概述
管道聚合处理的对象是其它聚合的输出(桶或者桶的某些权值),而不是直接针对文档。
管道聚合的作用是为输出增加一些有用信息。
管道聚合大致分为两类:
parent
- 此类聚合的"输入"是其【父聚合】的输出,并对其进行进一步处理。一般不生成新的桶,而是对父聚合桶信息的增强。
sibling
- 此类聚合的输入是其【兄弟聚合】的输出。并能在同级上计算新的聚合。
管道聚合通过 buckets_path 参数指定他们要进行聚合计算的权值对象,buckets_path 参数有其自己的使用语法。
管道聚合不能包含子聚合,但是某些类型的管道聚合可以链式使用(比如计算导数的导数)。
bucket_path语法
1. 聚合分隔符 ==> ">",指定父子聚合关系,如:"my_bucket>my_stats.avg"
2. 权值分隔符 ==> ".",指定聚合的特定权值
3. 聚合名称 ==> <name of the aggregation> ,直接指定聚合的名称
4. 权值 ==> <name of the metric> ,直接指定权值
5. 完整路径 ==> agg_name[> agg_name]*[. metrics] ,综合利用上面的方式指定完整路径
6. 特殊值 ==> "_count",输入的文档个数
特殊情况
1. 要进行 pipeline aggregation 聚合的对象名称或权值名称包含小数点
- "buckets_path": "my_percentile[99.9]"
2. 处理对象中包含空桶(无文档的桶分)
- 参数 gap_policy,可选值有 skip、insert_zeros
Avg Bucket Aggregation(sibliing)
桶均值聚合——基于兄弟聚合的某个权值,求所有桶的权值均值。
用于计算的兄弟聚合必须是多桶聚合。
用于计算的权值必须是数值类型。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
{ "aggs" : { "sales_per_month" : { "date_histogram" : { "field" : "date", "interval" : "month" }, "aggs": { "sales": { "sum": { "field": "price" } } } }, "avg_monthly_sales": { "avg_bucket": { //对所有月份的销售总 sales 求平均值 "buckets_path": "sales_per_month>sales" } } } }
Derivative Aggregation(parent)
求导聚合——基于父聚合(只能是histogram或date_histogram类型)的某个权值,对权值求导。
用于求导的权值必须是数值类型。
封闭直方图(histogram)聚合的 min_doc_count 必须是 0。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
{ "aggs" : { "sales_per_month" : { "date_histogram" : { "field" : "date", "interval" : "month" }, "aggs": { "sales": { "sum": { "field": "price" } }, "sales_deriv": { //对每个月销售总和 sales 求导 "derivative": { "buckets_path": "sales" //同级,直接用 metric 值 } } } } } }
Max Bucket Aggregation(sibling)
桶最大值聚合——基于兄弟聚合的某个权值,输出权值最大的那一个桶。
用于计算的权值必须是数值类型。
用于计算的兄弟聚合必须是多桶聚合类型。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
Min Bucket Aggregation(sibling)
桶最小值聚合——基于兄弟聚合的某个权值,输出权值最小的一个桶。
用于计算的权值必须是数值类型。
用于计算的兄弟聚合必须是多桶聚合类型。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
Sum Buchet Aggregation(sibling)
桶求和聚合——基于兄弟聚合的权值,对所有桶的权值求和。
用于计算的权值必须是数值类型。
用于计算的兄弟聚合必须是多桶聚合类型。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
{ "aggs" : { "sales_per_month" : { "date_histogram" : { "field" : "date", "interval" : "month" }, "aggs": { "sales": { "sum": { "field": "price" } } } }, "max_monthly_sales": { //输出兄弟聚合 sales_per_month 的每月销售总和 sales 的最大一个桶 "max_bucket": { "buckets_path": "sales_per_month>sales" } }, "min_monthly_sales": { //输出兄弟聚合 sales_per_month 的每月销售总和 sales 的最小一个桶 "min_bucket": { "buckets_path": "sales_per_month>sales" } }, "sum_monthly_sales": { //输出兄弟聚合 sales_per_month 的每月销售总和 sales 的最小一个桶 "sum_bucket": { "buckets_path": "sales_per_month>sales" } } } }
Stats Bucket Aggregation(sibling)
桶统计信息聚合——基于兄弟聚合的某个权值,对【桶的信息】进行一些统计学运算(总计多少个桶、所有桶中该权值的最大值、最小等)。
用于计算的权值必须是数值类型。
用于计算的兄弟聚合必须是多桶聚合类型。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
{ "aggs" : { "sales_per_month" : { "date_histogram" : { "field" : "date", "interval" : "month" }, "aggs": { "sales": { "sum": { "field": "price" } } } }, "stats_monthly_sales": { // 对父聚合的每个桶(每月销售总和)的一些基本信息进行聚合 "stats_bucket": { "buckets_paths": "sales_per_month>sales" } } } } //输出结果 { "aggregations": { "sales_per_month": { "buckets": [ { "key_as_string": "2015/01/01 00:00:00", "key": 1420070400000, "doc_count": 3, "sales": { "value": 550 } }, { "key_as_string": "2015/02/01 00:00:00", "key": 1422748800000, "doc_count": 2, "sales": { "value": 60 } }, { "key_as_string": "2015/03/01 00:00:00", "key": 1425168000000, "doc_count": 2, "sales": { "value": 375 } } ] }, "stats_monthly_sales": { //注意,统计的是桶的信息 "count": 3, "min": 60, "max": 550, "avg": 328.333333333, "sum": 985 } } }
Extended Stats Bucket Aggregation(sibling)
扩展桶统计聚合——基于兄弟聚合的某个权值,对【桶信息】进行一系列统计学计算(比普通的统计聚合多了一些统计值)。
用于计算的权值必须是数值类型。
用于计算的兄弟聚合必须是多桶聚合类型。
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
- sigma:偏差显示位置(above/below)
Percentiles Bucket Aggregation(sibling)
桶百分比聚合——基于兄弟聚合的某个权值,计算权值的百分百。
用于计算的权值必须是数值类型。
用于计算的兄弟聚合必须是多桶聚合类型。
对百分百的计算是精确的(不像Percentiles Metric聚合是近似值),所以可能会消耗大量内存
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
- percents:需要计算的百分百列表(数组形式)
Moving Average Aggregation(parent)
窗口平均值聚合——基于已经排序过的数据,计算出处在当前出口中数据的平均值。
比如窗口大小为 5 ,对数据 1—10 的部分窗口平均值如下:
- (1 + 2 + 3 + 4 + 5) / 5 = 3
- (2 + 3 + 4 + 5 + 6) / 5 = 4
- (3 + 4 + 5 + 6 + 7) / 5 = 5
配置参数
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- window:窗口大小
- model:移动模型
- minimize:
- settings:
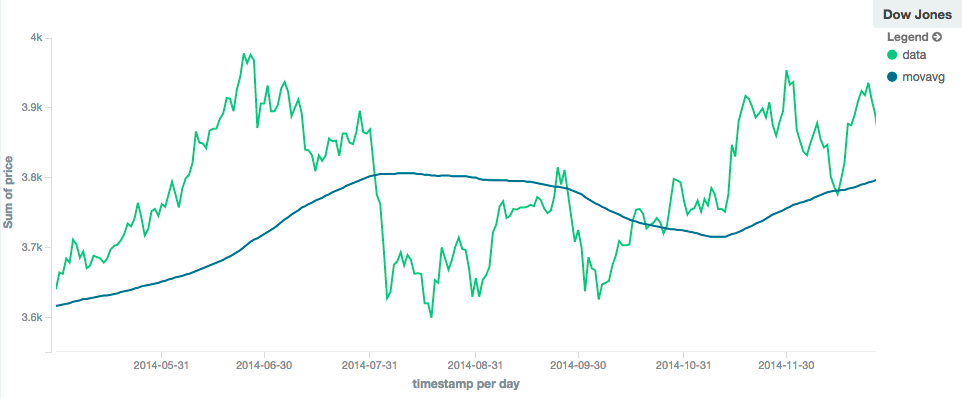
{ "the_movavg":{ "moving_avg":{ "buckets_path": "the_sum", "window" : 30, "model" : "simple" } } }
Cumulative Sum Aggregation(parent)
累计和聚合——基于父聚合(只能是histogram或date_histogram类型)的某个权值,对权值在每一个桶中求所有之前的桶的该值累计的和。
用于计算的权值必须是数值类型。
封闭直方图(histogram)聚合的 min_doc_count 必须是 0。
配置参数
- buckets_path:用于计算均值的权值路径
- format:该聚合的输出格式定义
{ "aggs" : { "sales_per_month" : { "date_histogram" : { "field" : "date", "interval" : "month" }, "aggs": { "sales": { "sum": { "field": "price" } }, "cumulative_sales": { "cumulative_sum": { "buckets_path": "sales" } } } } } } //输出 { "aggregations": { "sales_per_month": { "buckets": [ { "key_as_string": "2015/01/01 00:00:00", "key": 1420070400000, "doc_count": 3, "sales": { "value": 550 }, "cumulative_sales": { "value": 550 //总计 sales = 550 } }, { "key_as_string": "2015/02/01 00:00:00", "key": 1422748800000, "doc_count": 2, "sales": { "value": 60 }, "cumulative_sales": { "value": 610 //总计 sales = 550 + 60 } },
Bucket Script Aggregation(parent)
桶脚本聚合——基于父聚合的【一个或多个权值】,对这些权值通过脚本进行运算。
用于计算的父聚合必须是多桶聚合。
用于计算的权值必须是数值类型。
执行脚本必须要返回数值型结果。
配置参数
- script:用于计算的脚本,脚本可以是 inline,也可以是 file,还可以是 Scripting 指定的
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义
{ "aggs" : { "sales_per_month" : { "date_histogram" : { "field" : "date", "interval" : "month" }, "aggs": { "total_sales": { "sum": { "field": "price" } }, "t-shirts": { "filter": { "term": { "type": "t-shirt" } }, "aggs": { "sales": { "sum": { "field": "price" } } } }, "t-shirt-percentage": { "bucket_script": { "buckets_path": { //对两个权值进行计算 "tShirtSales": "t-shirts>sales", "totalSales": "total_sales" }, "script": "tShirtSales / totalSales * 100" } } } } } }
Bucket Selector Aggregation(parent)
桶选择器聚合——基于父聚合的【一个或多个权值】,通过脚本对权值进行计算,并决定父聚合的哪些桶需要保留,其余的将被丢弃。
用于计算的父聚合必须是多桶聚合。
用于计算的权值必须是数值类型。
运算的脚本必须是返回 boolean 类型,如果脚本是脚本表达式形式给出,那么允许返回数值类型。
配置参数
- script:用于计算的脚本,脚本可以是 inline,也可以是 file,还可以是 Scripting 指定的
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
{ "bucket_selector": { "buckets_path": { "my_var1": "the_sum", "my_var2": "the_value_count" }, "script": "my_var1 > my_var2" // true 则保留该桶;false 则丢弃 } }
Serial Differencing Aggregation(parent)
串行差分聚合——基于父聚合(只能是histogram或date_histogram类型)的某个权值,对权值值进行差分运算,(取时间间隔,后一刻的值减去前一刻的值:f(X) = f(Xt) – f(Xt-n))。
用于计算的父聚合必须是多桶聚合。
配置参数
- lag:滞后间隔(比如lag=7,表示每次从当前桶的值中减去其前面第7个桶的值)
- buckets_path:用于计算均值的权值路径
- gap_policy:空桶处理策略(skip/insert_zeros)
- format:该聚合的输出格式定义

{ "aggs": { "my_date_histo": { "date_histogram": { "field": "timestamp", "interval": "day" }, "aggs": { "the_sum": { "sum": { "field": "lemmings" } }, "thirtieth_difference": { "serial_diff": { "buckets_path": "the_sum", "lag" : 30 //差分间隔为 30 day } } } } } }