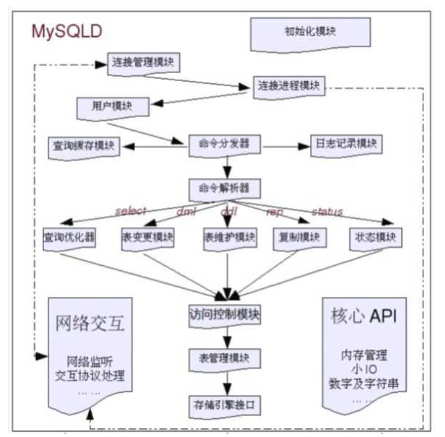
一、Mysql架构图
上图就是Mysql的架构图,对于其中组件说明如下:
1、Connectors
连接器,指不同语言与Mysql的交互
2、Management Services & Utilities
系统管理&控制工具
3、Connection Pool:连接池
(1)管理用户连接,等待处理连接请求
(2)负责监听对MysqlServer的各种请求,接收连接请求,转发所有连接请求到线程管理模块,每一个连接上MysqlServer的客户端都会被分配(或创建)一个连接线程为单独服务。
(3)而连接线程的主要工作就是负责MysqlService与客户端的通信,接收客户端的命令请求,传递Server端的结果信息等。线程管理模块则负责管理维护这些连接线程,包括线程的创建,线程的缓存等
4、Sql Interface
接收用户的SQL命令,并且返回用户需要查询的结果,比如select from就是调用SQL Interface
5、Parser:解释器
SQL命令传递到解析器的时候会被解析器验证和解析
主要功能:
(1)将SQL语句进行词法分析和语法分析,解析成语法树,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。
(2)如果在分解过程中出现错误,那么说明这个sql语句是不合理的。
6、Optimizer:查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化,explain语句查看的SQL执行计划,就是由查询优化器生成的。
7、Cache和Buffer:查询缓存
他的主要功能是将客户提给Mysql的select请求的返回结果集cache到内存中,与该query的一个hash值做一个对应,该Query所取数据的基表发生任何数据的变化之后,Mysql会将该Query的Cache失效,在读写比例非常高的系统中,Query Cache对性能的提高是非常显著的。但是其对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据,这个缓存机制是由一系列的小缓存组成,比如表缓存、记录缓存、key缓存、权限缓存等。
8、Pluggable Storage Engines
与其他数据库(如Oracle、SQL Server等)数据库中只有一种存储引擎不同,Mysql有一个Pluggable Storage Engines(可插拔的存储引擎),也就意味着Mysql数据库提供了多种存储引擎。
而且存储引擎是针对表的,用户可以根据不同的需求为不同的表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
存储引擎就是如何存储数据、如何为存储的数据建立索引、如何更新索引、如何查询数据等技术的实现
create table tablename(...) ENGINE=INNODB/MyISAM/...;
Mysql存储引擎
| 存储引擎 | 说明 |
| MyISAM | 高速引擎,拥有较高的插入和查询速度,但是不支持事务 |
| InnoDB | 5.5版本后Mysql的默认存储引擎,支持事务和行锁,比MyISAM处理速度稍慢 |
| ISAM | MyISAM前身,Mysql5.0以后不再默认安装 |
| MRG_MyISAM | 将多个表联合成一个表使用,在超大规模数据存储时很有用 |
| Memory | 内存存储引擎,拥有极高的插入、更新和查询效率,但是会占用和数据量成正比的内存空间,只在内存上保存数据,意味着数据可能会丢失。类似于Redis |
| Falcon | 一种新的存储引擎,支持事务处理,传言可能使InnoDB的替代者 |
| Archive | 将数据压缩后存储,非常适合存储大量的、独立的、作为历史记录的数据,但是只能进行插入和查询操作。 |
| CSV | CSV存储引擎是基于CSV格式文件存储数据(应用于跨平台的数据交换) |
查看存储引擎:
show engines;
InnoDB和MyISAM的区别:
| InnoDB | MyISAM | |
| 存储文件 |
.frm表定义文件 .idb数据文件和索引文件 |
.frm表定义文件 .myd数据文件 .myi索引文件 |
| 锁 | 支持表锁和行锁 | 只支持表锁 |
| 事务 | 支持 | 不支持 |
| CRUD | 读写 | 读多 |
| count | 扫表 | 专门存储的地方 |
| 索引结构 | B+ Tree | B+ Tree |
XtraDB存储引擎是由Percona公司提供的存储引擎,该公司还出品了Percona Aerver这个产品,它是基于Mysql开源代码进行修改后的产品,
阿里对于Percona Server服务器进行修改,衍生了自己的数据库(alisql)
引擎的选择:
大多数场景下,选择InnoDB就可以了,除非用到了InnoDB不具备的特性时,采用别的引擎。
二、环境说明
(一)示例数据库安装
Sakila示例数据库的开发开始于2005年,最初由Mysql AB文档团队开发,旨在提供一种标准模式,可用于书籍、教程、文章等示例,Sakila示例数据库还用于突出显示MYSQL的功能,例如视图、存储过程和触发器等。
Sakila数据库包括演员表、电影表等信息。
1、下载&解压
wget https://downloads.mysql.com/docs/sakila-db.tar.gz tar -zxvf sakila-db.tar.gz
2、导入数据
登陆mysql,导入样例表及样例sql数据
source /root/data/mysql/sakila-db/sakila-schema.sql
source /root/data/mysql/sakila-db/sakila-data.sql
(二)Mysql文件结构
Mysql是通过文件系统对数据和索引进行存储的。
Mysql从物理结构上可以分为日志文件和数据索引文件。
1、日志文件(顺序IO)
Mysql通过日志记录了数据库操作信息和错误信息,常用的日志文件包括错误日志、二进制日志、查询日志、慢查询日志、事务Redo日志、中继日志等。
可以通过命令查看当前数据库中的日志使用信息
mysql> show variables like 'log_%'; +----------------------------------------+--------------------------------+ | Variable_name | Value | +----------------------------------------+--------------------------------+ | log_bin | ON | | log_bin_basename | /var/lib/mysql/mysql-bin | | log_bin_index | /var/lib/mysql/mysql-bin.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | log_builtin_as_identified_by_password | OFF | | log_error | /var/log/mysqld.log | | log_error_verbosity | 3 | | log_output | FILE | | log_queries_not_using_indexes | OFF | | log_slave_updates | OFF | | log_slow_admin_statements | OFF | | log_slow_slave_statements | OFF | | log_statements_unsafe_for_binlog | ON | | log_syslog | OFF | | log_syslog_facility | daemon | | log_syslog_include_pid | ON | | log_syslog_tag | | | log_throttle_queries_not_using_indexes | 0 | | log_timestamps | UTC | | log_warnings | 2 | +----------------------------------------+--------------------------------+
(1)错误日志(errorlog)
默认是开启的,而且从5.5.7以后无法关闭错误日志,错误日志记录了运行过程中遇到的所有严重的错误信息,以及Mysql每次启动和关闭的详细信息。
默认的错误日志名称:hostname.err
错误日志所记录的信息是可以通过log-error和log-warnings来定义的(上述的配置项),其中log-err是定义是否启用错误日志的功能和错误日志的存储位置,log-warnings是定义是否将警告信息也定义到错误日志中。
其中log-error可以配置ON或者OFF,也可以配置文件路径。
log_warnings如果为0,则表示警告不记录到错误日志中,如果为1,则表示警告要记录到错误日志中,如果大于1,表示各类警告(网络故障信息、重新连接信息等)信息都要写入错误日志。
(2)二进制日志(bin log)
默认是关闭的,可以修改my.cnf配置文件,添加上如下配置信息,其中mysql-bin是binlog日志文件的basename,binlog日志文件的完整名称是mysql-bin.000001.log
log-bin=mysql-bin
binlog记录了数据库所有的ddl语句和dml语句,但是不包括select语句,语句以事件的形式保存,描述了数据的变更顺序,binlog还包括了每个更新语句的执行时间信息,如果是DDL语句,则直接记录到binlog日志中,而DML语句,必须通过事务提交才能记录到binlog中。
binlog主要用于主从复制、数据备份、数据恢复。
(3)通用查询日志(general query log)
默认情况下通用查询日志是关闭的。
由于查询日志会记录用户的所有操作,其中还包括增删改等信息,在并发操作大的环境下会产生大量的信息从而导致不必要的磁盘IO,会影响mysql的性能,因此,一般只有在调试数据库的时候才会开启查询日志。
mysql> show global variables like 'general_log'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | general_log | OFF | +---------------+-------+
如果要调整,需要修改my.cnf配置文件
#启动开关 general_log={ON|OFF} #日志文件变量,而general_log_file如果没有指定,默认名是host_name.log general_log_file=/PATH/TO/file #记录类型 log_output={TABLE|FILE|NONE}
(4)慢查询日志(slow query log)
默认是关闭的,需要通过my.cnf配置文件修改
#开启慢查询日志 slow_query_log=ON #慢查询的阈值 long_query_time=10 #日志记录文件如果没有给出file_name值, 默认为主机名,后缀为-slow.log。如果给出了文件名,但不是绝对路径名,文件则写入数据目录。 slow_query_log_file= file_name
会记录执行时间超过long_query_time秒的所有查询,便于手机查询时间比较长的sql语句。
查询多少sql超过了慢查询时间阈值:
mysql> show global status like '%slow_queries%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Slow_queries | 0 | +---------------+-------+
2、数据文件
查看Mysql数据文件
mysql> show variables like '%datadir%'; +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | datadir | /var/lib/mysql/ | +---------------+-----------------+
(1)InnoDB文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息。
.ibd文件:使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件。
ibdata文件:使用共享表空间存储表数据和索引信息,所有表共同使用一个或多个ibdata文件。
(2)MyISAM文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息
.myd文件:主要存放表数据信息
.myi文件:主要存放表索引信息
上面已经使用命令查看了数据文件的位置,在该文件夹下,可以看到红色标记的库名,由于我使用的数据引擎是InnoDB,因此还可以看到绿色标记的共享表空间存储的表数据和索引信息。
进入到具体的数据库中,可以看到红色标记的表结构定义文件和独享空间存储的表数据,还可以看到绿色标记的独享表空间存储的索引文件。

三、MysqlServer层对象
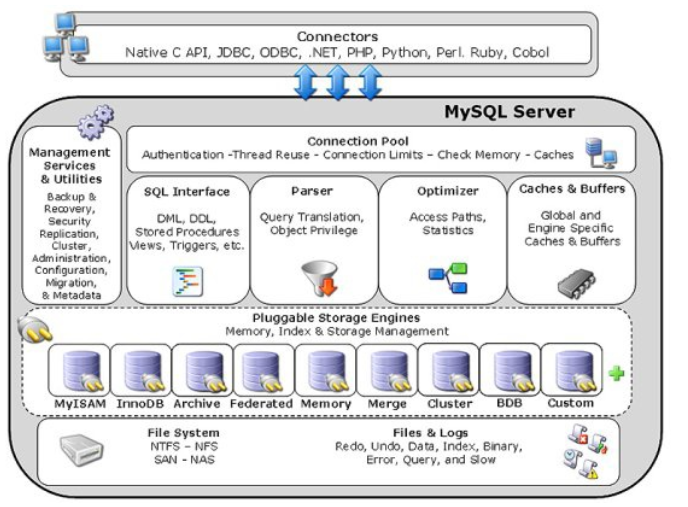
1、Sql语句的执行流程
大体来说,Mysql可以分为Server层和存储引擎层:
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖Mysql的大多数核心服务功能,以及所有的内置函数(比如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图。
存储引擎负责数据的存储和提取,其架构模式是插件式的,支持InnoDB、MyISAM等,从Mysql5.5.5版本开始,InnoDB为默认的存储引擎。如果在创建表时,没有指定存储引擎,那么会使用默认的存储引擎,如果要指定存储引擎,例如指定使用MyISAM存储引擎,需要在创建语句后加上engine=MyISAM。
2、连接器
我们使用Mysql的时候,第一步就是先连接到数据库上,这个时候使用的就是连接器,连接器负责跟客户端建立连接,获取权限,维持和管理连接,连接命令如下:
mysql -h$ip -P$port -u$user -p$password
如果是生产服务器,建议不要直接输入密码,而是在-p后不加密码,后面服务器会提示输入密码,这样可以不暴露密码,安全更好。
连接命令中的mysql是客户端工具,用来跟服务端建立连接,在完成TCP握手后,连接器就要开始认证身份,这个时候就需要用到用户名密码。如果用户名密码不对,就会提示错误,如果用户名密码验证通过,连接器会到权限表查出用户所拥有的权限,之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
连接完成后,如果没有后续的动作,这个连接就处于空闲状态,可以使用命令查看,如下图所示,就是查看连接的输出,其中Command中Sleep这一行就表示现在系统里有一各空闲连接。
mysql> show processlist; +----+------+-----------+--------+---------+------+----------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+-----------+--------+---------+------+----------+------------------+ | 14 | root | localhost | sakila | Query | 0 | starting | show processlist | | 15 | root | localhost | NULL | Sleep | 8 | | NULL | +----+------+-----------+--------+---------+------+----------+------------------+ 2 rows in set (0.00 sec)
客户端如果长时间没有操作,连接器就会断开这个连接,这个时间是由参数wait_timeout控制的,默认是8小时。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接,短链接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程是比较复杂的,所以一般情况下我们要尽量避免建立连接的动作,转而使用长连接,但是如果全部使用长连接,有些时候Mysql占用内存会涨的特别快,这是因为Mysql在执行过程中临时使用的内存是管理在连接对象里面的,这些资源会在连接断开的时候才释放,所以如果长连接累积下来,可能导致内存占用太大,被系统强项杀掉,从现象看就是Mysql异常重启。
解决长连接占用内存过多的问题,可以考虑以下两种方案:
(1)定期断开长连接,使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
(2)如果用的是Mysql5.7及以后的版本,可以在每次执行一个比较大的操作后, 通过执行mysql_reset_connection来重新初始化连接资源,这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完成的状态。
3、查询缓存
连接建立完毕后,就可以执行select查询语句,执行来到第二步,查询缓存。
Mysql拿到一个查询请求后,会先查询缓存看看,之前是不是已经执行过这条语句,之前执行过的语句及其结果可能会议K-V键值对的形式,被直接缓存在内存中,key是查询语句hash之后的值,value是查询结果。如果查询能够直接在缓存中找到key,那么value就会直接返回客户端。如果查询结果在缓存中找不到,就会继续后面的处理,执行完成后,会将结果存入查询缓存。
大多数情况下,不要使用缓存,因为缓存往往弊大于利,查询缓存失效非常频繁,只要对一个表有更新,这个表上所有的查询缓存都会被清空,因此往往一个缓存刚被存储,还没有被使用,缓存就被清空,同时对于更新压力大的数据库来说,查询缓存的命中率会很低,除非有一张静态表,很长时间才会更新一次。
同时Mysql也提供了按需使用的方式,可以将query_cache_type设置为DEMAND,这样默认的查询都不走缓存,而对于需要使用缓存的语句,可以使用sql_cache来显式指定,例如:
select sql_cache * from city;
查看缓存命中次数
show status like 'Qcache_hits';
查看是否打开缓存
mysql> show variables like 'query_cache_type'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | query_cache_type | OFF | +------------------+-------+
开启缓存,需要修改my.cnf配置文件
query_cache_type=1
清空查询缓存:
FLUSH QUERY CACHE; // 清理查询缓存内存碎片 RESET QUERY CACHE; // 从查询缓存中移出所有查询 FLUSH TABLES; //关闭所有打开的表,同时该操作将会清空查询缓存中的内容
需要注意的是,Mysql8.0直接将查询缓存的整块功能删除了,也就是说从8.0开始,彻底没有这个功能了。
4、分析器
如果没有命中缓存,就要开始真正的执行语句了,首先,Mysql需要对sql语句进行解析,从而知道如何执行。
解析器首先会做词法分析,就是将一个完整的SQL语句分割成一个个的字符串,例如一个简单的查询,他需要将其分割成select,field,from,tablename等信息
然后就开始做语法分析,根据词法分析的结果,语法分析器会做相应的检查,判断输入的sql是否正确。如果不正确,会提示第一个出现错误的位置;如果正确,就会根据mysql的语法规则,生成一个数据结构(解析树)
如果存在预处理,那么预处理器会进一步检查解析树是否合法,比如表名是否存在,语句中表的列是否存在等等,在这一步mysql会检查用户是否有表的操作权限,预处理后会得到一个新的解析树。
5、优化器
一条sql语句其实可以有多种执行方式,但是返回的结果只有一种;为了达到更好的执行效果,Mysql优化器会在执行sql前,对sql进行优化。
查询优化器的作用是根据解析树生成不同的执行计划,然后选择一种最优的执行计划;Mysql里使用的是成本模型的优化器,哪种执行计划执行成本最小就用哪种,而且他是io_cost和cpu_cost的开销总和,它通常也是我们评价一个查询执行效率的常用指标。
mysql> show status like 'last_query_cost'; +-----------------+------------+ | Variable_name | Value | +-----------------+------------+ | Last_query_cost | 122.999000 | +-----------------+------------+
优化器主要做以下两点优化:
a、当有多个所用可用的时候,选择使用哪个索引
b、在一个语句有多表关联(join)的时候,决定各个表的连接顺序,以哪个表为基准表。
例如SQL语句:select * from customer where last_name='WHITE' and address_id=18; 既可以用到索引last_name,也可以用到索引address,这时候优化器就要选择使用那一个索引,使用explain就可以查看使用了哪个索引。

上图可以看到,该sql 使用的是address的索引。
6、执行器
Mysql通过分析器知道要做什么,通过优化器知道知道该怎么做,得到一个执行计划,然后进入执行阶段,开始执行语句。
(1)开始执行的时候,先要判断一下对该表是否有查询权限,如果没有,就会返回没有权限的错误。
(2)如果有权限,就使用指定的存储引擎打开表开始查询,执行器会根据表的引擎定义,去使用这个引擎提供的查询接口,提取数据。
7、详细流程图