
HDFS结构
概述:
是Hadoop项目的核心子项目。是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上 pc server
高容错性 :自动保存多个副本来增加容错性
如果某一个副本丢失,HDFS机制会复制其他机器上的副本,透明实现
支持超大文件
流式数据访问 批量处理不是用户交互式处理
HDFS使应用程序能够以流的形式访问数据 注重的是吞吐量而不是数据访问的速度
简化的一致性模型
大部分为一次写入多次读取
系统架构
客户端:实现文件的切分 将文件切分成多个block数据块
只有可以切分才可以分布式存储
与namenode交互,获取文件的位置信息
跟datanode交互,读取对应的数据块
管理和访问HDFS
命令
NameNode master
管理HDFS的名称空间 维护目录结构
(这些信息以两种形式存在本地文件系统中 一种是命名空间的镜像文件File Systerm镜像文件 另一种命名空间镜像编辑日志 Edit Log

管理数据块的映射关系
配置副本策略 提高容错性
客户端的读写请求
dataNode slave
存储实际的数据块
执行数据块的读/写操作
数据块 每个数据块都有多个副本 这些副本被分布在多个datanode上
是HDFS的最小存储单元
元数据
是文件系统中文件和目录的信息以及文件和block的对应关系
HDFS 高可用原理
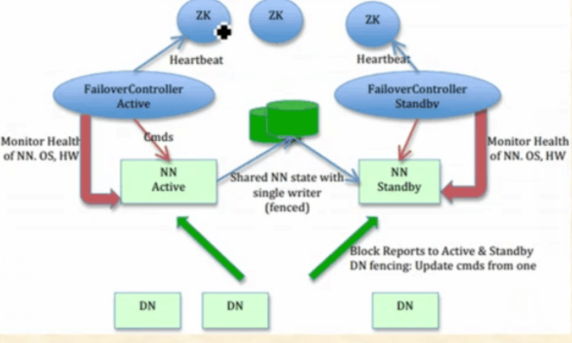
一个namnode会出错,所以还有一个备用的namenode
NFS:也是共享文件,正在使用的namenode挂了,则备用的就从NFS里获取数据
但是如果因为网络原因的话可能会产生数据不同步问题
QJM :通过一组journalnode共享数据 使用的namenode往journeynode
写数据。写成功一半则备用的namenode开始同步数据
HDFS HA-Namenode工作原理
无论什么时候都只能有一个namenode来提供状态
在任何时候Active的Namenode挂掉时能够第一时间接替它的任务成为主Namenode,达到一个热备份的效果
当发生故障时,备用的namenode会在它成为active namenode前读取所有的journalnode里面的修改日志,这样就能高可靠的保证与挂掉的namenode的目录镜像树一致,然后无缝接替其职责
为了达到高容错性的目的,备用角色也会接受来自datanode角色汇报的块信息
zkfc对namenode的主备切换进行总体控制,能及时检测到namenode的健康状况
在主namenode故障时借助zookeeper实现自动的主备选举和切换,每个运行在namenode的机器都会运行一个zkfc
zkfc作用:
namenode健康状况监控:
zkfc定期以RPC的方式向本地的namenode发送健康检查命令
只要namenode及时回复自己是健康的,那么zkfc认为那么浓的是健康的。如果namenode卡死,则zkfc则认为其不健康
zk会话管理:
当本地的namenode是健康的,zkfc则以心跳的方式保持一个会话,如果本地的namenode是active,zkfc也在zk上持有一个特殊的lock znode,如果zkfc检测到namenode是不健康的,则停止向zk上报心跳,会话失效,lock node过期删除
ZK选举
如果本地的namenode是健康的,zkfc也没有看到其他namenode持有lock znode。它将试着获取lock znode,如果成功则赢得了选举,则它本地的namenode变为active
zkfc是一个独立的进程

为什么不和NN在一起?
防止因为NN的垃圾回收失败导致心跳受影响
FailoverController功能的代码应该和应用分离,提高容错性
使得主备选举成为可插拔式的插件
QJM:

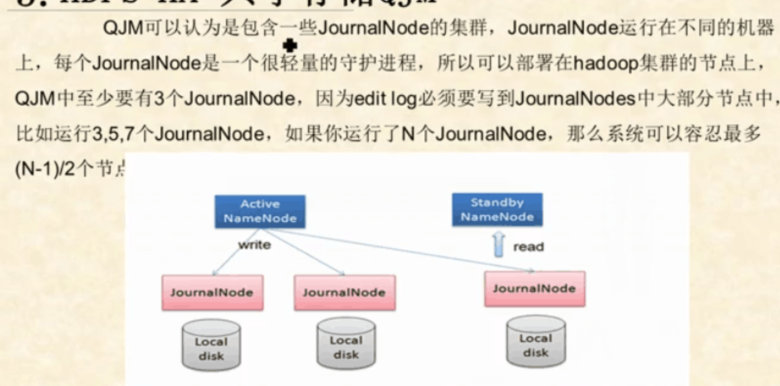
namenode记录了HDFS的目录文件等元数据,客户端每次对文件的增删改查等操作,namenode会记录一条日志,叫做editlog,而元数据存储在fsimage中,为了保持备用和active的状态一直,备用的需要尽量实时获取每条editlog日志,并应用到Fsimage。这时需要一个共享存储存放editlog,备用的可以实时获取日志
有两个关键点需要保证:
共享存储是高可用的
需要防止两个namenode同时向共享存储写数据导致数据损坏
共享存储常用的是qjm 包含多个journalnode
共享存储实现逻辑:
初始化后,active nn会把editlog写到大多数的journeynode并返回成功,及认定写入成功
备用的NN定期从Journeynode读取一批editlog,并应用到内存中的FSImage
NameNode每次写Editlog都需要传递一个epoch给journeynode,jn会对比epoch,如果比自己保存的epoch大或相同,则可以写,jn更新自己的epoch到最新,否则拒绝操作。在切换时,备用转换为active时,会把epoc+1,这样就防止之前的namenode向jn写日志,即使写入也会失败
防止脑裂:
确保只有一个nn能命令dn:
每个nn改变状态的时候,向dn发送一个自己的状态和一个新的序列号
dn在运行过程中维护此序号。当failover的时候新的nn在放回dn心跳时,会返回自己的active状态和一个更大的序列号。dn接收到这个放回时,认为该nn为新的active
如果这时原来的active恢复。返回给dn的心跳信息包含active状态和原来的序列号,这时dn就会拒绝这个nn命令