HTTP请求的优化
在一个网页的请求过程中,其实整个页面的html结构(就是页面的那些html骨架)请求的时间是很短的,一般是占整个页面的请求时间的10%-20%.在页面加载的其余的时间实际上就是在加载页面中的那些flash,图片,脚本的资源. 一直到所有的资源载入之后,整个页面才能完整的展现在我们面前.
下面,我们就从一个页面开始讲述:

2 <html xmlns="http://www.w3.org/1999/xhtml">
3 <head>
4 <title>小洋,燕洋天</title>
5
6 <script type="text/javascript" src="../demo.js">
7 </script>
8
9 </head>
10 <body>
11 <div>
12 <img src="../images/1.gif" />
13 <img src="../images/2.gif" />
14 <img src="http://yanyangtian.cnblogs.com/image/3.gif" />
15 <img src="http://yanyangtian.cnblogs.com/image/4.gif" />
16 <img src="http://yanyangtian.cnblogs.com/image/5.gif" />
17 <img src="http://yanyangtian.cnblogs.com/image/6.gif" />
18 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
19 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
20 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
21 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
22 </div>
23 </body>
24 </html>
25
如果我们向服务器请求这个页面,客户端的浏览器首先请求到的数据就是html骨架,即:
2 <html xmlns="http://www.w3.org/1999/xhtml">
3 <head>
4 <title>小洋,燕洋天</title>
5
6 <script type="text/javascript" src="../demo.js">
7 </script>
8
9 </head>
10 <body>
11 <div>
12 <img src="../images/1.gif" />
13 <img src="../images/2.gif" />
14 <img src="http://yanyangtian.cnblogs.com/image/3.gif" />
15 <img src="http://yanyangtian.cnblogs.com/image/4.gif" />
16 <img src="http://yanyangtian.cnblogs.com/image/5.gif" />
17 <img src="http://yanyangtian.cnblogs.com/image/6.gif" />
18 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
19 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
20 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
21 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
22 </div>
23 </body>
24 </html>
25
在此之前,首先来普及一下页面加载的小知识:
当页面的html骨架载入了之后,浏览器就开始解析页面中标签,从上到下开始解析.
首先是head标签的解析,如果发现在head中有要引用的js脚本,那么浏览器此时就开始请求脚本,此时整个页面的解析过程就停了下来,一直到js请求完毕.
之后页面接着向下解析,如解析body标签,如果在body中有img标签,那么浏览器就会请求img的src对应的资源,如果有多个img标签,那么浏览器就一个个的解析,解析不会像js那样等待的,如果发现img的url地址是同一个地址,那么浏览器就会充分的利用这个已经打开的tcp连接顺序的去一个个的请求图片,如果发现有的img的url地址不同,那么浏览器就另开tcp连接,发送http请求.
注意之前请求js的区别:请求需要js,浏览器会一直等待,不在解析下面的html标签
但是解析到img的时候,尽管此时需要加载图片,但是页面的解析过程还是会继续下去的,然后决定是否发送新的tcp连接加载资源.
大家可能觉得这个之前的代码片段一样,确实代码是一样的,但是,在最开始的时候,发送到浏览器中的只是那些html的代码,任何的js脚本和图片还没有发送过来.
当html代码到了浏览器中,那么浏览器就开始一步步的解析这些代码了,只要遇到了需要加载的资源,浏览器就向服务器发出http请求,请求所需的资源.
整个页面的加载时间图如下:

大家从图中可以看出:
第一条线中分为一半黄色和一半蓝色,其实黄色的部分就代表了打开一个tcp连接花的时间,而后面的蓝色的部分就是请求整个html骨架文档的时间.可以看出,请求html骨架的时间是很短的.其余蓝色的线就表示了图片,脚本资源加载所花的时间.
很显然,这样页面的整个加载时间就很长了.因为页面的加载几乎是顺序的载入,时间就是所有资源加载时间的总和.
下面我们把上面的页面代码代为如下:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>小洋,燕洋天</title>
<script type="text/javascript" src="../demo.js">
</script>
</head>
<body>
<div>
<img src="http://demo1.com/images/1.gif" />
<img src="http://demo1.com/images/2.gif" />
<img src="http://demo2.com/image/3.gif" />
<img src="http://demo2.com/image/4.gif" />
<img src="http://demo3.com/image/5.gif" />
<img src="http://demo3/image/6.gif" />
<img src="http://demo4.com/image/7.gif" />
<img src="http://demo4.com/image/8.gif" />
<img src="http://yanyangtian.cnblogs.com/image/7.gif" />
<img src="http://yanyangtian.cnblogs.com/image/8.gif" />
</div>
</body>
</html>
我们再来看看页面的加载时间图
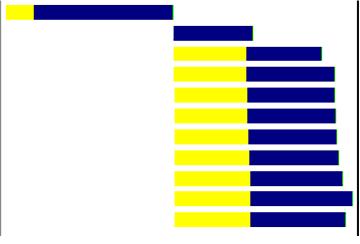
这就是所谓的”并行”载入了.
比较一下两段代码的不同:其实就在img的src属性上面:
第一段页面的代码:img的src属性都是指向一个域名的.
第二段页面的代码:img的src属性指向了不同的域名
这样做的结果是什么?
请大家注意比较img的src的不同.
解释之前,首先来看一个小的常识(在上篇文章中也提过):
当页面请求向服务器请求资源的时候,如果浏览器已经在客户端和服务器之前打开了一个tcp连接,而且请求的资源也在开了连接的服务器上,那么以后资源的请求就会充分的利用这个连接去获取资源. 这样也就是第一个时间图的由来.
如果请求的图片分别位于不同的服务器网站,或者那个请求的服务器网站有多个域名,那么因为浏览器就会为每一个域名去开一个tcp连接,发送http请求,这样,结果就是同时开了多tcp连接,这也是第二个时间图的由来.
虽然说并行加载,确实使得页面的载入快了不少,但是也不是每一个图片或者其他的资源都去搞一个不同的域名,像之前的第二个并行载入图片的例子,也是让两个图片利用一个tcp连接.如果每个图片都去开一个连接,这样浏览器就开了很多个连接,也是很费资源的,而且浏览器还可能会”僵死”.而且有时还会严重的影响性能.
所以,这是需要权衡的.
除了上面的优化方式,还有其他的图片优化的加载方式.主要是通过减少http的请求达到优化
大家都知道网站的一个menu菜单,有些菜单就是用图片作出来的.如
如果上面的图片一个个载入,势必影响速度,如果开多和请求,有点得不偿失.而且图片也不是很大,那么就一次把整个menu需要的图片作为整个图片,一次加载,然后通过map的方式,控制点击图片的位置来达到导航的效果.
这样一个问题就是:算出图片的坐标,不能点击了”主页”图片,然后却跳到了”帮助”页面了.