Gunicorn
https://docs.gunicorn.org/en/latest/index.html
https://github.com/benoitc/gunicorn
Gunicorn ‘Green Unicorn’ is a Python WSGI HTTP Server for UNIX. It’s a pre-fork worker model ported from Ruby’s Unicorn project. The Gunicorn server is broadly compatible with various web frameworks, simply implemented, light on server resources, and fairly speedy.
Unicorn
https://mythsandlegends.fandom.com/wiki/Unicorn
奇幻 和 稀有 的符号。
In European folklore, the unicorn is often depicted as a white horse-like or goat-like animal with a long horn, cloven hooves, and sometimes a goat's beard. In the Middle Ages and Renaissance, it was commonly described as an extremely wild woodland creature, a symbol of purity and grace, which could be captured only by a virgin. In the encyclopedias, its horn was said to have the power to render poisoned water potable and to heal sickness. In medieval and Renaissance times, the tusk of the narwhal was sometimes sold as unicorn horn.
The unicorn continues to hold a place in popular culture. It is often used as a symbol of fantasy or rarity.
Why is Gunicorn important?
https://www.fullstackpython.com/green-unicorn-gunicorn.html#:~:text=What%27s%20a%20%22pre-fork%22%20worker%20model%3F%20Gunicorn%20is%20based,handling.%20Each%20worker%20is%20independent%20of%20the%20controller.
WSGI 服务器实现, 特别重要,因为其稳定, 通常用在web应用部署。 Instagram就是使用这个。
任何符合WSGI接口的框架,都支持在此服务器上部署。
Gunicorn is one of many WSGI server implementations, but it's particularly important because it is a stable, commonly-used part of web app deployments that's powered some of the largest Python-powered web applications in the world, such as Instagram.
Gunicorn implements the PEP3333 WSGI server standard specification so that it can run Python web applications that implement the application interface. For example, if you write a web application with a web framework such as Django, Flask or Bottle, then your application implements the WSGI specification.
What's a "pre-fork" worker model?
https://www.fullstackpython.com/green-unicorn-gunicorn.html#:~:text=What%27s%20a%20%22pre-fork%22%20worker%20model%3F%20Gunicorn%20is%20based,handling.%20Each%20worker%20is%20independent%20of%20the%20controller.
Gunicorn is based on a pre-fork worker model, compared to a worker model architecture. The pre-work worker model means that a master thread spins up workers to handle requests but otherwise does not control how those workers perform the request handling. Each worker is independent of the controller.
https://docs.gunicorn.org/en/latest/design.html
Gunicorn is based on the pre-fork worker model. This means that there is a central master process that manages a set of worker processes. The master never knows anything about individual clients. All requests and responses are handled completely by worker processes.
Better performance by optimizing Gunicorn config
https://medium.com/building-the-system/gunicorn-3-means-of-concurrency-efbb547674b7
TL;DR, For CPU bounded apps increase workers and/or cores. For I/O bounded apps use “pseudo-threads”.
Gunicorn is a Python WSGI HTTP Server that usually lives between a reverse proxy (e.g., Nginx) or load balancer (e.g., AWS ELB) and a web application such as Django or Flask.
Gunicorn architecture
Gunicorn implements a UNIX pre-fork web server.
Great, what does that mean?
- Gunicorn starts a single master process that gets forked, and the resulting child processes are the workers.
- The role of the master process is to make sure that the number of workers is the same as the ones defined in the settings. So if any of the workers die, the master process starts another one, by forking itself again.
- The role of the workers is to handle HTTP requests.
- The pre in pre-forked means that the master process creates the workers before handling any HTTP request.
- The OS kernel handles load balancing between worker processes.
To improve performance when using Gunicorn we have to keep in mind 3 means of concurrency.
1st means of concurrency (workers, aka UNIX processes)
Each of the workers is a UNIX process that loads the Python application. There is no shared memory between the workers.
The suggested number of
workersis(2*CPU)+1.For a dual-core (2 CPU) machine, 5 is the suggested
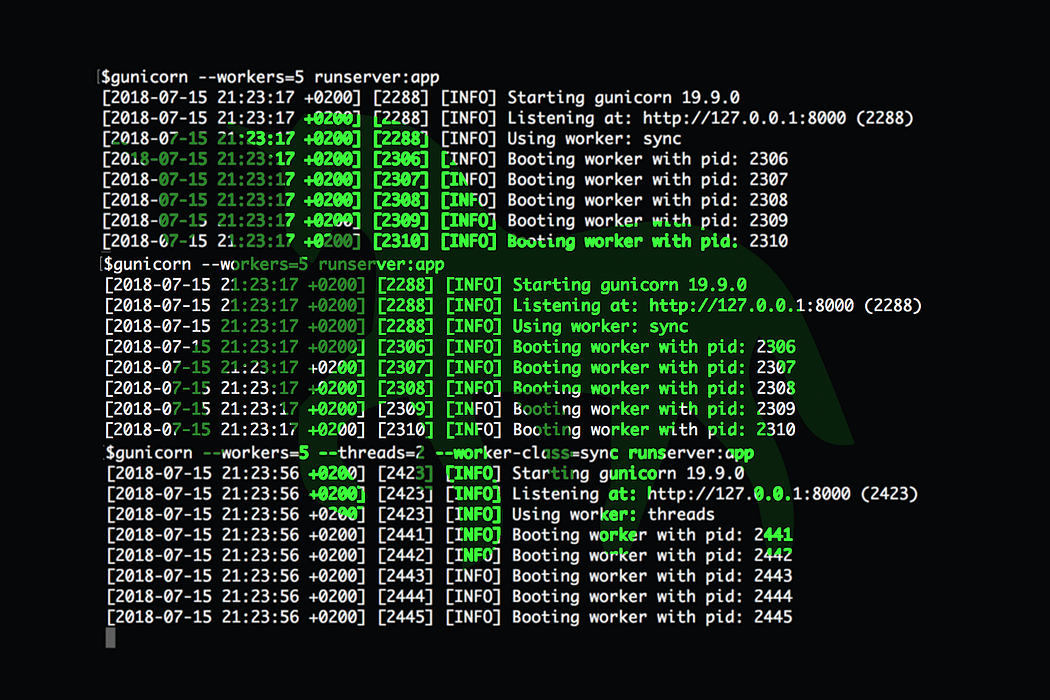
workersvalue.gunicorn --workers=5 main:appGunicorn with default worker class (sync). Note the 4th line in the image: “Using worker: sync”.
2nd means of concurrency (threads)
Gunicorn also allows for each of the workers to have multiple threads. In this case, the Python application is loaded once per worker, and each of the threads spawned by the same worker shares the same memory space.
To use threads with Gunicorn, we use the
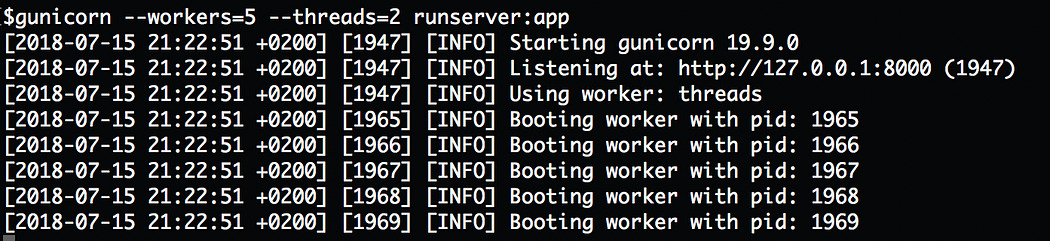
threadssetting. Every time that we usethreads, the worker class is set togthread:gunicorn --workers=5 --threads=2 main:appGunicorn with threads setting, which uses the gthread worker class. Note the 4th line in the image: “Using worker: threads”.
The previous command is the same as:
gunicorn --workers=5 --threads=2 --worker-class=gthread main:appThe maximum concurrent requests are
workers * threads10 in our case.The suggested maximum concurrent requests when using workers and threads is still
(2*CPU)+1.So if we are using a quad-core (4 CPU) machine and we want to use a mix of workers and threads, we could use 3 workers and 3 threads, to get 9 maximum concurrent requests.
gunicorn --workers=3 --threads=3 main:app3rd means of concurrency (“pseudo-threads” )
There are some Python libraries such as gevent and Asyncio that enable concurrency in Python by using “pseudo-threads” implemented with coroutines.
Gunicorn allows for the usage of these asynchronous Python libraries by setting their corresponding worker class.
Here the settings that would work for a single core machine that we want to run using
gevent:gunicorn --worker-class=gevent --worker-connections=1000 --workers=3 main:appworker-connections is a specific setting for the gevent worker class.
(2*CPU)+1is still the suggestedworkerssince we only have 1 core, we’ll be using 3 workers.In this case, the maximum number of concurrent requests is 3000 (3 workers * 1000 connections per worker)
Concurrency vs. Parallelism
- Concurrency is when 2 or more tasks are being performed at the same time, which might mean that only 1 of them is being worked on while the other ones are paused.
- Parallelism is when 2 or more tasks are executing at the same time.
In Python, threads and pseudo-threads are a means of concurrency, but not parallelism; while workers are a means of both concurrency and parallelism.
That’s all good theory, but what should I use in my program?
Practical use cases
By tuning Gunicorn settings we want to optimize the application performance.
- If the application is I/O bounded, the best performance usually comes from using “pseudo-threads” (gevent or asyncio). As we have seen, Gunicorn supports this programming paradigm by setting the appropriate worker class and adjusting the value of
workersto(2*CPU)+1.- If the application is CPU bounded, it doesn’t matter how many concurrent requests are handled by the application. The only thing that matters is the number of parallel requests. Due to Python’s GIL, threads and “pseudo-threads” cannot run in parallel. The only way to achieve parallelism is to increase
workersto the suggested(2*CPU)+1, understanding that the maximum number of parallel requests is the number of cores.- If there is a concern about the application memory footprint, using
threadsand its corresponding gthread worker class in favor ofworkersyields better performance because the application is loaded once per worker and every thread running on the worker shares some memory, this comes to the expense of some additional CPU consumption.- If you don’t know you are doing, start with the simplest configuration, which is only setting
workersto(2*CPU)+1and don’t worry aboutthreads. From that point, it’s all trial and error with benchmarking. If the bottleneck is memory, start introducing threads. If the bottleneck is I/O, consider a different python programming paradigm. If the bottleneck is CPU, consider using more cores and adjusting theworkersvalue.Building the system
We, software developers commonly think that every performance bottleneck can be fixed by optimizing the application code, and this is not always true.
There are times in which tuning the settings of the HTTP server, using more resources or re-architecting the application to use a different programming paradigm are the solutions that we need to improve the overall application performance.
In this case, building the system means understanding the types of computing resources (processes, threads and “pseudo-threads”) that we have available to deploy a performant application.
By understanding, architecting and implementing the right technical solution with the right resources we avoid falling into the trap of trying to improve performance by optimizing application code.

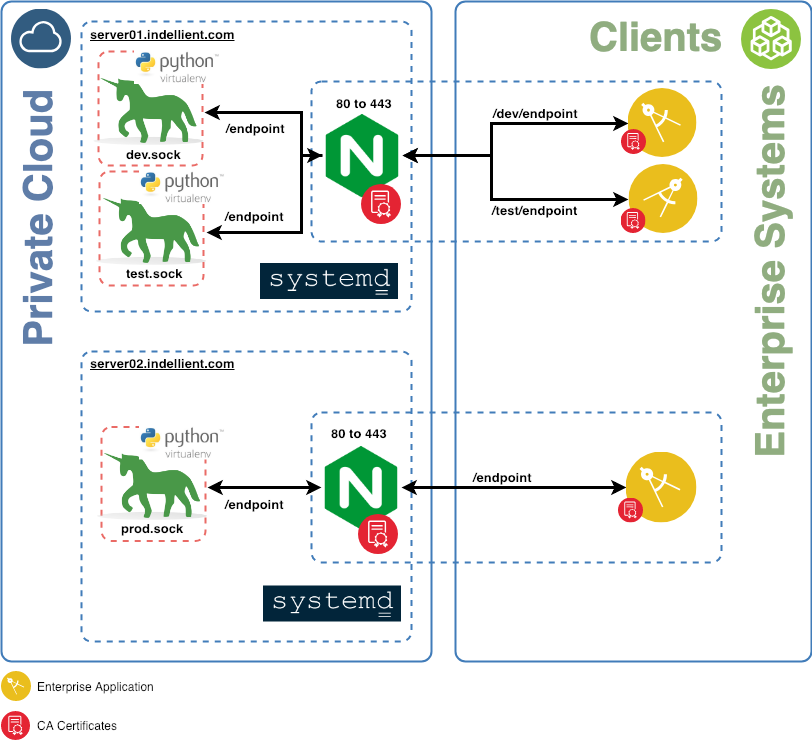
典型业务
https://itnext.io/how-to-deploy-gunicorn-behind-nginx-in-a-shared-instance-f336d2ba4519