ForkJoin线程池框架回顾
-
ForkJoin框架其实就是一个线程池ExecutorService的实现,通过工作窃取(work-stealing)算法,获取其他线程中未完成的任务来执行。
-
可以充分利用机器的多处理器优势,利用空闲的线程去并行快速完成一个可拆分为小任务的大任务,类似于分治算法。
-
ForkJoin的目标,就是利用所有可用的处理能力来提高程序的响应和性能。本文将介绍ForkJoin框架,源码剖析。
ForkJoinPool的类架构图

ForkJoinPool核心类实现
- ForkJoin框架的核心是ForkJoinPool类,基于AbstractExecutorService扩展。
- ForkJoinPool中维护了一个队列数组WorkQueue[],每个WorkQueue维护一个ForkJoinTask数组和当前工作线程。
- ForkJoinPool实现了工作窃取(work-stealing)算法并执行ForkJoinTask。
ForkJoinPool,所有线程和WorkQueue共享,用于工作窃取、任务状态和工作状态同步。
核心属性介绍
- ADD_WORKER: 100000000000000000000000000000000000000000000000 -> 1000 0000 0000 0000,用来配合ctl在控制线程数量时使用
- ctl: 控制ForkJoinPool创建线程数量,(ctl & ADD_WORKER) != 0L 时创建线程,也就是当ctl的第16位不为0时,可以继续创建线程
- defaultForkJoinWorkerThreadFactory: 默认线程工厂,默认实现是DefaultForkJoinWorkerThreadFactory
- runState: 全局锁控制,全局运行状态
- workQueues: 工作队列数组WorkQueue[]
- config: 记录并行数量和ForkJoinPool的模式(异步或同步)
ForkJoinTask
- status: 任务的状态,对其他工作线程和pool可见,运行正常则status为负数,异常情况为正数
WorkQueue
-
qlock: 并发控制,put任务时的锁控制
-
array: 任务数组ForkJoinTask<?>[]
-
pool: ForkJoinPool,所有线程和WorkQueue共享,用于工作窃取、任务状态和工作状态同步
-
base: array数组中取任务的下标
-
top: array数组中放置任务的下标
-
owner: 所属线程,ForkJoin框架中,只有一个WorkQueue是没有owner的,其他的均有具体线程owner。
-
WorkQueue 内部就是ForkJoinTask
workQueue: 当前线程的任务队列,与WorkQueue的owner呼应
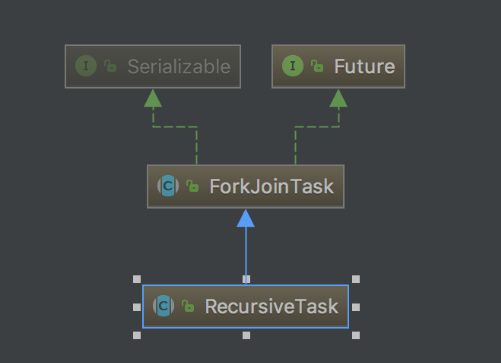
ForkJoinTask是能够在ForkJoinPool中执行的任务抽象类,父类是Future,具体实现类有很多,这里主要关注RecursiveAction和RecursiveTask。
-
RecursiveAction是没有返回结果的任务
-
RecursiveTask是需要返回结果的任务
只需要实现其compute()方法,在compute()中做最小任务控制,任务分解(fork)和结果合并(join)。
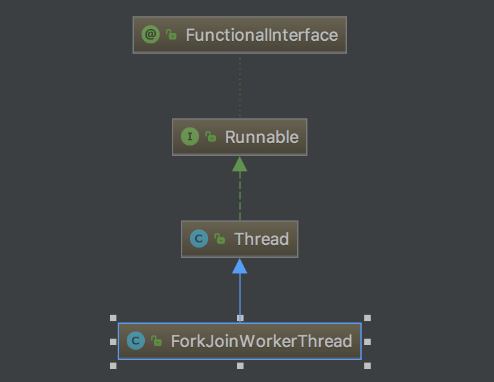
ForkJoinWorkerThread
ForkJoinPool中执行的默认线程是ForkJoinWorkerThread,由默认工厂产生,可以自己重写要实现的工作线程。同时会将ForkJoinPool引用放在每个工作线程中,供工作窃取时使用。
-
pool: ForkJoinPool,所有线程和WorkQueue共享,用于工作窃取、任务状态和工作状态同步
-
workQueue: 当前线程的任务队列,与WorkQueue的owner呼应
-
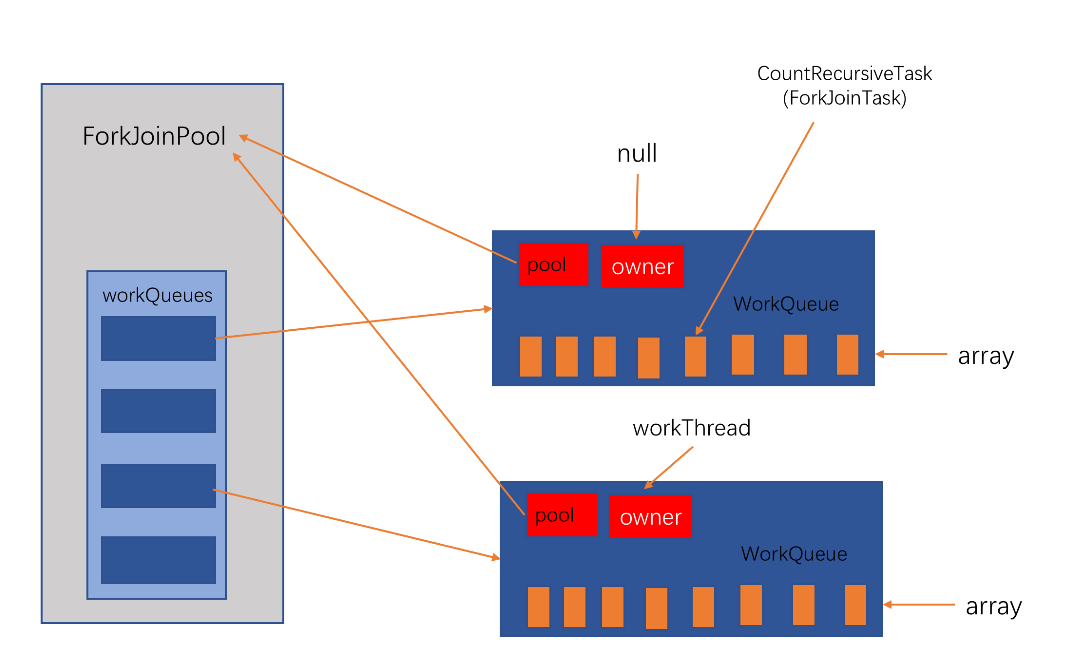
ForkJoinPool作为最核心的组件,维护了所有的任务队列WorkQueues,workQueues维护着所有线程池的工作线程,工作窃取算法就是在这里进行的。
-
每一个WorkQueue对象中使用pool保留对ForkJoinPool的引用,用来获取其WorkQueues来窃取其他工作线程的任务来执行。
-
同时WorkQueue对象中的owner是ForkJoinWorkerThread工作线程,绑定ForkJoinWorkerThread和WorkQueue的一对一关系,每个工作线程会优先完成自己队列的任务,当自己队列中的任务为空时,才会通过工作窃取算法从其他任务队列中获取任务。
-
WorkQueue中的ForkJoinTask<?>[] array,是每一个具体的任务,插入array中的第一个任务是最大的任务。
源码分析
ForkJoinPool构造函数
ForkJoinPool有四个构造函数,其中参数最全的那个构造函数如下所示:
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode)
-
parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量,也不要将这个属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性进行比较,因为ForkJoinPool的组织结构和工作方式与后者完全不一样。
-
factory:当Fork/Join框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactory接口,而是需要实现ForkJoinWorkerThreadFactory接口。
-
后者是一个函数式接口,只需要实现一个名叫newThread的方法。
-
在Fork/Join框架中有一个默认的ForkJoinWorkerThreadFactory接口实现:DefaultForkJoinWorkerThreadFactory。
-
-
handler:异常捕获处理器。当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
-
asyncMode:这个参数也非常重要,从字面意思来看是指的异步模式,它并不是说Fork/Join框架是采用同步模式还是采用异步模式工作。
- Fork/Join框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。即是说存在于队列中的待执行任务,即可以使用先进先出的工作模式,也可以使用后进先出的工作模式。
当asyncMode设置为true的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false
......
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
......
- ForkJoinPool还有另外两个构造函数,一个构造函数只带有parallelism参数,既是可以设定Fork/Join框架的最大并行任务数量;
- 另一个构造函数则不带有任何参数,对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量(Runtime.getRuntime().availableProcessors())。
- 实际上ForkJoinPool还有一个私有的、原生构造函数,之上提到的三个构造函数都是对这个私有的、原生构造函数的调用。
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
使用案例
ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors());
先看ForkJoinPool的创建过程,这个比较简单,创建了一个ForkJoinPool对象,带有默认ForkJoinWorkerThreadFactory,并行数跟机器核数一样,同步模式。
提交任务
forkJoinPool.invoke(new CountRecursiveTask(1, 100));会先执行到ForkJoinPool#externalPush中,此时forkJoinPool.workQueues并没有完成初始化工作,所以执行到ForkJoinPool#externalSubmit。
externalSubmit
这里是一个for无限循环实现,跳出逻辑全部在内部控制,主要结合runState来控制。
-
建ForkJoinPool的WorkQueue[]变量workQueues,长度为大于等于2倍并行数量的且是2的n次幂的数。这里对传入的并行数量使用了位运算,来计算出workQueues的长度。
-
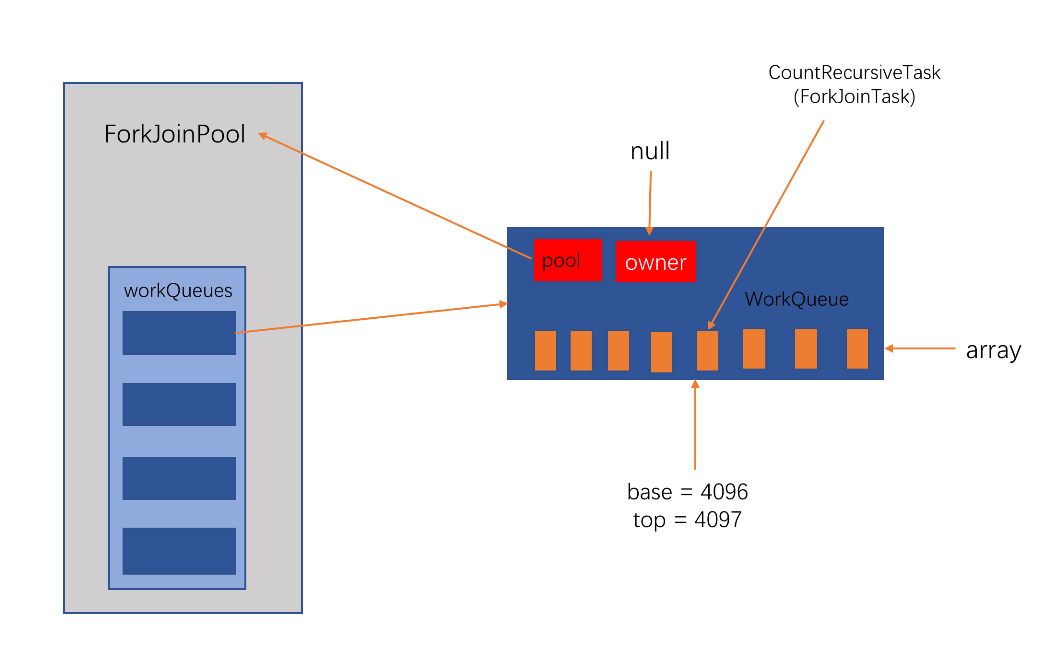
创建一个WorkQueue变量q,q.base=q.top=4096,q的owner为null,无工作线程,放入workQueues数组中
-
创建q.array对象,长度8192,将ForkJoinTask也就是代码案例中的CountRecursiveTask放入q.array,pool为传入的ForkJoinPool,并将q.top加1,完成后q.base=4096,q.top=4097。然后执行ForkJoinPool#signalWork方法。(base下标表示用来取数据的,top下标表示用来放数据的,当base小于top时,说明有数据可以取)
externalSubmit主要完成3个小步骤工作,每个步骤都使用了锁的机制来处理并发事件,既有对runState使用ForkJoinPool的全局锁,也有对WorkQueue使用局部锁。
signalWork
signalWork方法的签名是:void signalWork(WorkQueue[] ws, WorkQueue q)。ws为ForkJoinPool中的workQueues,q为externalSubmit方法中新建的用于存放ForkJoinTask的WorkQueue.
-
signalWork中会根据ctl的值判断是否需要创建创建工作线程,当前暂无,因此走到tryAddWorker(),并在createWorker()来创建,使用默认工厂方法ForkJoinWorkerThread#ForkJoinWorkerThread(ForkJoinPool)来创建一个ForkJoinWorkerThread,ForkJoinPool为前面创建的pool。
-
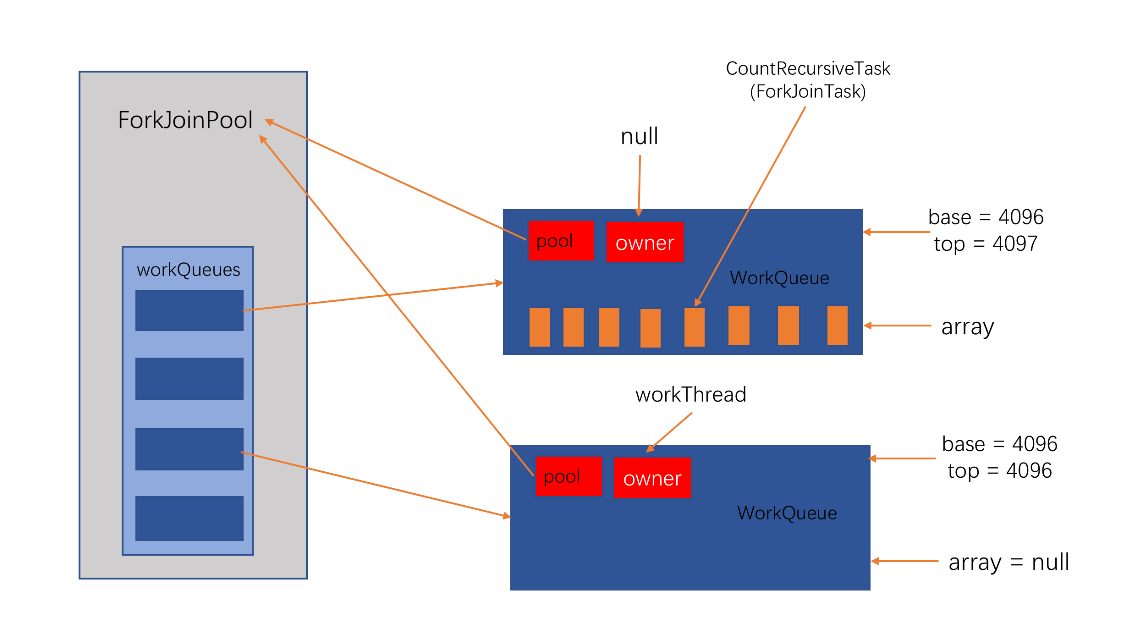
并创建一个WorkQueue其owner为新创建的工作线程,其array为空,被命名为ForkJoinPool-1-worker-1,且将其存放在pool.workQueues数组中。
-
创建完线程之后,工作线程start()开始工作。
-
这样就创建了两个WorkQueue存放在pool.workQueues,其中一个WorkQueue保存了第一个大的ForkJoinTask,owner为null,其base=4096,top=4097;第二个WorkQueue的owner为新建的工作线程,array为空,暂时无数据,base=4096,top=4096。
ForkJoinWorkerThread#run
-
执行ForkJoinWorkerThread线程ForkJoinPool-1-worker-1,执行点来到ForkJoinWorkerThread#run,注意这里是在ForkJoinWorkerThread中,此时的workQueue.array还是空的,pool为文中唯一的一个,是各个线程会共享的。
-
run方法中首先是一个判断 if (workQueue.array == null) { // only run once,这也验证了我们前面的分析,当前线程的workQueue.array是空的。每个新建的线程,拥有的workQueue.array是没有任务的。那么它要执行的任务从哪里来?
-
runWorker()方法中会执行一个死循环,去scan扫描是否有任务可以执行。全文的讲到的工作窃取work-stealing算法,就在java.util.concurrent.ForkJoinPool#scan。当有了上图的模型概念时,这个方法的实现看过就会觉得其实非常简单。

WorkQueue q; ForkJoinTask<?>[] a; ForkJoinTask<?> t;
int b, n; long c;
//如果pool.workQueues即ws的k下标元素不为空
if ((q = ws[k]) != null) {
//如果base<top且array不为空,则说明有元素。为什么还需要array不为空才说明有元素?
//从下面可以知道由于获取元素后才会设置base=base+1,所以可能出现上一个线程拿到元素了但是没有及时更新base
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) { // non-empty
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
//这里使用getObjectVolatile去获取当前WorkQueue的元素
//volatile是保证线程可见性的,也就是上一个线程可能已经拿掉了,可能已经将这个任务置为空了。
if ((t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i))) != null &&
q.base == b) {
if (ss >= 0) {
//拿到任务之后,将array中的任务用CAS的方式置为null,并将base加1
if (U.compareAndSwapObject(a, i, t, null)) {
q.base = b + 1;
if (n < -1) // signal others
signalWork(ws, q);
return t;
}
}
else if (oldSum == 0 && // try to activate
w.scanState < 0)
tryRelease(c = ctl, ws[m & (int)c], AC_UNIT);
}
if (ss < 0) // refresh
ss = w.scanState;
r ^= r << 1; r ^= r >>> 3; r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;
}
CountRecursiveTask#compute
重写compute方法一般需要遵循这个规则来写
if(任务足够小){
直接执行任务;
如果有结果,return结果;
}else{
拆分为2个子任务;
分别执行子任务的fork方法;
执行子任务的join方法;
如果有结果,return合并结果;
}
public final ForkJoinTask<V> fork() {
Thread t;
//如果是工作线程,则往自己线程中的workQuerue中添加子任务;否则走首次添加逻辑
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
ForkJoinPool.WorkQueue#push方法会将当前子任务存放到array中,并调用ForkJoinPool#signalWork添加线程或等待其他线程去窃取任务执行。过程又回到前面讲到的signalWork流程。
ForkJoinTask#externalAwaitDone
-
主线程在把任务放置在第一个WorkQueue的array之后,启动工作线程就退出了。如果使用的是异步的方式,则使用Future的方式来获取结果,即提交的ForkJoinTask,通过isDone(),get()方法判断和得到结果。
-
异步的方式跟同步方式在防止任务的过程是一样的,只是主线程可以任意时刻再通过ForkJoinTask去跟踪结果。本案例用的是同步的写法,因此主线程最后在ForkJoinTask#externalAwaitDone等待任务完成。
-
这里主线程会执行Object#wait(long),使用的是Object类中的wait,在当前ForkJoinTask等待,直到被notify。而notify这个动作会在ForkJoinTask#setCompletion中进行,这里使用的是notifyAll,因为需要通知的有主线程和工作线程,他们都共同享用这个对象,需要被唤起。
ForkJoinTask#join
来看left.join() + right.join(),在将left和right的Task放置在当前工作线程的workQueue之后,执行join()方法,join()方法最终会在ForkJoinPool.WorkQueue#tryRemoveAndExec中将刚放入的left取出,将对应workQueue中array的left任务置为空,然后执行left任务。然后执行到left的compute方法。对于right任务也是一样,继续子任务的fork和join工作,如此循环往复。
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
当工作线程执行结束后,会执行getRawResult,拿到结果。
Work-Steal算法
相比其他线程池实现,这个是ForkJoin框架中最大的亮点。当空闲线程在自己的WorkQueue没有任务可做的时候,会去遍历其他的WorkQueue,并进行任务窃取和执行,提高程序响应和性能。
取2的n次幂作为长度的实现
//代码位于java.util.concurrent.ForkJoinPool#externalSubmit
if ((rs & STARTED) == 0) {
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
// create workQueues array with size a power of two
int p = config & SMASK; // ensure at least 2 slots
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
workQueues = new WorkQueue[n];
ns = STARTED;
}
这里的p其实就是设置的并行线程数,在为ForkJoinPool创建WorkQueue[]数组时,会对传入的p进行一系列位运算,最终得到一个大于等于2p的2的n次幂的数组长度
内存屏障
//代码位于java.util.concurrent.ForkJoinPool#externalSubmit
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
//通过Unsafe进行内存值的设置,高效,且屏蔽了处理器和Java编译器的指令乱序问题
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
submitted = true;
}
这里在对单个WorkQueue的array进行push任务操作时,先后使用了putOrderedObject和putOrderedInt,确保程序执行的先后顺序,同时这种直接操作内存地址的方式也会更加高效。
高并发:细粒度WorkQueue的锁
//代码位于java.util.concurrent.ForkJoinPool#externalSubmit
//如果qlock为0,说明当前没有其他线程操作改WorkQueue
//尝试CAS操作,修改qlock为1,对这个WorkQueue进行加锁
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask<?>[] a = q.array;
int s = q.top;
boolean submitted = false; // initial submission or resizing
try { // locked version of push
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
submitted = true;
}
} finally {
//finally将qlock置为0,进行锁的释放,其他线程可以使用
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
if (submitted) {
signalWork(ws, q);
return;
}
}
这里对单个WorkQueue的array进行push任务操作时,使用了qlock的CAS细粒度锁,让并发只落在一个WOrkQueue中,而不是整个pool中,极大提高了程序的并发性能,类似于ConcurrentHashMap。