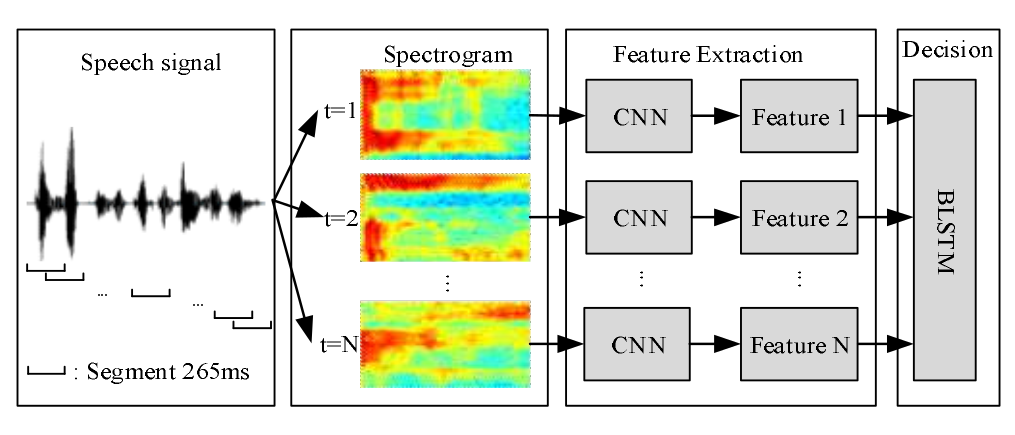
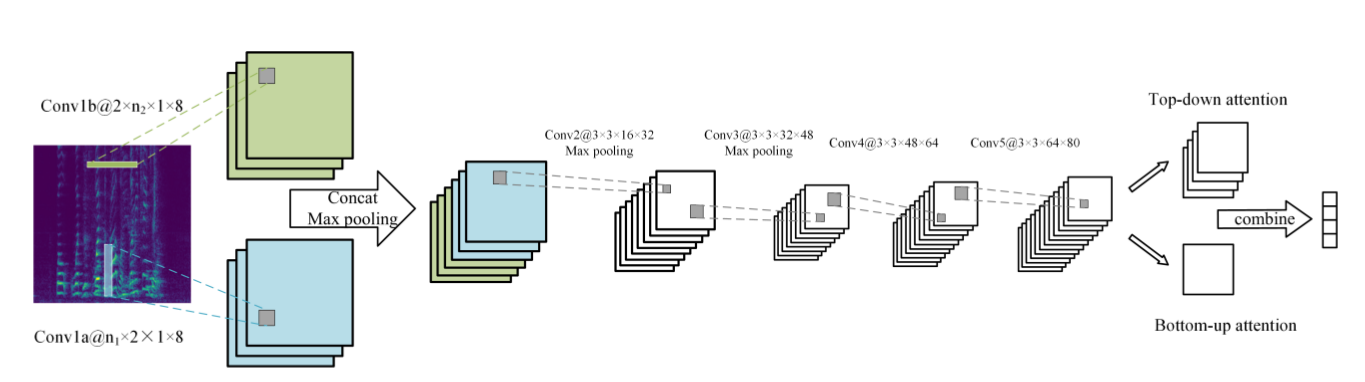
一:An Attention Pooling based Representation Learning Method for Speech Emotion Recognition(2018 InterSpeech)
(1)论文的模型如下图,输入声谱图,CNN先用两个不同的卷积核分别提取时域特征和频域特征,concat后喂给后面的CNN,在最后一层使用attention pooling的技术,在IEMOCAP的四类情感上取得71.8% 的weighted accuracy (WA) 和68% 的unweighted accuracy (UA),WA就是平时说的准确率,而UA是求各类的准确率然后做平均 。比state-of-art多了3%的WA和4%的UA。
(2)实验中的其中一篇baseline刚好也看了一下(就是下一篇要提到的论文),baseline用的是五折交叉而且带验证集的,而本论文用的是十折交叉只带测试集的,所以直接对比应该是不太科学的。
(3)我在复现这篇论文模型的时候一直都达不到论文中的结果,反复看了一下,最后是注意到论文在attention pooling合并前对bottom-up attention的feature map先做了一个softmax,这个softmax我觉得很奇怪,把它去掉后发现准确率飙升,可以达到论文中的实验结果,甚至可以超出。可能具体实现细节上有一些其它的出入。
(4)复现的时候我用的python_speech_feature库,其中有三种声谱图可以选择,振幅图,能量图,log能量图,debug的时候发现振幅和能量值的range还是挺大的,用log可以把range很大的值压到比较小的范围,所以我用的是log能量图。论文中提到对声谱图做一个预处理,说是可以让训练过程更加稳定,我在实现论文的时候有发现不加这个预处理结果会比较高。预处理的做法是先归一化到[-1, 1]然后做一个u为256的u率压扩,看到这里的256我估计论文是把声谱图直接保存成图像后做的归一化,而我是保存成声谱图矩阵来作为输入。
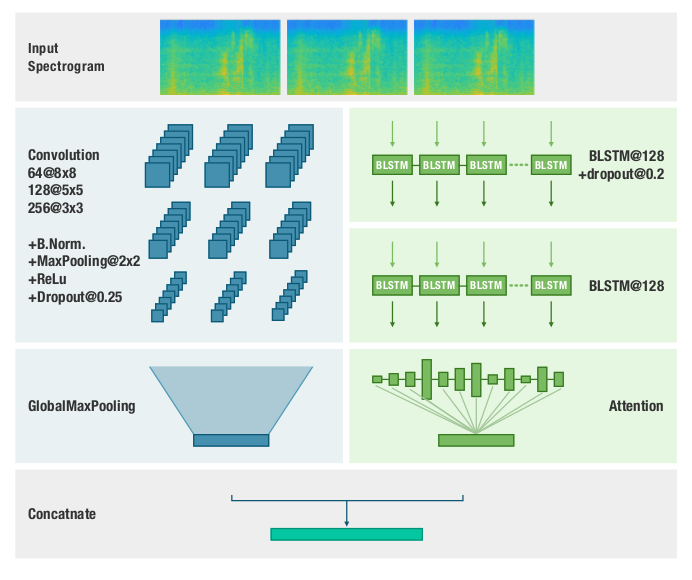
二:**Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms(2017 InterSpeech)** (1)这篇论文是上一篇论文的其中一个baseline,于是也看了一下。模型结构图如下图,输入的也是声谱图,和上一篇稍微不同的是预处理方面,上篇是切割成小于2s的样本,本文是小于3s。数据集用的也是IEMOCAP。 (2)论文还探讨了几种预处理(频率分辨率用10HZ还是20HZ)和网络结构(几个卷积层,LSTM用多少隐藏单元)的实验影响,以及评估了模型的噪音免疫能力。 (3)论文还介绍了一种两步预测的方法,先经过1个四分类器(4个情感),如果是中立类,则要另外通过3个二分类器来判定最后的情感。这么做可以提升UA,其背后直觉的解释是,一个非中立情感的大部分性质都是中立的,情感性质只占一小部分,所以对于中立类,需要进一步判定。

三:**Deep Spectrum Feature Representations for Speech Emotion Recognition(2018 ACM MM workshop——ASMMC-MMAC)** (1)输入的是梅尔尺度的声谱图(可以用librosa库调包得到),论文没有详细介绍输入部分和网络的衔接,CNN这边如何处理变长语音不明确,BLSTM则是把很多帧当成一个序列来输入。数据集用的也是IEMOCAP。 (2)论文也探讨了几种预处理和网络结构的实验影响。比较了声谱图特征和其它两个特征集(eGeMAPS和ComParE)的效果(喂给SVM),声谱图特征会稍微好一点。
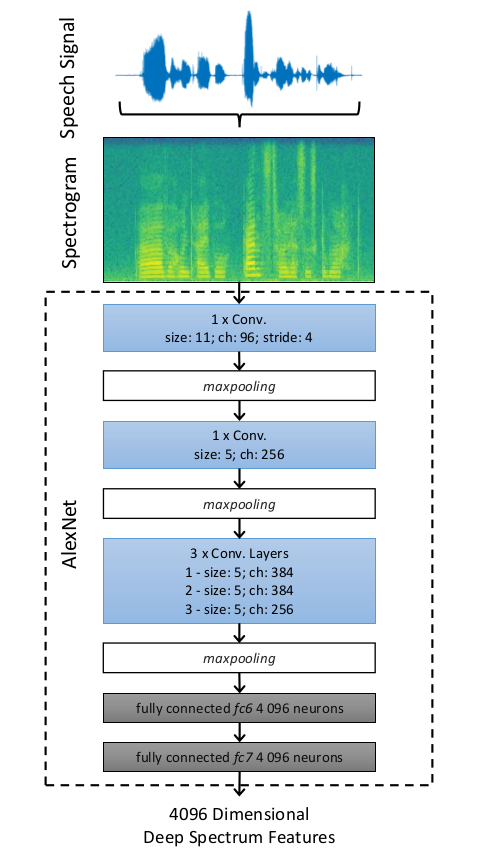
四:**An Image-based Deep Spectrum Feature Representation for the Recognition of Emotional Speech(2017 ACM MM)** (1)输入声谱图,放缩裁剪成227x227,送进caffe中预训练好的AlexNet训练,然后从第二个全连接层取出特征向量,跟两种传统特征集eGeMAPS,ComParE和BoAW(bag-of-audio-words,对LLDs特征的一种组织,LLDs指那些人工设计的低水平描述符)进行比较(喂给SVM),论文简单介绍了这三种特征。数据集用的是FAU-AIBO,有两种分类方式,一种是五分类,一种是二分类。 (2)做特征比较的时候使用了三个版本的FAU-AIBO数据比较,分别是clean,noisy和de-noised。其中de-noised是对noisy数据做了一个去噪,使用了一个三层LSTM模型,输入是100个Mel谱,模型在几个噪音版本的Audio Visual Interest Corpus上训练。 (3)比较发现声谱图提取的特征对于噪音数据具有更好的鲁棒性,同时可以看到de-noised系统的去噪并没有生效(和noisy版本的表现一样差)。
五:**Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms(2018 InterSpeech)** (1)分帧加窗DFT转为log能量谱,然后做0均值1标准差的归一化(根据训练集),使用IEMOCAP数据集。模型结构如下图所示。卷积学习空间信息,GRU学习时间信息,全连接层做最后的分类。 (2)通常的定长做法:为了使得模型能够输入定长样本,通常会把语音划分成等长样本(比如3秒)训练,然后在预测阶段也做分割,做多个预测来平均得分。 (3)变长做法:本文用了一种可以在预测阶段直接接受变长样本而不需要切割的方法,具体做法为:使时间长度类似的样本放在一个batch中然后pad到当前batch最长样本的长度。训练/预测的时候使用一个Mask矩阵(向量)来获得有效(valid)的输入区域,padding区域丢弃即可,需要注意的是max pooling的时候要处理好边界问题,对于跨边界数据把边缘值作为padding数据。 (4)训练的时候给不同长度的句子(loss)分配反比权重。另外为了处理IEMOCAP的不平衡问题给不同类别也分配反比权重,之前几篇在IEMOCAP上做实验的论文也有用到这个方法,还有使用重采样的方法。

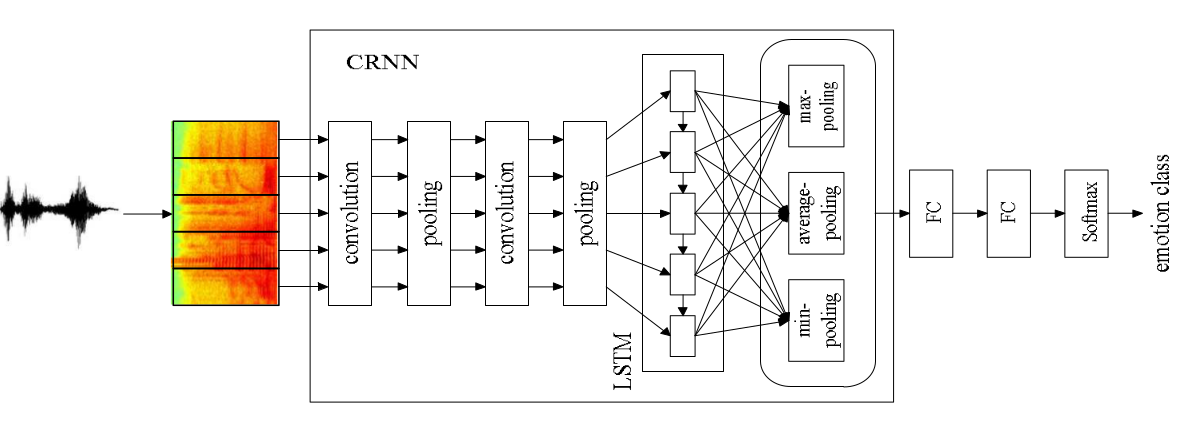
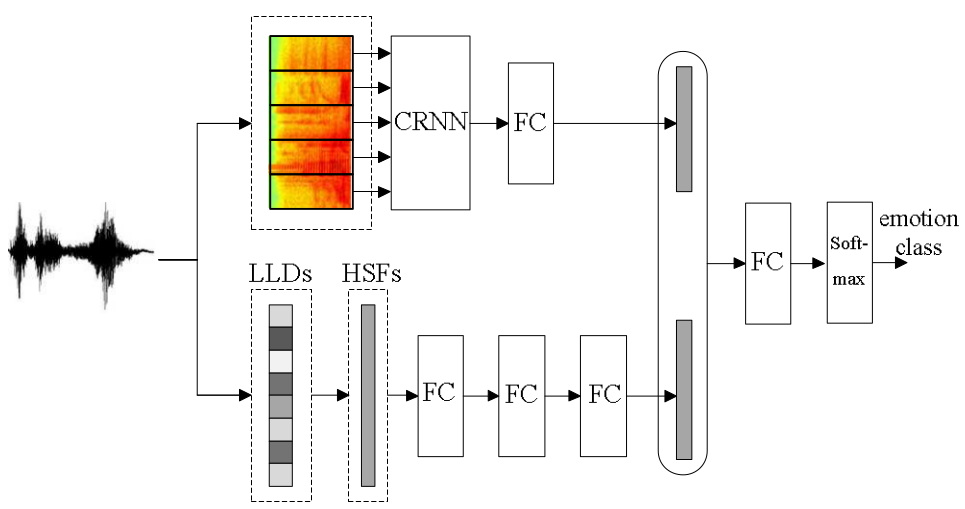
六:**Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition (2018 InterSpeech)** (1)最近结合了CNN和RNN和CRNN被广泛用于语音情感识别,然而这些模型只是简单地使用了声谱图的信息,并不能捕捉足够的情感特征。本文提出的HSF-CRNN模型结合了HSF手工特征,可以学习更好的情感特征,在2018 InterSpeech非典型情感挑战数据集 和 IEMOCAP 上做了实验,比baseline(CRNN)的效果要好。 (2)模型如下两图,第一个是baseline,第二个是本文的模型。CRNN部分输入的是声谱图,而LLD(Low Level Descriptors)指的是基频,能量,过零率,MFCC,LPCC等这些特征。HSF(High level Statistics Functions)是在LLD基础上做统计得到的特征,描述了整个utterance的动态情感内容。
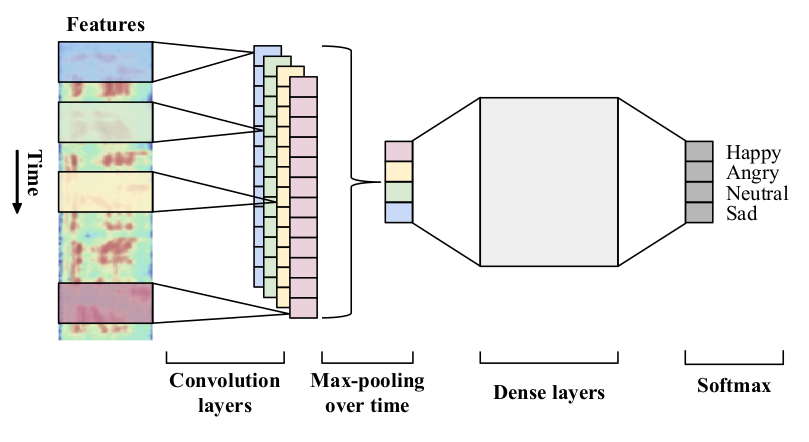
七:**Using Regional Saliency for Speech Emotion Recognition(2017 ICASSP)** (1)将CNN应用于低水平的时域特征(本文用的是40维的log Mel filterbank)来识别情感显著区,这样就不需要在utterance水平上做统计运算。如下图所示,在时间方向上卷积,一帧一帧地卷,然后用全局最大池化来捕捉时间上的重要区域。数据集用的是IEMOCAP和MSP-IMPROV。 (2)实验表明了论文的模型(使用区域显著信息)比“在utterance水平上做统计然后送入全连接”(使用统计特征)的效果好。实验还对比了和“流行的特征集InterSpeech09,InterSpeech13,GeMAPS和eGeMAPS用在SVM”的表现,有优有劣,不过论文的模型只使用了40个特征。另外还使用了速度增强来提高表现。
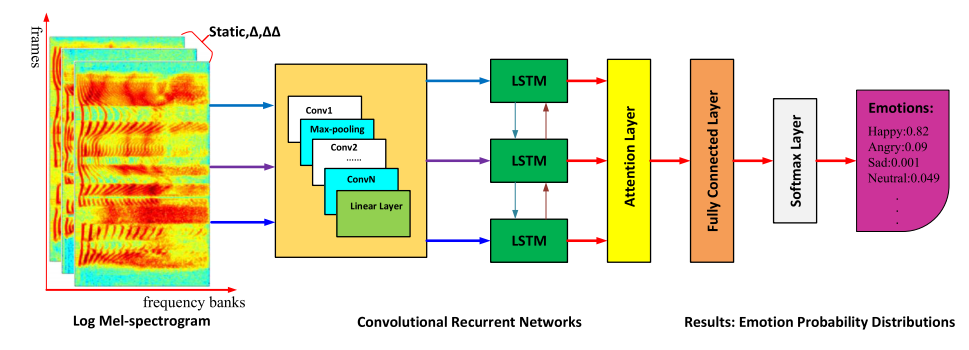
八:**3-D Convolutional Recurrent Neural Networks with Attention Model for Speech Emotion Recognition(2018 IEEE Signal Processing Letters)** (1)对语音信号DFT后的能量谱进行梅尔滤波然后取log,得到log-Mels,又计算log-Mels的deltas和delta-deltas特征,如下图所示,三种特征组成三个通道,横向上是梅尔滤波组,论文设定为40个,纵向上是时间,丢进3维卷积,池化,线性层,LSTM,然后做个attention,最后接全连接和softmax分类。数据集是IEMOCAP和EmoDB。 (2)论文做了消解(ablation)学习,发现6个卷积层在IEMOCAP上效果最好,5个卷积层在EmoDB上最好。另外对比了DNN-ELM和二维卷积,发现本文模型效果最好。
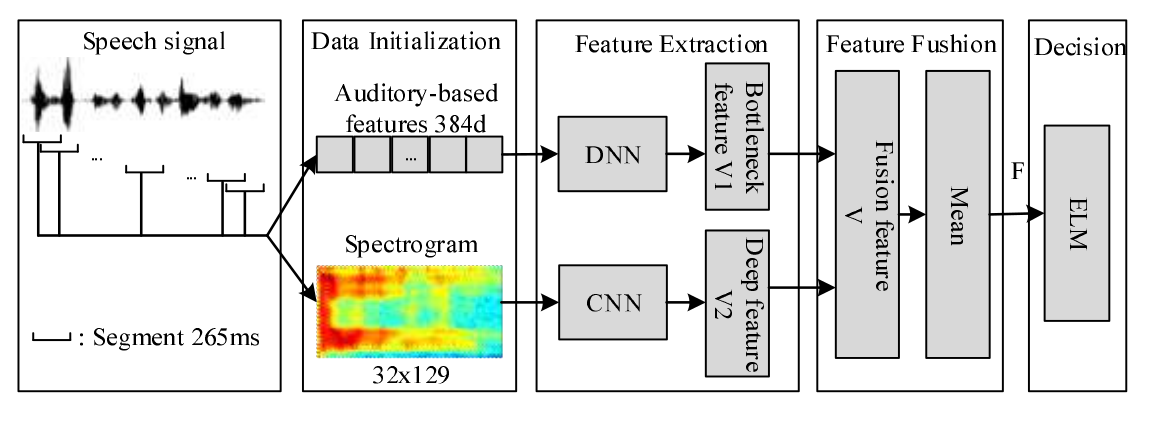
九:**A Feature Fusion Method Based On Extreme Learning Machine For Speech Emotion Recognition(2018 ICASSP)** (1)本文在流行的“声谱图+CRNN”框架上做了改进,第一个改进是加入启发性特征,第二个改进是用ELM的方法替代BLSTM。 (2)启发性特征有384维,是2009 InterSpeech挑战赛提议的统计特征,使用openSMILE获得。数据集为EmoDB (3)BLSTM结构比较复杂,而ELM是一种单隐层网络的学习算法,它的训练更快。另外,BLSTM在数据不充足的时候训练效果并不理想。