b, *s = [1, 2, 3, 4, 5, 6, 7, 8, 9] print(a, b, s) # 1 2 [3, 4, 5, 6, 7, 8, 9] # 这样从第三个元素开始的所有值都赋给了s a, b, *s = (1, 2, 3, 4, 5, 6, 7, 8, 9) print(a, b, s) # 1 2 [3, 4, 5, 6, 7, 8, 9] # 注意,本来是元组,赋之后的s变成了列表. 如果s为空的话也会返回空列表 *s, a, b = (1, 2, 3, 4, 5, 6, 7, 8, 9) print(s, a, b) # [1, 2, 3, 4, 5, 6, 7] 8 9 # *s也可以放在前面 a, *s, b = (1, 2, 3, 4, 5, 6, 7, 8, 9) print(a, s, b) # 1 [2, 3, 4, 5, 6, 7, 8] 9 # *s也可以放在中间 # 嵌套元组拆包 a, b, (c, d) = (1, 2, (3, 4)) print(a, b, c, d) # 1 2 3 4 # 只要按照右边的形式就可赋值 a, b, *c = (1, 2, (3, 4)) print(a, b, c) # 1 2 [(3, 4)] |


1 ################################ 2 # 3 # 以下的例子用以说明拆包赋值时,解释器会按照__iter__、__getitem__的顺序调用类中的方法 4 # 5 ################################ 6 class Foo: 7 def __init__(self, s): 8 self.s = s 9 10 def __iter__(self): 11 print("iter") 12 return iter(self.s) 13 14 def __getitem__(self, item): 15 return self.s[item] 16 17 if __name__ == "__main__": 18 foo = Foo("sdfafasfasf") 19 a, b, *s = foo 20 print(a, b)
之前我们通过源码已经对比过list和tuple类中的方法和属性,下面列出《流畅的python》整理的列表和元组的方法及属性:
表 列表或元组的方法和属性
| 列 表 | 元 组 | 说 明 | |
|
s.__add__(s2)
|
· | · | s1 + s2 , 拼接 |
| s.__iadd__(s2) | · | s1 += s2,就地拼接 | |
| s.append(e) | · | 在尾部添加一个新元素 | |
| s.clear() | · | 删除所有元素 | |
| s.__contains__(e) | · | · | s是否包含e |
| s.copy() | · | 列表的浅复制 | |
| s.count(e) | · | · | e在s中出现的次数 |
| s.__delitem__(p) | · | 把位于p的元素删除 | |
| s.extend(it) | · | 把可迭代对象it追加给s | |
| s.__getitem__(p) | · | · | s[p],获取位置p的元素 |
| s.__getnewargs__() | · | 在pickle中支持更加优化的序列化 | |
| s.index(e) | · | · | 在s中找到元素e第一次出现的位置 |
| x.insert(p,e) | · | 在位置p之前拆入e | |
| s.__iter__() | · | · | 获取s的迭代器 |
| s.__len__() | · | · | len(s),长度 |
| s.__mul__(n) | · | · | s * n,n个s的重复拼接 |
| s.__imul__(n) | · | s *= n,就地城府拼接 | |
| s.__rmul__(n) | · | · | n * s,反向拼接* |
| s.pop([p]) | · | 删除最后或者是位于p的元素,并返回它的值 | |
| s.remove(e) | · | 删除s中第一次出现的e | |
| s.reverse() | · | 就地把s的元素倒序排列 | |
| s.__reversed__() | · | 返回s的倒序迭代器 | |
| s.__setitem__(p,e) | · | s[p]=e,把元素e放在位置p,替代已经在那个位置的元素 | |
| s.sort([key], [reverse]) | · | 就地对s中的元素进行排序,可选的参数有key和是否倒序reverse |
说明:以上元组中不加黑点的不代表一定不能这样使用,只是其作用和列表不同(说明里面有解释)。例如两个元组a和b进行增量赋值a+=b也是可以的,只是这个操作不是就地拼接,而是生成了新的元组。
切片
''' 在python中,内置的序列类型都支持切片操作,切片操作的用法十分简单: list[start: stop: step] , 其中不包括区间范围内最后一个(事实上这是python的风格,一般不包含区间最后一个) python里面能使用切片操作是因为实现了__getitem__方法,切片时会给该方法传递slice(start: stop: step) 参数 ''' if __name__ == "__main__": # 基本操作 l = [1, 2, 3, 4, 5, 6, 7, 8, 9] print(l[2:]) # 第3个元素到最后 :[3, 4, 5, 6, 7, 8, 9] print(l[:3]) # 第一个元素到最后 :[1, 2, 3] s = "abcdefghijklmn" print(s[2::2]) # 从第三个字母开始,隔一个字母取一个 : cegikm print(s[::-1]) # 倒序排列 : nmlkjihgfedcba print(s[::-2]) # 倒序隔一个取一个 nljhfdb print(s[-2::-2]) # 倒序第二隔开始,隔一个取一个 # 利用切片赋值 l[2:5] = [20, 30] print(l) # [1, 2, 20, 30, 6, 7, 8, 9] try: l[2:5] = 40 # 报错:TypeError: can only assign an iterable # 利用切片赋值时传入的必须是可迭代对象 except Exception as e: print(e) # can only assign an iterable l[2:5] = (40,) print(l) # [1, 2, 40, 7, 8, 9] l[2:3] = "sajfljls" # 字符串属于序列,也可以迭代 print(l) # [1, 2, 's', 'a', 'j', 'f', 'l', 'j', 'l', 's', 7, 8, 9] |
排序(list.sort方法和sorted函数)
''' list.sort方法和sorted内置函数都有排序的功能,区别如下 list.sort是就地排序列表,不会把原列表复制一份。该方法返回None,以提醒不会新建一个列表。 sorted函数会新建一个列表作为返回值,这个函数可以接受任何可迭代对象,甚至包括不可变序列或生成器,最后返回的总是列表。 list.sort和sorted都有两个参数: reverse:默认为False,设定为True以降序排列 key:一个只有一个参数的函数,这个函数会作用于序列的每一个元素上,然后以该函数的结果作为关键字排序 ''' if __name__ == "__main__": # 1、list.sort就地排序,而sorted返回列表 l = [x for x in range(10, 0, -1)] # 初始化一个列表:[10, 9, 8, 7, 6, 5, 4, 3, 2, 1] print(id(l), l) # l最初的地址:4536449800 [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] l.sort() print(id(l), l) # 排序后的地址:4536449800 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # l前后的的地址没变,说明是就地排序 l = [x for x in range(10, 0, -1)] # 初始化一个列表:[10, 9, 8, 7, 6, 5, 4, 3, 2, 1] print(id(l), l) # l最初的地址:4415318984 [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] l = sorted(l) print(id(l), l) # 排序后的地址:4415318792 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 2、sorted可以接受任何可迭代对象 l = (x for x in range(10, 0, -1)) print(type(l)) # 迭代器 <class 'generator'> print(sorted(l)) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] s = "qwertyuiopasdfghjklzxcvbnm" # 字符串序列 print(sorted(s)) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'] s = (1, 3, 2, 456, 345, 12, 2, 5, 78, 34) # 不可变元组 print(sorted(s)) # [1, 2, 2, 3, 5, 12, 34, 78, 345, 456] # 3、reverse参数 s = "qwertyuiopasdfghjklzxcvbnm" print(sorted(s, reverse=True)) # ['z', 'y', 'x', 'w', 'v', 'u', 't', 's', 'r', 'q', 'p', 'o', 'n', 'm', 'l', 'k', 'j', 'i', 'h', 'g', 'f', 'e', 'd', 'c', 'b', 'a'] # 4、key参数 s = "QwERTYuioPaSdfGHjKLzXcvbnm" print(sorted(s)) # ['E', 'G', 'H', 'K', 'L', 'P', 'Q', 'R', 'S', 'T', 'X', 'Y', 'a', 'b', 'c', 'd', 'f', 'i', 'j', 'm', 'n', 'o', 'u', 'v', 'w', 'z'] print(sorted(s, key=str.lower)) # 忽略大小写 ['a', 'b', 'c', 'd', 'E', 'f', 'G', 'H', 'i', 'j', 'K', 'L', 'm', 'n', 'o', 'P', 'Q', 'R', 'S', 'T', 'u', 'v', 'w', 'X', 'Y', 'z'] print(sorted(s, key=str.upper)) # 也是忽略大小写 |
########################## # # 以下自定义一个类也可使用sorted函数 # ########################## class Obj: def __init__(self): self.s = [x for x in range(10, 0, -1)] def __getitem__(self, item): print("getitem") return self.s[item] def __repr__(self): return str(self.s) def __iter__(self): return iter(self.s) obj = Obj() print(obj) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] # 添加getitem后可以使用sorted函数 (实验时请注视掉getitem方法) print(sorted(obj)) # 打印10次getitem , [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 添加iter方法 print(sorted(obj)) # 此时解释器会先调用iter方法,不会再使用getitem方法 # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
bisect
''' bisect模块主要用来管理有顺序的序列 bisect模块包含的主要函数是bisect和insort,两个函数都使用二叉树方法搜索 1、bisect(haystack, needle) haystack必须是一个有序的序列,该函数搜索needle在haystack中的位置,该位置使得将needle插入后haystack仍然升序 查找到位置后可用haystack.insert()插入 2、insort(seq, item) 把item插入到seq中,并能保持seq的升序 ''' # 本人认为《流畅的python》中的对该模块介绍的例子比较经典,故引用之 # 1、关于bisect.bisect的示例 import bisect import sys HAYSTACK = [1, 4, 5, 6, 8, 12, 15, 20, 21, 23, 23, 26, 29, 30] NEEDLES = [0, 1, 2, 5, 8, 10, 22, 23, 29, 30, 31] ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}' def demo(bisect_fn): for needle in reversed(NEEDLES): position = bisect_fn(HAYSTACK, needle) offset = position * ' |' print(ROW_FMT.format(needle, position, offset)) if __name__ == '__main__': if sys.argv[-1] == 'left': bisect_fn = bisect.bisect_left else: bisect_fn = bisect.bisect print('DEMO:', bisect_fn.__name__) print('haystack ->', ' '.join('%2d' % n for n in HAYSTACK)) demo(bisect_fn) |
# 2、关于bisect.insort函数 import bisect import random SIZE = 7 random.seed(1729) my_list = [] for i in range(SIZE): new_item = random.randrange(SIZE*2) bisect.insort(my_list, new_item) print('%2d ->' % new_item, my_list) '''输出: 10 -> [10] 0 -> [0, 10] 6 -> [0, 6, 10] 8 -> [0, 6, 8, 10] 7 -> [0, 6, 7, 8, 10] 2 -> [0, 2, 6, 7, 8, 10] 10 -> [0, 2, 6, 7, 8, 10, 10] ''' # 另,insort函数也有insort_left,背后使用的是bisect_left |
python高级系列文章目录