sleuth主要功能是在分布式系统中提供追踪解决方案,并且兼容支持了zipkin(提供了链路追踪的可视化功能)
zipkin原理:在服务调用的请求和响应中加入ID,表明上下游请求的关系。
利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
sleuth是对zipkin的封装,对应Span,Trace等信息的生成、接入http request,以及向Zipkin server发送采集信息等全部自动化完成。
目前主流的链路追踪组件有:google的Dapper,Twitter的zipkin和阿里的Eagleeye(鹰眼)。
1. 搭建zipkin服务器
1.1 创建springboot项目,引入相应的jar依赖(其他依赖参考前面的教材)
<!-- 引入zipkin-server --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency>
<!-- 引入zipkin-server 图形化界面 --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> </dependency>
1.2 添加配置文件
server:
port: 8769
spring:
application:
name: zipkin-server
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/ #注册服务器地址
management:
security:
enabled: false #关闭验证
info: #/info请求的显示信息
app:
name: ${spring.application.name}
version: 1.0.0
build:
artifactId: @project.artifactId@
version: @project.version@
1.3 在启动类中声明为zipkin服务器
@SpringBootApplication @EnableDiscoveryClient @EnableZipkinServer //zipkin服务器 默认使用http进行通信 public class ZipkinServerApp { public static void main(String[] args) { SpringApplication.run(ZipkinServerApp.class, args); } }
1.4 启动查看效果

2 分别在cloud-consumer-ribbon和cloud-consumer-feign中引入zipkin
2.1 引入zipkin依赖
<!-- 配置服务链路追踪 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
或
<!-- 配置服务链路追踪 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
2.2 在配置文件中声明zipkin服务器的地址
spring:
zipkin:
base-url: http://localhost:8769
2.3 在项目中调用需要的服务
@RequestMapping("hello")
public String helloConsumer() {
//使用restTemplate调用消费服务提供者的SERVICE-HI的info服务
//String response=restTemplate.getForObject("http://cloud-consumer-feign/hi", String.class);
String response=hiService.sayHello()+" ribbon";
logger.info(response);
return response;
}
2.4 启动项目查看

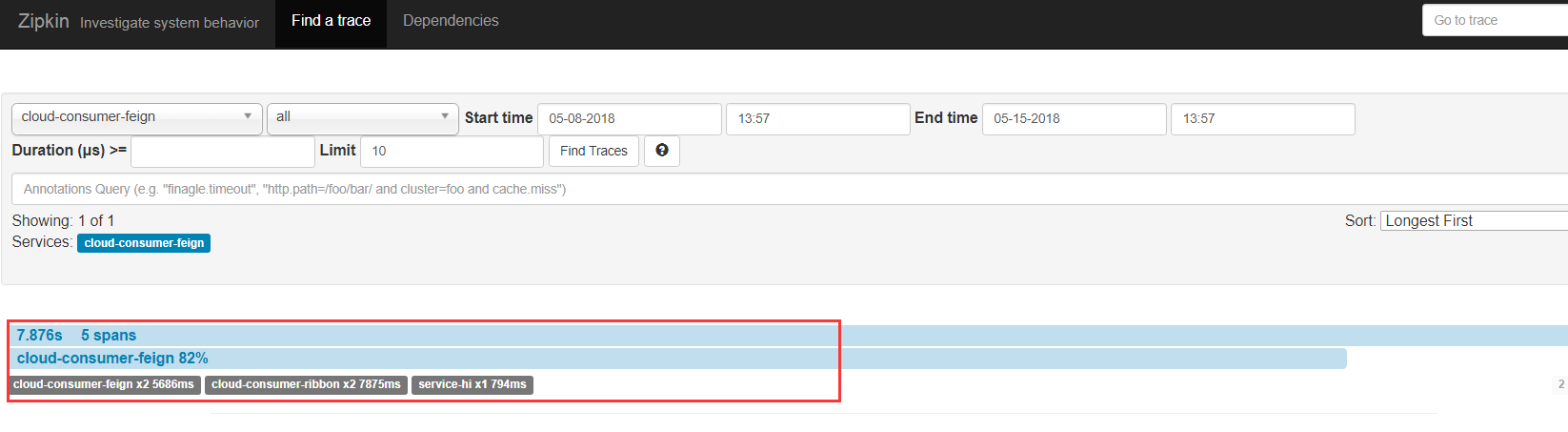
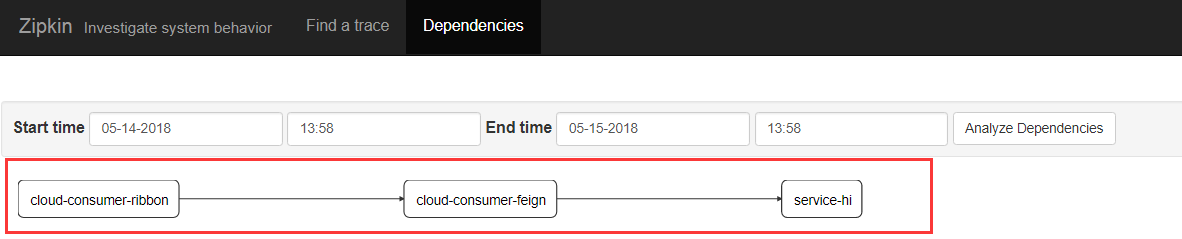
有时候可能在zipkin服务器中看不到数据,那是因为默认sleuth收集信息的比率是0.1 ,针对于这个问题有两种解决方法:
a 在配置文件中配置 spring.sleuth.sampler.percentage=1
b 在代码中声明
//100%的来采集日志,和在配置文件中配置spring.sleuth.sampler.percentage=1是一样的 @Bean public AlwaysSampler defaultSampler(){ return new AlwaysSampler(); }
但这样每个请求都会向zipkin server发送http请求,通信效率低,造成网络延迟。
而且所用的追踪信息都在内存中保存,重启zipkin server后信息丢失
针对以上的问题的解决方法:
a 采用socket或高效率的通信方式
b 采用异步方式发送信息数据
c 在客户端和zipkin之间增加缓存类的中间件,如redis,mq等,即时zipkin server重启过程中,客户端依然可以将数据发送成功
3 将http通信改为mq异步通信方式
3.1 修改zipkin server
3.1.1 将原来的依赖io.zipkin.java:zipkin-server换成spring-cloud-sleuth-zipkin-stream和spring-cloud-starter-stream-rabbit
<!-- 引入zipkin-server --> <!-- <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency> --> <!-- 将http请求修改为mq请求 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> </dependency>
3.1.2 在配置文件中配置ribbitmq地址
spring:
application:
name: zipkin-server
rabbitmq: #配置mq消息队列
host: localhost
port: 5672
username: guest
password: guest
3.1.3 在启动类中使用@EnableZipkinStreamServer替换@EnableZipkinServer
@SpringBootApplication @EnableDiscoveryClient //@EnableZipkinServer //zipkin服务器 默认使用http进行通信 @EnableZipkinStreamServer //采用stream方式启动zipkin server ,也支持http通信 包含了@EnableZipkinServer,同时创建了rabbit-mq消息队列监听器 public class ZipkinServerApp { public static void main(String[] args) { SpringApplication.run(ZipkinServerApp.class, args); } }
3.2 配置客户端(这里只配置一个客户端,其他的客户端配置一样配置即可)
3.2.1 将原来的spring-cloud-starter-zipkin依赖,使用以下依赖进行替换
<!-- 配置服务链路追踪 --> <!-- <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
3.2.2 在配置文件中加入ribbitmq的配置
spring:
rabbitmq: #配置mq消息队列
host: localhost
port: 5672
username: guest
password: guest
3.3 现在启动其他项目,不启动zipkin server,进行项目访问,会把追踪信息放入到ribbitmq中,当zipkin server启动后会直接冲zipkin server中获取信息
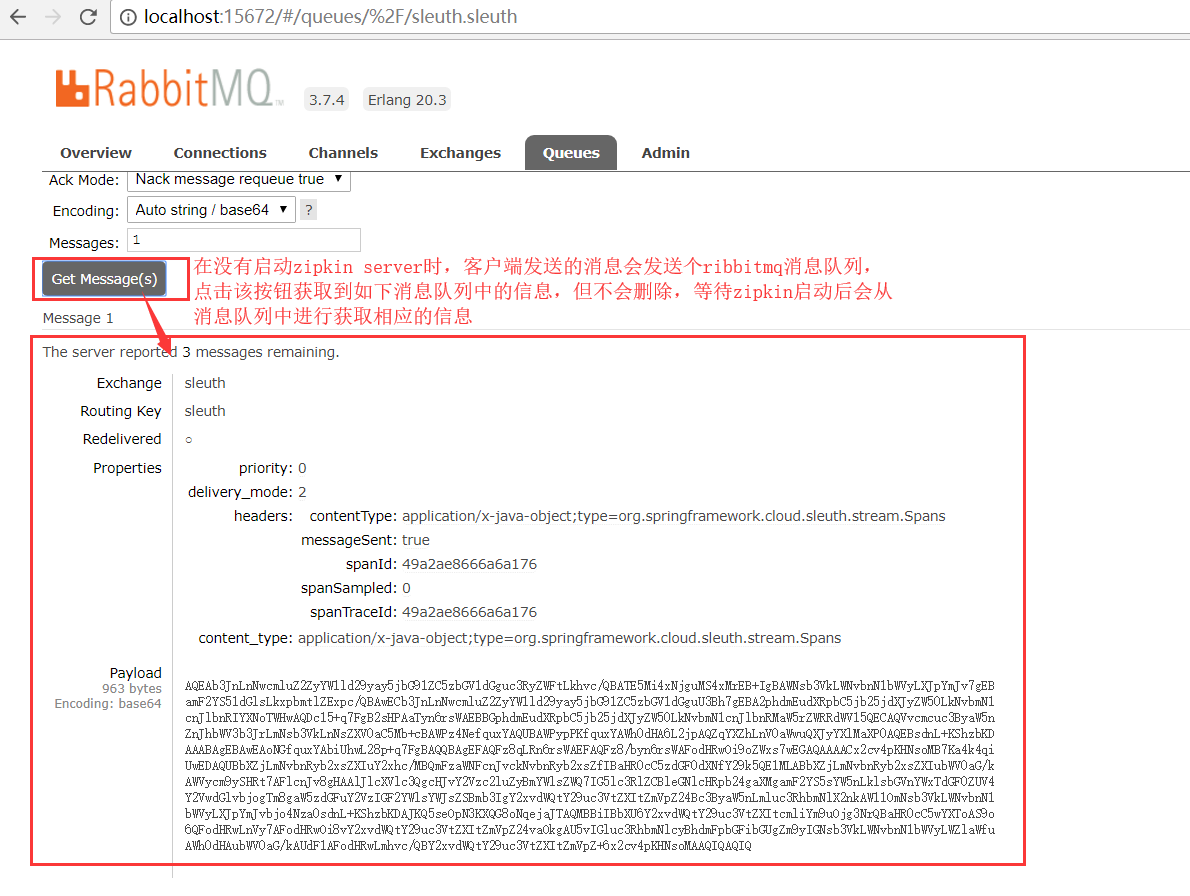

4 将追踪信息保存到数据库(只需修改zipkin server即可)
4.1 引入mysql数据库依赖
<!-- 配置mysql --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency>
4.2 在配置文件msql连接
spring: sleuth: enabled: false #表示当前程序不使用sleuth datasource: #配置msyql 连接 schema[0]: classpath:/zipkin.sql #数据库创建脚本,可以到官网下载 url: jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false username: root password: root driver-class-name: com.mysql.jdbc.Driver initialize: true continue-on-error: true zipkin: storage: type: mysql #mysql存储zipkin追踪信息
4.3 创建数据库和表
CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);